 免费GPU哪家强?谷歌Kaggle vs和Colab
免费GPU哪家强?谷歌Kaggle vs和Colab

谷歌有两个平台提供免费的云端GPU:Colab和Kaggle, 如果你想深入学习人工智能和深度学习技术,那么这两款GPU将带给你很棒学习的体验。那么问题来了,我们该选择哪个平台进行学习和工作呢?接下来,本文将介绍如何比较硬件规格和探索优缺点的差异;本文还将基于一个计算机视觉任务,比较在不同平台下,使用迁移学习、混合精度训练、学习率模拟退火以及测试时间增广等操作时,所需的训练时间。基于上述内容,你将对这两个平台的GPU性能,有一个更加全面和清楚的了解。
Kaggle 和 Colab 是两个非常相似的产品,它们都具有如下特性:
提供免费的GPU
在浏览器中使用Jupyter进行交互——但是它们都有自己独特的风格
旨在促进机器学习的协作
都是谷歌的产品
不是十全十美,但是在多数场景下都适用,尤其是在入门深度学习的时候
官方文档对硬件规格的描述较为简略
最后一项是本文研究的重点,但不幸的是,Kaggle和Colab都不提供对使用环境的详细描述,而且官方文档(https://www.kaggle.com/docs/kernels#technical-specifications)往往很过时,跟不上平台硬件更新的速度。除此之外,平台IDE的小控件虽然提供了一些信息,但是这往往不是我们真正想要的。接下来,本文展示常用的profiler命令,该命令可以查看平台环境的信息。
在正式开始之前,我们得先了解一些GPU的背景知识。
什么是GPU?
GPU是图形处理单元的简称,最初GPU是为加速视频游戏的图形所开发的专用芯片,它们能够快速的完成大量的矩阵运算。该特性也使得GPU在深度学习领域崭露头角,有趣的是,出于相同的原因,GPU也是挖掘加密货币的首选工具。
Nvidia P100 GPU
为什么要使用GPU?
使用大显存的GPU来训练深度学习网络,比单纯用CPU来训练要快得多。想象一下,使用GPU能够在十几分钟或者几个小时内,获得所训练网络的反馈信息,而使用CPU则要花费数天或者数周的时间,GPU简直是棒呆了。
硬件规格
2019年三月初,kaggle将它的GPU芯片从Nvidia Tesla K80升级到了Nvida Tesla P100,然而Colab还在用K80。有关Nvidia 芯片类型的讨论,可以参见这篇文章(https://towardsdatascience.com/maximize-your-gpu-dollars-a9133f4e546a)。
有很多不同方法可以查看硬件的信息,两个比较常用的命令是!nvidia-smi和 !cat/proc/cpuinfo,分别用于查看GPU和CPU的信息。即使你想用GPU来训练模型,CPU也是不必可少的,因此了解CPU的信息是必不可少的。
下图所示为Kaggle和Colab的硬件配置信息,更多内容可以参考谷歌官方文档(https://docs.google.com/spreadsheets/d/1YBNlI9QxQTiPBOhsSyNg6EOO9LH2M3zF7ar88SeFQRk/edit?usp=sharing)。

