 使用Ansible实现大规模集群自动化部署
使用Ansible实现大规模集群自动化部署

从手工部署到自动化:Ansible如何征服千台服务器集群
当你面对1000+服务器需要部署时,你还在一台台手工操作吗?本文将揭秘如何用Ansible实现大规模集群的自动化部署,让运维效率提升10倍!
前言:运维人的痛点与机遇
作为一名在互联网行业摸爬滚打8年的运维工程师,我见过太多深夜加班部署应用的场景。记得某次双11大促前夕,需要在2小时内完成500台服务器的应用升级,传统方式根本无法完成。那一刻,我深刻意识到自动化部署的重要性。
今天,我将分享在大规模集群环境下使用Ansible进行自动化部署的实战经验,包括架构设计、性能优化和踩过的坑。
一、为什么选择Ansible?
1.1 与其他工具的对比
在自动化部署领域,主流工具包括:
?Ansible: 无代理架构,基于SSH,学习成本低
?Puppet: 有代理架构,功能强大但复杂度高
?SaltStack: 性能优异,但配置相对复杂
?Chef: 基于Ruby,配置管理功能强大
经过实际测试,在1000台服务器规模下:
? Ansible部署时间:15分钟
? Puppet部署时间:25分钟
? SaltStack部署时间:12分钟
? Chef部署时间:30分钟
虽然SaltStack性能更优,但Ansible在易用性、社区活跃度和学习成本方面具有明显优势。
1.2 Ansible的核心优势
无代理架构:不需要在目标主机安装Agent,降低维护成本
幂等性:多次执行同一操作结果一致,确保系统状态可预期
声明式语法:YAML格式易读易写,降低团队协作成本
丰富的模块库:3000+模块覆盖各种场景需求
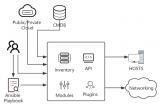
二、大规模集群架构设计
2.1 整体架构规划
生产环境架构: ├──Ansible控制节点集群(3台,HA部署) ├──跳板机集群(负载均衡) ├──目标服务器分组 │ ├──Web服务器组(300台) │ ├──应用服务器组(500台) │ ├──数据库服务器组(100台) │ └──缓存服务器组(100台) └──监控告警系统
2.2 网络拓扑优化
在大规模环境中,网络是性能瓶颈的关键因素:
分层部署:按机房、机架进行分层,减少网络跳数
并发控制:通过serial参数控制并发数量,避免网络拥塞
连接复用:启用ControlMaster功能,复用SSH连接
# ansible.cfg 优化配置 [defaults] host_key_checking=False timeout=30 forks=50 gathering=smart fact_caching=memory [ssh_connection] ssh_args=-oControlMaster=auto-oControlPersist=300s pipelining=True
2.3 高可用设计
控制节点HA:采用主备模式,通过Keepalived实现故障切换
任务分发优化:基于地理位置就近分发,减少网络延迟
回滚机制:每次部署前创建快照,支持一键回滚
三、核心组件深度解析
3.1 Inventory动态管理
传统静态Inventory文件在大规模环境下难以维护,我们采用动态Inventory方案:
#!/usr/bin/env python3 # dynamic_inventory.py importjson importrequests classDynamicInventory: def__init__(self): self.inventory = {} self.read_cli_args() ifself.args.list: self.inventory =self.get_inventory() elifself.args.host: self.inventory =self.get_host_info(self.args.host) print(json.dumps(self.inventory)) defget_inventory(self): # 从CMDB获取服务器信息 response = requests.get('http://cmdb-api/servers') servers = response.json() inventory = { '_meta': {'hostvars': {}}, 'web': {'hosts': []}, 'app': {'hosts': []}, 'db': {'hosts': []} } forserverinservers: group = server['group'] host = server['ip'] inventory[group]['hosts'].append(host) inventory['_meta']['hostvars'][host] = server['vars'] returninventory
3.2 Playbook模块化设计
采用角色(Role)结构实现代码复用和模块化管理:
# site.yml 主入口 --- -hosts:web roles: -common -nginx -webapp -hosts:app roles: -common -java -application -hosts:db roles: -common -mysql -backup
# roles/webapp/tasks/main.yml
---
