 谷歌发表论文EfficientNet 重新思考CNN模型缩放
谷歌发表论文EfficientNet 重新思考CNN模型缩放

谷歌AI研究部门华人科学家再发论文《EfficientNet:重新思考CNN模型缩放》,模型缩放的传统做法是任意增加CNN的深度和宽度,或使用更大的输入图像分辨率进行训练,而使用EfficientNet使用一组固定额缩放系数统一缩放每个维度,超越了当先最先进图像识别网络的准确率,效率提高了10倍,而且更小。
目前提高CNN精度的方法,主要是通过任意增加CNN深度或宽度,或使用更大的输入图像分辨率进行训练和评估。
以固定的资源成本开发,然后按比例放大,以便在获得更多资源时实现更好的准确性。例如ResNet可以通过增加层数从ResNet-18扩展到ResNet-200。
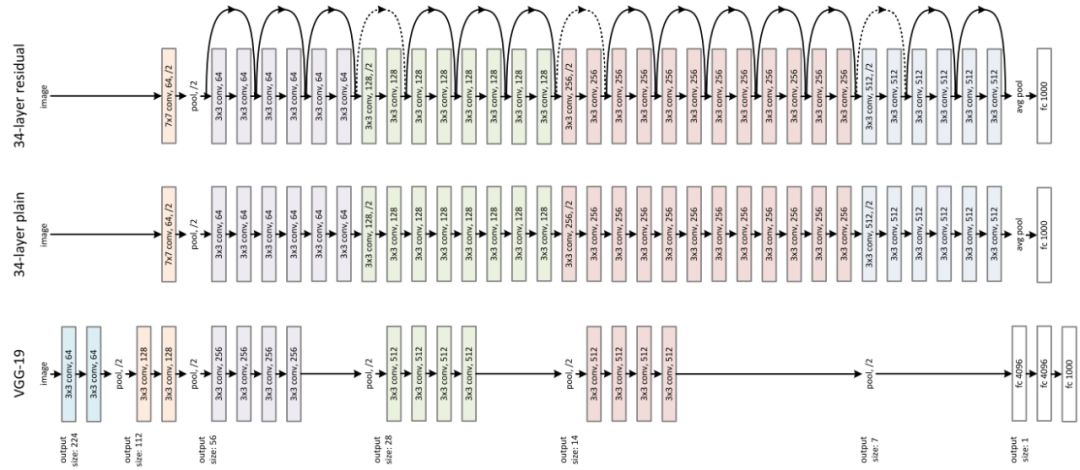
再比如开源大规模神经网络模型高效训练库GPipe,通过将基线CNN扩展四倍来实现84.3% ImageNet top-1精度。
这种方法的优势在于确实可以提高精度,但劣势也很明显。这个时候往往需要进行繁琐的微调。一点点的摸黑去试、还经常的徒劳无功。这绝对不是一件能够让人身心愉快的事情,对于谷歌科学家们也一样。
这就是为什么,谷歌人工智能研究部门的科学家们正在研究一种新的“更结构化”的方式,来“扩展”卷积神经网络。他们给这个新的网络命名为:EfficientNet(效率网络)。
代码已开源,论文刚刚上线arXiv,并将在6月11日,作为poster亮相ICML 2019。
比现有卷积网络小84倍,比GPipe快6.1倍
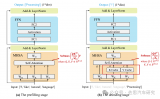
为了理解扩展网络的效果,谷歌的科学家系统地研究了缩放模型不同维度的影响。模型缩放并确定仔细平衡网络深度后,发现只要对网络的深度、宽度和分辨率进行合理地平衡,就能带来更好的性能。基于这一观察,科学家提出了一种新的缩放方法,使用简单但高效的复合系数均匀地缩放深度、宽度和分辨率的所有尺寸。
据悉,EfficientNet-B7在ImageNet上实现了最先进精度的84.4% Top 1/97.1% Top 5,同时比最好的现有ConvNet小84倍,推理速度快6.1倍;在CIFAR-100(91.7%),Flower(98.8%)和其他3个迁移学习数据集上,也能很好地传输和实现最先进的精度。参数减少一个数量级,效率却提高了10倍(更小,更快)。
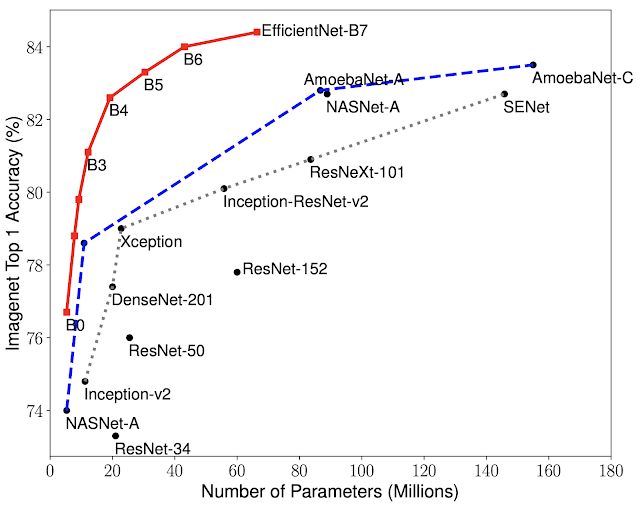
与流行的ResNet-50相比,另一款EfficientNet-B4使用了类似的FLOPS,同时将ResNet-50的最高精度从76.3%提高到82.6%。
这么优秀的成绩是如何做到的
