 瑞芯微RK3576语音识别算法
瑞芯微RK3576语音识别算法

1.语音识别简介
语音识别技术,也被称为自动语音识别(Automatic Speech Recognition,ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。与说话人识别及说话人确认不同,后者尝试识别或确认发出语音的说话人而非其中所包含的词汇内容。
我们的语音算法是基于Whisper是OpenAI设计的。Whisper作为一个通用的语音识别模型,它使用了大量的多语言和多任务的监督数据来训练,能够在英语语音识别上达到接近人类水平的鲁棒性和准确性。Whisper还可以进行多语言语音识别、语音翻译和语言识别等任务。Whisper的架构是一个简单的端到端方法,采用了编码器-解码器的Transformer模型,将输入的音频转换为对应的文本序列,并根据特殊的标记来指定不同的任务。
基于EASY-EAI-Orin-nano(RK3576)硬件主板的运行效率:
| 算法种类 | 模型大小 | Real Time Factor (RTF) |
| speech_decoder | 383MB | 0.077 |
| speech_encoder | 217MB | 0.077 |
2.快速上手
如果您初次阅读此文档,请阅读:《入门指南/源码管理及编程介绍/源码工程管理》,按需管理自己工程源码(注:此文档必看,并建议采用【远程挂载管理】方式,否则有代码丢失风险!!!)。
2.1开源码工程下载
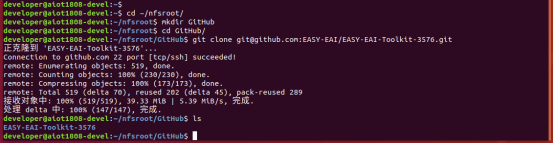
先在PC虚拟机定位到nfs服务目录,再在目录中创建存放源码仓库的管理目录:
cd ~/nfsroot mkdir GitHub cd GitHub
再通过git工具,在管理目录内克隆远程仓库(需要设备能对外网进行访问)
git clone https://github.com/EASY-EAI/EASY-EAI-Toolkit-3576.git
注:
* 此处可能会因网络原因造成卡顿,请耐心等待。
* 如果实在要在gitHub网页上下载,也要把整个仓库下载下来,不能单独下载本实例对应的目录。
2.2开发环境搭建
通过adb shell进入板卡开发环境,如下图所示。
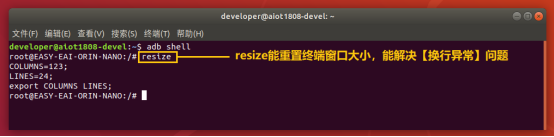
通过以下命令,把nfs目录挂载上nfs服务器。
mount -t nfs -o nolock : /home/orin-nano/Desktop/nfs/