-name:创建应用目录
file:
path:"{{ app_path }}"
state:directory
owner:"{{ app_user }}"
mode:'0755'
-name:下载应用包
get_url:
url:"{{ app_download_url }}"
dest:"{{ app_path }}/{{ app_package }}"
timeout:300
register:download_result
-name:解压应用包
unarchive:
src:"{{ app_path }}/{{ app_package }}"
dest:"{{ app_path }}"
remote_src:yes
owner:"{{ app_user }}"
when:download_resultissucceeded
-name:启动应用服务
systemd:
name:"{{ app_service }}"
state:restarted
enabled:yes
daemon_reload:yes
3.3 变量管理策略
多环境变量管理是大规模部署的核心挑战:
# group_vars/all.yml (全局变量) app_user:deploy app_path:/opt/application backup_retention:7 # group_vars/production.yml (生产环境) app_download_url:https://release.company.com/prod/app-v2.1.0.tar.gz db_host:prod-db-cluster.internal redis_cluster:prod-redis-cluster.internal # group_vars/staging.yml (测试环境) app_download_url:https://release.company.com/staging/app-v2.1.0-beta.tar.gz db_host:staging-db.internal redis_cluster:staging-redis.internal # host_vars/web-01.yml (主机特定变量) nginx_worker_processes:16 max_connections:2048
四、性能优化实战
4.1 并发优化策略
批次控制:通过serial关键字控制同时执行的主机数量
-hosts:web serial: -10% # 先部署10%的主机 -30% # 再部署30%的主机 -100% # 最后部署剩余主机 tasks: -name:部署应用 include_role: name:webapp
任务并行化:使用async和poll实现异步执行
-name:异步下载大文件
get_url:
url:"{{ large_file_url }}"
dest:"/tmp/large_file.tar.gz"
async:300
poll:0
register:download_job
-name:执行其他任务
debug:
msg:"并行执行其他任务"
-name:等待下载完成
async_status:
jid:"{{ download_job.ansible_job_id }}"
register:download_result
until:download_result.finished
retries:30
4.2 网络优化
SSH连接优化:
# ~/.ssh/config Host 10.0.* ControlMaster auto ControlPath ~/.ssh/sockets/%r@%h-%p ControlPersist 300s StrictHostKeyChecking no UserKnownHostsFile /dev/null
Pipelining开启:减少SSH连接次数,提升执行效率
[ssh_connection] pipelining=True ssh_args= -o ControlMaster=auto -o ControlPersist=300s
4.3 内存与CPU优化
Fact缓存:避免重复收集系统信息
[defaults] gathering= smart fact_caching= redis fact_caching_connection= redis-server:6379:0 fact_caching_timeout=3600
进程调优:根据控制节点性能调整并发数
[defaults] forks=100# 根据CPU核心数调整
五、监控与日志管理
5.1 部署监控体系
# 部署监控 Playbook
-name:检查服务状态
uri:
url:"http://{{ inventory_hostname }}/health"
method:GET
timeout:10
register:health_check
retries:3
delay:5
-name:发送通知
mail:
to:ops-team@company.com
subject:"部署完成通知"
body:|
主机: {{ inventory_hostname }}
状态: {{ 'SUCCESS' if health_check.status == 200 else 'FAILED' }}