这种复合缩放方法的第一步是执行网格搜索,在固定资源约束下找到基线网络的不同缩放维度之间的关系(例如,2倍FLOPS),这样做的目的是为了找出每个维度的适当缩放系数。然后应用这些系数,将基线网络扩展到所需的目标模型大小或算力预算。
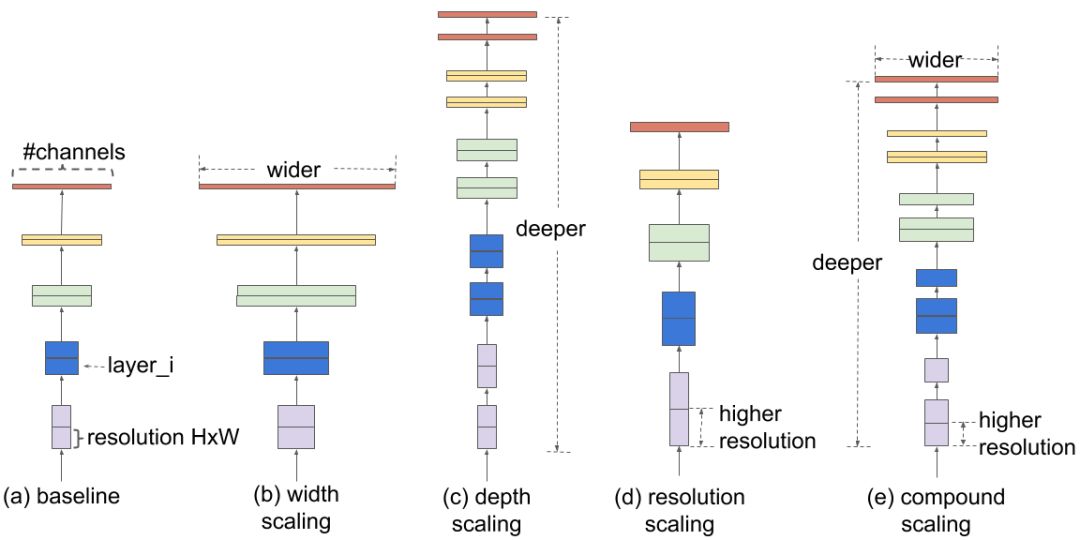
与传统的缩放方法相比,这种复合缩放方法可以持续提高扩展模型的准确性和效率,和传统方法对比结果:MobileNet(+ 1.4% imagenet精度),ResNet(+ 0.7%)。
新模型缩放的有效性,很大程度上也依赖基线网络。
为了进一步提高性能,研究团队还通过使用AutoML MNAS框架执行神经架构搜索来开发新的基线网络,该框架优化了准确性和效率(FLOPS)。
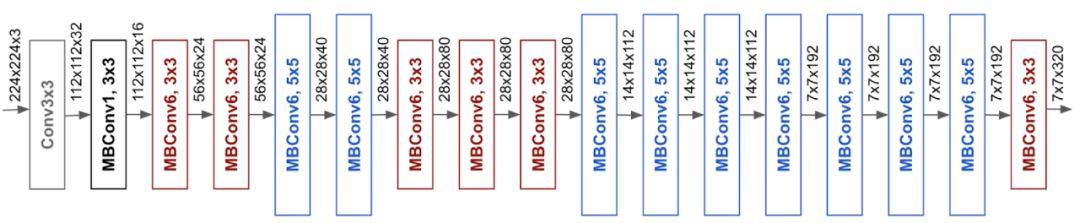
由此产生的架构使用移动倒置瓶颈卷积(MBConv),类似于MobileNetV2和MnasNet,但由于FLOP预算增加而略大。然后,通过扩展基线网络以获得一系列模型,被称为EfficientNets。
不仅局限于ImageNet
EfficientNets在ImageNet上的良好表现,让谷歌的科学家希望将其应用于更广泛的网络中,造福更多的人。
在8个广泛使用的迁移学习数据集上测试之后,EfficientNet在其中的5个网络实现了最先进的精度。例如,在参数减少21倍的情况下,实现了CIFAR-100(91.7%)和Flowers(98.8%)。
看到这样的结果,谷歌科学家预计EfficientNet可能成为未来计算机视觉任务的新基础,因此将EfficientNet开源。
-
谷歌
+关注
关注
27文章
6233浏览量
108559 -
AI
+关注
关注
88文章
35757浏览量
282423 -
cnn
+关注
关注
3文章
354浏览量
22826
原文标题:谷歌出品EfficientNet:比现有卷积网络小84倍,比GPipe快6.1倍
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
大模型时代的深度学习框架

CoT 数据集如何让大模型学会一步一步思考?

谷歌新一代 TPU 芯片 Ironwood:助力大规模思考与推理的 AI 模型新引擎?
无法转换TF OD API掩码RPGA模型怎么办?
美报告:中国芯片研究论文全球领先
DeepSeek发表重磅论文!推出NSA技术,让AI模型降本增效

谷歌 Gemini 2.0 Flash 系列 AI 模型上新
借助谷歌Gemini和Imagen模型生成高质量图像

Kimi发布视觉思考模型k1,展现卓越基础科学能力
谷歌发布Gemini 2.0 AI模型
车载大模型分析揭示:存储带宽对性能影响远超算力






 工商网监
工商网监
评论