两个平台上的内存大小和磁盘空间,可能会存在一些令人疑惑的地方。一旦在Kaggle或者Colab上安装软件并开始进程,它的内存和磁盘可用量就会发生变化了。我们可以用!cat/proc/meminfo 命令来测试这种容量变化,如下图所示。
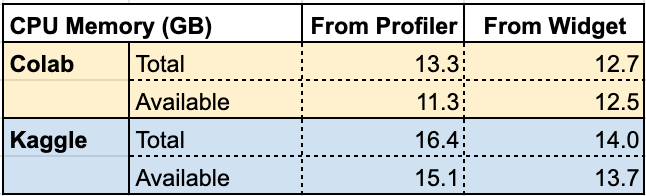
Total表示总内存容量,Available表示启动后,没有任何其他进程运行的情况下,实际观察到的内存容量。从上图可以看到,我们自己测量的值和Colab或Kaggle的IDE控件面板中显示的很相似,但是并不完全匹配,如下图所示。
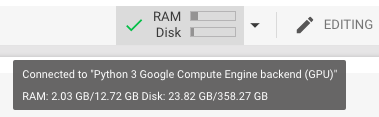
Mouseover in Colab
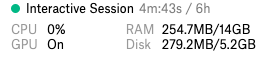
Kaggle Sidebar
上图显示的是Kaggle的内核和Colab Notebook中的硬件规格信息,请注意,在开始前一定要确保开启了GPU的功能。
还有一点值得注意,使用命令行查看GPU的硬件规格时,系统返回值的单位是Mebibytes,该单位和Megabytes(兆字节)相似但并不等同。通过谷歌搜索相应信息,可以将Mebibytes转化为Megabytes。
Kaggle 的widget(小部件)显示,实际使用的磁盘空间比前文调研的要小得多,这是因为,无论理论上的磁盘总量是多少,Kaggle都会限制实际能够使用的磁盘空间。
在官方文档中Kaggle声明,用户拥有9个小时的使用时间,然而,对于每个会话,内核环境最多只会在窗口上显示6个小时。值得注意的是,重新启动内核会重新启动时钟。此外,如果用户在60分钟内没有任何操作,Kaggle会将会话重启。
Colab为用户提供12小时的执行时间,但是如果闲置时间超过90分钟,Colab就会将你踢掉。
接下来就要进入本文的重点了:训练一个深度学习网络,到底会花费多少时间。
计算机视觉任务下的速度比较
本文用一个图像分类的任务来比较Kaggle和Colab的计算性能。该任务的目标是构建一个深度学习模型,对猫狗的图像进行分类。数据集包含25000张图像,猫和狗的样本数是均衡的。将数据集分为两部分,其中23000张图像用于训练,另外2000张用于验证。
Cat and dog images from the dataset
本文用FastAI库构建了一个卷积神经网络,并以ResNet30为基础运用迁移学习训练该模型。模型的训练使用了以下几个技巧,分别是数据增广和学习率退火。在模型的测试阶段,本文使用测试时间增广技术来构建测试集。本节的代码改编自FastAI的示例(https://github.com/fastai/fastai/blob/master/examples/dogs_cats.ipynb)。
代码分别在Kaggle和Colab上的实施。Batch size 设为16,FastAI的版本是1.0.48。使用FastAI的内置分析器,统计训练和测试的总时间,两平台所用的时间如下。
在两个平台中,模型的验证精度都超过了99%,三次迭代的时间在Kaggle中是11:17分钟,而Colab中为19:54分钟。Kaggle的运行环境性能,从速度上看,比Colab要快40%。
Batch Size
在Kaggle中,我们需要将batch size从64降低到16,才能使模型成功进行训练。如果batch size过大,会导致运行错误,该错误似乎是由于Docker容器中的共享内存设置得太低才引起的。有趣的是,作者在2018年底向Colab提出了这个问题(https://github.com/googlecolab/colabtools/issues/329),Colab在一周内便修复了这个问题。然而,截止2019年3月中旬,Kaggle依然存在该问题。
接下来,我们将Colab中的batch size改为256,对模型进行两次迭代训练。上述的改变导致平均运行时间变成了18:38分钟。将batch size改为64,同样进行两次迭代训练,此时得到的平均运行时间为18:14分钟。这表示,当batch size大于16的时候,Colab能够缩减运行的时间。
尽管如此,对于本节中的任务而言,较小的batch size并不是一个值得深究的大问题,有关参数设置的讨论,可以参见这篇文章(https://arxiv.org/abs/1804.07612)。
当我将Colab上的batch size设为256,然后开始训练模型时,Colab抛出了一个警告,其中写道:我正在使用的GPU具有11.17GB的显存。具体如下图所示。
这个警告非常棒,但是基于前文的分析,我们已经了解了Gibibytes和Gigabytes(https://www.gbmb.org/gib-to-gb)之间的区别。前文中讲到,Colab有11.17 Gibibytes(12 GB)的显存,这显然和警告中说的11.17GB矛盾。尽管如此,如果Colab提示你超出内存了,那就是超出内存了。因此batch size设为256,可能就是该任务下Colab的极限了。
混合精度训练
接下来,我们使用了混合精度训练,该训练方式能够有效地降低训练时间。混合精度训练在某些可能的情况下,会使用16位精度的数值代替32位的数值,来进行计算。Nvidia声称使用16位精度,可以使P100的吞吐量翻倍。
有关混合精度FastAI模型的介绍可以参见这篇文章(https://docs.fast.ai/callbacks.fp16.html)。请注意,在使用测试时间增广进行预测之前,我们需要将FastAI学习器对象设置为32位模式,这是因为torch.stack暂时不支持半精度。
通过在Colab上使用混合精度进行训练,在batch size 为16的情况下,平均运行时间为16:37分钟。显然,我们成功的缩减了运行时间。