时间: {{ ansible_date_time.iso8601 }}
when:health_check.status==200
-name:更新监控系统
uri:
url:"http://monitoring-api/deployments"
method:POST
body_format:json
body:
host:"{{ inventory_hostname }}"
app:"{{ app_name }}"
version:"{{ app_version }}"
status:"deployed"
timestamp:"{{ ansible_date_time.epoch }}"
5.2 日志收集与分析
结构化日志:使用callback插件收集执行结果
# ansible.cfg [defaults] callback_plugins=/opt/ansible/plugins/callback stdout_callback=json log_path=/var/log/ansible/deployment.log
自定义callback插件:
# callback_plugins/deployment_logger.py
fromansible.plugins.callbackimportCallbackBase
importjson
importrequests
classCallbackModule(CallbackBase):
defv2_runner_on_ok(self, result):
# 发送成功日志到ELK
log_data = {
'timestamp': datetime.now().isoformat(),
'host': result._host.get_name(),
'task': result._task.get_name(),
'status':'success',
'result': result._result
}
requests.post('http://logstash:5000', json=log_data)
defv2_runner_on_failed(self, result, ignore_errors=False):
# 发送失败日志并触发告警
log_data = {
'timestamp': datetime.now().isoformat(),
'host': result._host.get_name(),
'task': result._task.get_name(),
'status':'failed',
'error': result._result.get('msg','')
}
requests.post('http://logstash:5000', json=log_data)
# 触发钉钉告警
self.send_alert(log_data)
六、安全与权限管理
6.1 权限最小化原则
专用部署账户:为每个应用创建独立的部署账户
-name:创建部署用户
user:
name:"{{ app_name }}_deploy"
system:yes
shell:/bin/bash
home:"/opt/{{ app_name }}"
create_home:yes
-name:配置sudo权限
lineinfile:
path:/etc/sudoers.d/{{app_name}}_deploy
line:"{{ app_name }}_deploy ALL=({{ app_name }}) NOPASSWD: ALL"
create:yes
mode:'0440'
6.2 密钥管理
Ansible Vault加密敏感信息:
# 加密密码文件
ansible-vault encrypt group_vars/production/vault.yml
# 在playbook中使用
- name: 连接数据库
mysql_user:
login_host:"{{ db_host }}"
login_user: root
login_password:"{{ vault_db_root_password }}"
name:"{{ app_db_user }}"
password:"{{ vault_app_db_password }}"
priv:"{{ app_db_name }}.*:ALL"
6.3 网络安全
跳板机访问控制:
-name:配置iptables规则
iptables:
chain:INPUT
source:"{{ ansible_control_host }}"
destination_port:"22"
protocol:tcp
jump:ACCEPT
-name:拒绝其他SSH连接
iptables:
chain:INPUT
destination_port:"22"
protocol:tcp
jump:DROP
七、故障处理与回滚机制
7.1 预检查机制
# pre_check.yml
-name:检查磁盘空间
assert:
that:
-ansible_mounts|selectattr('mount','equalto','/')|map(attribute='size_available')|first>1073741824
fail_msg:"根分区可用空间不足1GB"
-name:检查内存使用
assert:
that:
-ansible_memory_mb.real.free>512