2.3例程编译
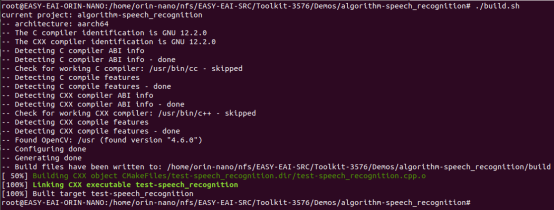
然后定位到板卡的nfs的挂载目录(按照实际挂载目录),进入到对应的例程目录执行编译操作,具体命令如下所示:
cd EASY-EAI-Toolkit-3576/Demos/algorithm-speech_recognition/ ./build.sh
2.4模型部署
要完成算法Demo的执行,需要先下载法模型。
百度网盘链接为:https://pan.baidu.com/s/1jNjnfjnrmyW3_vvdgEG-rA?pwd=1234 (提取码:1234)。
同时需要把下载的解码模型和编码模型复制粘贴到Release/目录:
2.5例程运行及效果
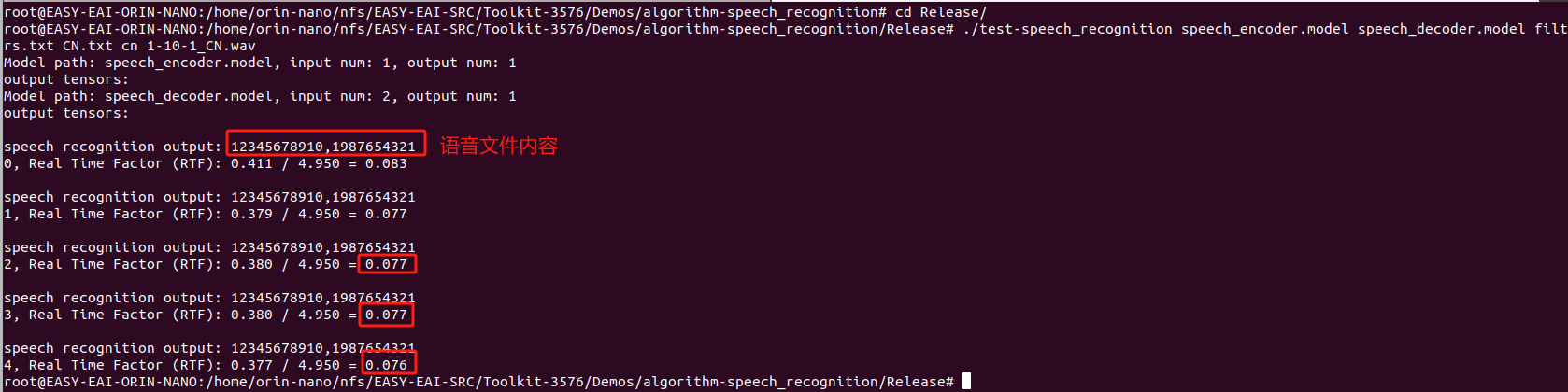
进入开发板Release目录,执行下方命令,运行示例程序:
cd Release/ ./test-speech_recognition speech_encoder.model speech_decoder.model filters.txt CN.txt cn 1-10-1_CN.wav
运行例程命令如下所示:
API的详细说明,以及API的调用(本例程源码),详细信息见下方说明。
3.语音识别API说明
3.1引用方式
为方便客户在本地工程中直接调用我们的EASY EAIapi库,此处列出工程中需要链接的库以及头文件等,方便用户直接添加。
选项 | 描述 |
| 头文件目录 | easyeai-api/algorithm/speech_recognition |
| 库文件目录 | easyeai-api/algorithm/speech_recognition |
| 库链接参数 | -lspeech_recognition |
3.2语音识别检测初始化函数
设置语音识别初始化函数原型如下所示。
int speech_recognition_init(const char *p_encoder_path, const char *p_decoder_path, const char *p_filter_path,
const char *p_vocab_path, rknn_whisper_t *p_whisper);
具体介绍如下所示。
函数名:speech_recognition_init | |
| 头文件 | speech_recognition.h |
| 输入参数 | p_encoder_path:编码模型名字/路径 |
| 输入参数 | p_decoder_path:解码模型名字/路径 |
| 输入参数 | p_filter_path:滤波器频谱 |
| 输入参数 | p_vocab_path:词组文件 |
| 输入参数 | p_whisper:语音识别句柄 |
| 返回值 | 成功返回:0 |
| 失败返回:-1 | |
| 注意事项 | 无 |
3.3语音识别运行函数
设置语音识别运行原型如下所示。
int speech_recognition_run(rknn_whisper_t *p_whisper, audio_buffer_t audio, int task_code, std::vector &recognized_text);
具体介绍如下所示。
| 函数名:speech_recognition_run | |
| 头文件 | speech_recognition.h |
| 输入参数 | p_whisper:语音识别句柄 |
| 输入参数 | audio:待识别音频信息 |
| 输入参数 | task_code:语音识别任务 |
| 输入参数 | recognized_text:语音识别结果 |
| 返回值 | 成功返回:0 |
| 失败返回:-1 | |
| 注意事项 | 无 |
3.4语音识别释放函数
设置语音识别释放原型如下所示。
int speech_recognition_release(rknn_whisper_t *p_whisper);
具体介绍如下所示。
| 函数名:speech_recognition_release | |
| 头文件 | speech_recognition.h |
| 输入参数 | p_whisper:语音识别句柄 |
| 返回值 | 成功返回:0 |
| 失败返回:-1 | |
| 注意事项 | 无 |
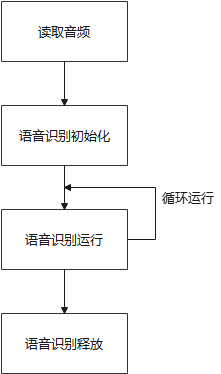
- 语音识别算法例程
例程目录为Demos/algorithm-speech_recognition/test-speech_recognition.cpp,操作流程如下所示:
#include #include #include #include #include #include "sndfile.h" #include "speech_recognition.h" #include "audio_utils.h" int main(int argc, char **argv) { if (argc != 7){ printf("%s \n", argv[0]); printf("Example: %s speech_encoder.model speech_decoder.model filters.txt CN.txt cn 1-10-1_CN.wav\n", argv[0]); return -1; } const char *p_encoder_path = argv[1]; // 编码模型地址 const char *p_decoder_path = argv[2]; // 解码模型地址 const char *p_filter_path = argv[3]; // 滤波器频谱 const char *p_vocab_path = argv[4]; // 词组文件 const char *p_task = argv[5]; // 识别语种(cn/en) const char *p_audio_path = argv[6]; // 待识别音频 int task_code = 0; std::vector recognized_text; // Tokenizer 预定义控制符号(切换语言或任务) if (strcmp(p_task, "en") == 0){ task_code = 50259; } else if (strcmp(p_task, "cn") == 0){ task_code = 50260; } else{ printf("\n\033[1;33mCurrently only English or Chinese recognition tasks are supported. Please specify as en or zh\033[0m\n"); return -1; } // 读取音频,并对音频进行处理 audio_buffer_t audio; int ret = read_audio(p_audio_path, &audio); if (ret != 0){ printf("read audio fail! ret=%d audio_path=%s\n", ret, p_audio_path); return -1; } if (audio.num_channels == 2){ ret = convert_channels(&audio); } if (audio.sample_rate != SAMPLE_RATE){ ret = resample_audio(&audio, audio.sample_rate, SAMPLE_RATE); } // speech recognition初始化 rknn_whisper_t whisper; ret = speech_recognition_init(p_encoder_path, p_decoder_path, p_filter_path, p_vocab_path, &whisper); int iter = 0; for (int i=0; i < 5; i++) { clock_t start = clock(); recognized_text.clear(); // speech recognition语音识别 ret = speech_recognition_run(&whisper, audio, task_code, recognized_text); clock_t end = clock(); // 记录结束时间 double infer_time = ((double)(end - start)) / CLOCKS_PER_SEC; // 转换为秒 // 结果输出 std::cout << "\nspeech recognition output: "; for (const auto &str : recognized_text){ std::cout << str; } std::cout << std::endl; float audio_length = audio.num_frames / (float)SAMPLE_RATE; // sec audio_length = audio_length > (float)CHUNK_LENGTH ? (float)CHUNK_LENGTH : audio_length; float rtf = infer_time / audio_length; printf("%d, Real Time Factor (RTF): %.3f / %.3f = %.3f\n", iter++, infer_time, audio_length, rtf); } // speech recognition释放 speech_recognition_release(&whisper); return 0; }
-
语音识别
+关注
关注
39文章
1788浏览量
114437 -
瑞芯微
+关注
关注
25文章
629浏览量
52644 -
rk3576
+关注
关注
1文章
189浏览量
862
发布评论请先 登录
米尔RK3576和RK3588怎么选?-看这篇就够了
米尔瑞芯微RK3576实测轻松搞定三屏八摄像头
国产开发板的端侧AI测评-基于米尔瑞芯微RK3576
适配多种系统,米尔瑞芯微RK3576核心板解锁多样化应用
Onenet云网关方案应用--基于米尔瑞芯微RK3576开发板
瑞芯微RK3576|触觉智能:开启科技新篇章

新品体验 | RK3576开发板

米尔RK3576开发板特惠活动!

NPU性能深度评测:瑞芯微RK3588、RK3576、RK3568、RK3562
瑞芯微RK3576与RK3576S有什么区别,性能参数配置与型号差异解析






 工商网监
工商网监
评论