然而,在Kaggle上实施混合精度训练,总的运行时间却增加了一分半,达到了12:47分钟。我们并没有改变硬件规格,而且得到的验证精度都达到了99%以上,这就很有趣了。
通过调查发现,Kaggle的默认包中的torch和torchvision的版本都很老,将它们的版本更新到和Colab上的一样后,Kaggle的运行时间并没有改变。但是这一个发现表明,Colab上默认包的版本比Kaggle更新的要快。
前文提到的硬件差异,似乎并不是导致Kaggle混合精度性能不佳的原因。那么软件差异似乎是答案,我们观察到,两平台唯一的软件差异就是,Kaggle使用CUDA 9.2.148 和 cuDNN 7.4.1,而Colab 使用CUDA 10.0.130 和 cuDNN 7.5.0。
CUDA是Nvidia的API,可以直接访问GPU的虚拟指令集。cuDNN是Nvidia基于CUDA的深度学习原型库。根据Nvidia的这篇文章,Kaggle的软件应该可以提高P100的速度。但是,正如cuDNN更改说明(https://docs.nvidia.com/deeplearning/sdk/cudnn-release-notes/rel_750.html#rel_750)中所示,阻止加速的bug是定期排查和修复的,那么kaggle在混合精度训练上表现不佳,可能是因为bug修复不及时所导致的吧。
既然如此,我们只好等待Kaggle升级CUDA和cuDNN,看看混合精度训练是否会变得更快。如果使用Kaggle,还是推荐你采用混合精度训练(虽然速度并不会得到提升)。如果使用Colab,当然采用混合精度训练更佳,但是要注意batch size不要设置得太大。
优缺点对比
谷歌是一家希望您支付GPU费用的公司,天下没有免费的午餐。
Colab和Kaggle当然会有一些令人沮丧的问题。例如,两个平台运行时断开连接的频率太高,这令我们非常沮丧,因为我们不得不重启会话。
在过去,这些平台并不能总保证你有GPU可以用,但是现在却可以了。接下来让我们一起看看,Colab和Kaggle的各自的优缺点吧。
Colab
优点
能够在Google Drive上保存notebook
可以在notebook中添加注释
和GIthub的集成较好——可以直接把notebook保存到Github仓库中
具有免费的TPU。TPU和GPU类似,但是比GPU更快。TPU是谷歌自行开发的一款芯片,但不幸的是,尽管Colab意在整合PyTotch和TPU,但TPU对PyTorch的支持仍不太友好。如果使用TensorFlow进行编程,而不是使用FastAI/Pytorch编程,那么在Colab上使用TPU可要比在Kaggle上使用GPU快多了。
缺点
部分用户在Colab中的共享内存较小。
谷歌云盘的使用较为麻烦。每个会话都需要进行身份验证,而且在谷歌云盘中解压文件较为麻烦。
键盘快捷键和Jupyter Notebook中不太一样。具体对比可以参见这里。
Kaggle
优点
Kaggle社区有利于学习和展示你的技能
在Kaggle上发布你的工作,能够记录一段美好的历史
Kaggle和Jupyter notebook的键盘快捷键基本相同
Kaggle有很多免费数据集
缺点
Kaggle一般会自动保存你的工作,但是如果你没有提交工作,然后重新加载你的页面,你的工作很有可能丢失。
就像前面提到的,在Kaggle中,Docker容器中的PyTorch共享内存较低。在本次图像分类任务中,如果设置batch size的大小超过16,那么系统就会报错: RuntimeError: DataLoader worker (pid 41) is killed by signal: Bus error。
Kaggle内核通常看起来有些迟钝。
结论
Colab和Kaggle都是开展云端深度学习的重要资源。我们可以同时使用两者,例如在Kaggle和Colab之间相互下载和上传notebook。
Colab和Kaggle会不断更新硬件资源,我们可以通过比较硬件资源的性能,以及对编程语言的支持,选择最优的平台部署代码。例如,如果我们要运行一个密集的PyTorch项目,并且期望提高精度,那么在Kaggle上开发可能更加适合。
如果我们希望更加灵活的调整batch size 的大小,Colab可能更加适用。使用Colab,我们可以将模型和数据都保存在谷歌云盘里。如果你用TensorFlow编程,那么Colab的TPU将会是一个很好的资源。
如果需要更多的时间来编写代码,或者代码需要更长的运行时间,那么谷歌的云平台的性价比可能更高。
-
谷歌
+关注
关注
27文章
6233浏览量
108565 -
gpu
+关注
关注
28文章
4980浏览量
132103 -
计算机视觉
+关注
关注
9文章
1711浏览量
46955
原文标题:免费GPU哪家强?谷歌Kaggle vs. Colab
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
aicube的n卡gpu索引该如何添加?
保证UI流畅运行,我们需要多强的GPU性能?

当我问DeepSeek国内压力传感器哪家强,它这样回答

iTOP-3588S开发板四核心架构GPU内置GPU可以完全兼容0penGLES1.1、2.0和3.2。
可以手动构建imx-gpu-viv吗?
在Google Colab笔记本电脑上导入OpenVINO?工具包2021中的 IEPlugin类出现报错,怎么解决?
OpenVINO?检测到GPU,但网络无法加载到GPU插件,为什么?
工业网关哪家强?各大厂家简单测评

VS680与智慧教室解决方案

选择DSP处理器的考虑因素(ADSP-2115 vs. TMS320C5x)







 工商网监
工商网监
评论