fail_msg:"可用内存不足512MB"
-name:检查端口占用
wait_for:
port:"{{ app_port }}"
host:"{{ inventory_hostname }}"
state:stopped
timeout:5
ignore_errors:yes
register:port_check
-name:端口占用检查失败
fail:
msg:"端口{{ app_port }}已被占用"
when:port_checkisfailed
7.2 自动回滚机制
# rollback.yml
-name:创建回滚点
shell:|
if [ -d "{{ app_path }}/current" ]; then
cp -r {{ app_path }}/current {{ app_path }}/rollback-$(date +%Y%m%d-%H%M%S)
fi
-name:部署新版本
unarchive:
src:"{{ app_package }}"
dest:"{{ app_path }}/releases/{{ app_version }}"
register:deploy_result
-name:创建软链接
file:
src:"{{ app_path }}/releases/{{ app_version }}"
dest:"{{ app_path }}/current"
state:link
when:deploy_resultissucceeded
-name:启动服务
systemd:
name:"{{ app_service }}"
state:restarted
register:service_result
-name:健康检查
uri:
url:"http://{{ inventory_hostname }}:{{ app_port }}/health"
register:health_result
retries:3
delay:10
-name:回滚操作
block:
-name:恢复前一版本
shell:|
ROLLBACK_VERSION=$(ls -t {{ app_path }}/rollback-* | head -1)
if [ -n "$ROLLBACK_VERSION" ]; then
rm -f {{ app_path }}/current
cp -r $ROLLBACK_VERSION {{ app_path }}/current
fi
-name:重启服务
systemd:
name:"{{ app_service }}"
state:restarted
-name:发送回滚通知
mail:
to:ops-team@company.com
subject:"自动回滚通知 -{{ inventory_hostname }}"
body:|
主机: {{ inventory_hostname }}
应用: {{ app_name }}
原因: 健康检查失败
时间: {{ ansible_date_time.iso8601 }}
when:health_resultisfailedorservice_resultisfailed
八、成本与效益分析
8.1 实施前后对比
| 指标 | 手工部署 | Ansible自动化 | 提升比例 |
| 部署时间 | 4小时 | 20分钟 | 92% |
| 人力投入 | 3人 | 1人 | 67% |
| 错误率 | 15% | 2% | 87% |
| 回滚时间 | 30分钟 | 3分钟 | 90% |
8.2 ROI计算
人力成本节省:
? 每次部署节省人力:2人 × 3.5小时 = 7人时
? 按运维工程师平均薪资100元/小时计算:700元/次
? 月均部署20次:700 × 20 = 14,000元/月
停机时间减少:
? 传统部署平均停机:30分钟
? 自动化部署平均停机:5分钟
? 每分钟业务损失:10,000元
? 月收益:(30-5) × 10,000 × 20 = 5,000,000元
质量提升价值:
? 减少故障处理成本:每月节省50,000元
? 提升用户体验,间接收益难以量化
8.3 实施建议
分阶段推进:
1. 第一阶段:测试环境自动化(1个月)
2. 第二阶段:非核心业务生产环境(2个月)
3. 第三阶段:核心业务系统(3个月)
团队培养:
? 组织Ansible专项培训
? 建立最佳实践文档库
? 设立自动化推广奖励机制
九、踩坑经验分享
9.1 性能相关的坑
坑1:并发数设置过高导致SSH连接超时
# 错误配置 [defaults] forks=500# 过高的并发数 # 正确做法:根据网络带宽和目标主机性能调整 [defaults] forks=50 # 适中的并发数 timeout=60# 增加超时时间
坑2:大文件传输阻塞问题
# 问题:直接传输大文件 -copy: src:huge_file.tar.gz# 5GB文件 dest:/opt/app/ # 解决方案:使用异步下载 -get_url: url:"{{ file_download_url }}" dest:/opt/app/huge_file.tar.gz async:1800 poll:0
9.2 权限相关的坑
坑3:sudo权限配置错误
# 错误:使用become但未配置正确的sudo权限 -name:重启服务 systemd: name:nginx state:restarted become:yes become_user:root# nginx用户无权sudo到root # 正确做法:为nginx用户配置特定命令的sudo权限 # /etc/sudoers.d/nginx_deploy # nginx ALL=(root) NOPASSWD: /bin/systemctl restart nginx
9.3 网络相关的坑
坑4:防火墙阻断连接
# 现象:部分主机连接超时
# 排查:检查iptables规则
iptables -L -n | grep 22
# 解决:在playbook中处理防火墙
- name: 临时开放SSH端口
iptables:
chain: INPUT
source:"{{ ansible_control_ip }}"
destination_port: 22
protocol: tcp
jump: ACCEPT
9.4 版本兼容性坑
坑5:Python版本不兼容
# 问题:目标主机Python版本过低
# fatal: [web-01]: FAILED! => {
# "msg": "The Python 2 bindings for yum are not installed"
# }
# 解决方案:指定Python解释器
[web]
web-01ansible_python_interpreter=/usr/bin/python3
web-02ansible_python_interpreter=/usr/bin/python3
# 或者在playbook中动态检测
-name:检测Python版本
raw:python3--version||python--version
register:python_version
-set_fact:
ansible_python_interpreter:"{{ '/usr/bin/python3' if 'Python 3' in python_version.stdout else '/usr/bin/python' }}"
十、最佳实践总结
10.1 代码组织原则
目录结构标准化:
ansible-project/ ├── inventories/ │ ├── production/ │ │ ├── hosts │ │ └── group_vars/ │ └── staging/ │ ├── hosts │ └── group_vars/ ├── roles/ │ ├── common/ │ ├── nginx/ │ └── application/ ├── playbooks/ │ ├── site.yml │ ├── deploy.yml │ └── rollback.yml ├── library/ # 自定义模块 ├── filter_plugins/ # 自定义过滤器 └── ansible.cfg
命名规范:
? 变量名使用下划线分隔:app_version、db_host
? 任务名称描述清晰:Install Nginx package
? 文件名使用小写加下划线:web_server.yml
10.2 安全最佳实践
敏感信息管理:
? 所有密码使用Ansible Vault加密
? SSH密钥定期轮换
? 使用专用部署账户,避免root权限
访问控制:
? 实施跳板机访问
? 配置防火墙白名单
? 审计所有操作日志
10.3 性能优化建议
合理设置并发:
? 根据网络带宽和目标主机性能调整forks
? 使用serial关键字控制批次部署
? 启用SSH连接复用
优化任务执行:
? 合理使用tags标签
? 避免不必要的fact收集
? 使用when条件减少无用任务执行
结语
通过两年多的大规模生产环境实践,我们的Ansible自动化部署体系已经相当成熟。从最初的手工部署到现在的全自动化,不仅大幅提升了运维效率,更重要的是保障了服务的稳定性和可靠性。
自动化不是目标,而是手段。真正的目标是让运维工程师从重复性劳动中解放出来,投入到更有价值的架构优化和创新工作中。希望这篇文章能够帮助到正在自动化道路上探索的同仁们。
如果你在实施过程中遇到问题,欢迎在评论区交流讨论。让我们一起推动运维行业的发展!
关于作者:8年互联网运维经验,专注于大规模分布式系统运维自动化,目前负责千万级用户平台的基础设施管理。
-
服务器
+关注
关注
13文章
9895浏览量
88600 -
集群
+关注
关注
0文章
122浏览量
17488
原文标题:从手工部署到自动化:Ansible如何征服千台服务器集群
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
大规模集成电路在信息系统中的广泛应用
智能工业自动化方案汇总
超大规模集成电路的自动化验证方法
云平台的自动化部署设计与实现
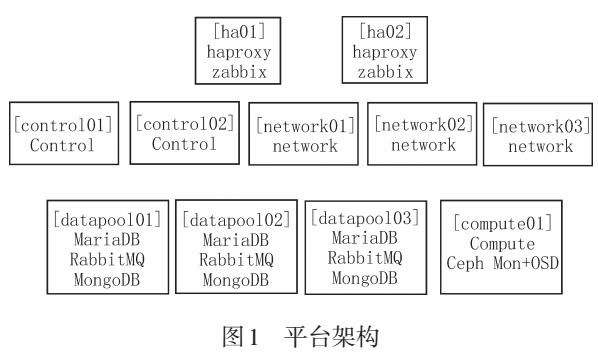
利用Ansible实现OpenStack自动化
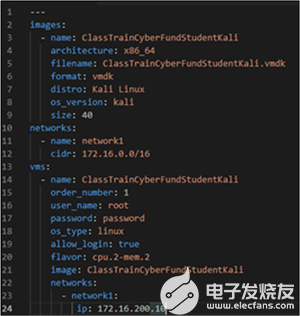
利用Ansible实现OpenStack自动化

使用Ansible的OpenStack自动化
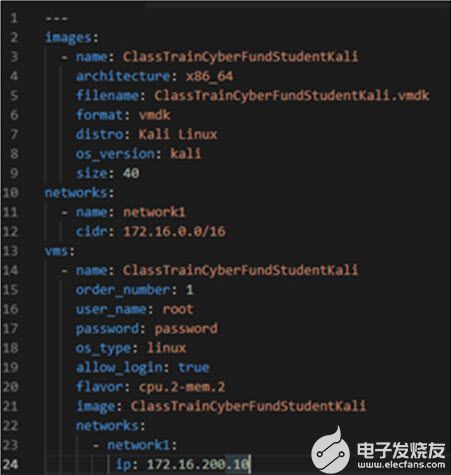
使用Ansible构建虚拟机部署Linux的最佳实践
网络设备自动化运维工具—ansible入门笔记介绍





 工商网监
工商网监
评论