 Transformer在端到端自动驾驶架构中是何定位?
Transformer在端到端自动驾驶架构中是何定位?

[首发于智驾最前沿微信公众号]随着自动驾驶系统从模块化走向端到端,Transformer正逐渐被引入到端到端架构中,试图解决传统模型在复杂语义理解、全局路径推理以及行为预测上的局限。但我们必须清晰认识到,Transformer在端到端架构中的作用既非全能主脑,也并非简单插件,它更像是“认知大脑”的角色,在端到端系统中承担高阶决策与抽象建模的任务,而具体的感知、控制、接口层仍需要传统深度学习模型支撑。这种多层次分工,是现阶段端到端架构得以落地的现实路径。
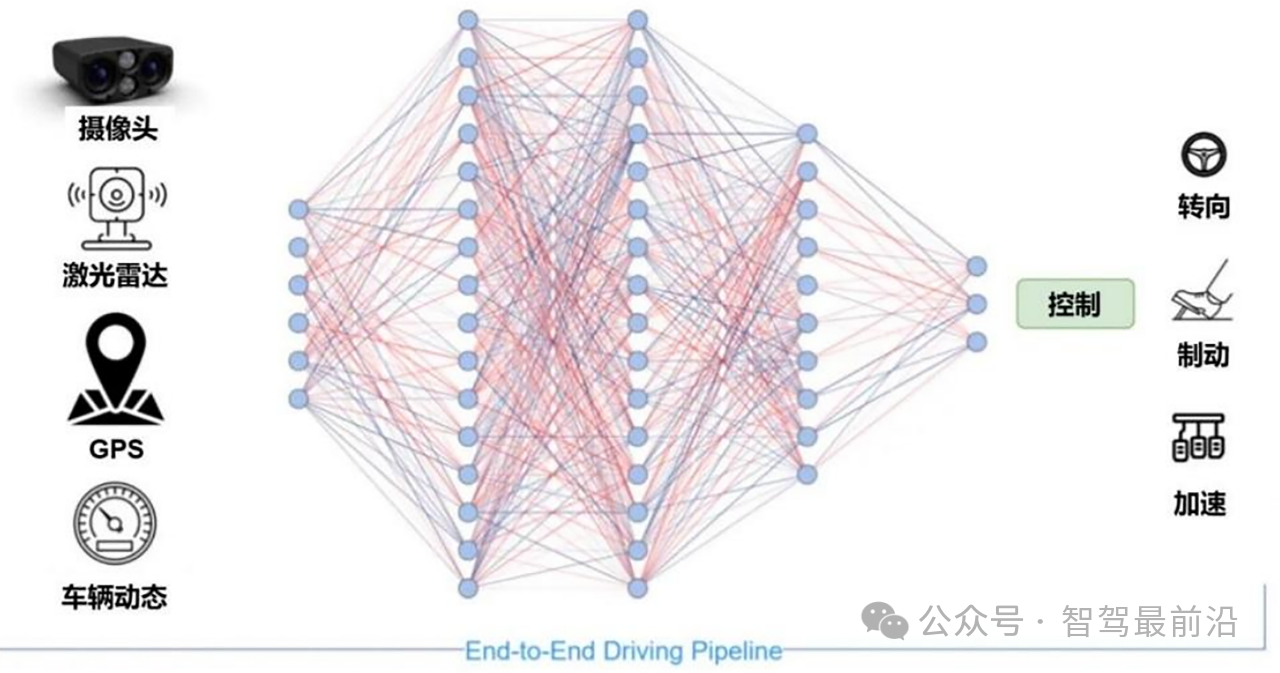
传统端到端架构追求的是感知、决策、控制“一体化”建模,即通过一个大模型输入传感器原始数据(如图像、点云、雷达),直接输出转向角、加速度、刹车指令等操作值。在这个过程中,模型在内部完成了目标识别、语义理解、路径预测等任务,但由于中间过程不可分割,因此也失去了可解释性与调试能力。这在学术实验中尚可接受,但在需要极高安全保障的商用场景中存在巨大风险。Transformer试图通过其在序列建模和上下文理解上的强大能力,提升端到端模型的抽象表达能力,并通过“注意力机制”模拟决策过程的透明性。
目前,典型的Transformer架构已被用于构建“感知-规划-控制统一建模”的方案。如Waymo和小马智行正在研发的多模态大模型(MultimodalLargeModels,MLLMs),将来自摄像头、激光雷达、毫米波雷达的数据融合输入,并结合地图语义、交通规则、历史轨迹等信息,交由Transformer构建多层次时空表征。这种表征并非直接输出控制命令,而是形成一个“世界模型”——即系统对当前交通状态的主观理解。随后,该模型再将理解结果交由行为规划子模块去执行,使得端到端过程具有一定结构化逻辑,从而兼顾可解释性与泛化能力。
Transformer在此过程中承担了以下几个关键角色,首先,它作为感知与推理的中间桥梁,将多模态信息统一编码后,建立不同要素之间的因果关系。如前方车辆正在减速、右侧有行人接近斑马线、红绿灯为黄色,这一系列事件并非孤立,而是需要模型结合上下文统一判断其潜在交互模式。传统深度学习模型常以图像特征为主导,缺乏事件间的时间序列建模能力,而Transformer则可通过自注意力机制理解其潜在逻辑与权重。
其次,在行为预测与交互建模方面,Transformer的优势更加明显。当前大多数自动驾驶车辆仍面临“交互不清晰”的问题,即无法准确预测其他交通参与者的未来行为。在密集城市交通中,行人与非机动车的行为极具不确定性,传统模块化方法常常分工割裂,难以统一评估这些交互背后的潜在意图。而Transformer可将多方信息整合为统一的时序表示,并通过预训练或迁移学习,推断出最合理的策略响应。这种“策略编排能力”正是大模型在端到端架构中所具备的关键竞争力。
但我们也必须看到,Transformer模型在端到端架构中的部署仍有很多问题需要解决。首先是实时性。自动驾驶决策周期通常控制在50~100毫秒以内,而当前参数级别在数十亿的LLM模型,其推理时间远超这一窗口,哪怕在专用加速芯片上也难以满足高频循环执行的需要。为此,有方案正在尝试构建“轻量化Transformer”或剪枝后的中型模型,用于车端执行,同时将大型模型部署在云端,用于训练、场景生成和后处理分析。
其次是数据来源与分布一致性问题。端到端架构中,训练数据的分布对最终模型稳定性至关重要。Transformer需要大规模多样化的训练语料,但当前自动驾驶行业的数据集大多来自“长尾场景稀缺”的真实道路采集,难以支持Transformer在各种极端场景中的泛化学习。因此,越来越多采用仿真平台生成“近物理级真实场景”,通过虚拟交通参与者的动态交互来拓展模型的训练维度。英伟达的Omniverse与小马智行的Cosmos就是典型代表,它们利用物理引擎+世界建模的方式,赋能Transformer实现更完整的场景理解与迁移学习。
可解释性问题仍是另一个待解命题。尽管Transformer的注意力权重图可以部分展示模型的“关注焦点”,但其内部推理路径、权重更新机制依旧缺乏明确可控的数学表达式。这意味着当模型在特定场景下做出错误决策时,我们难以准确还原其出错节点。这对负责安全评估的工程师或监管机构来说是巨大障碍。因此,现阶段很多自动驾驶方案并不完全放弃中间模块,而是采取“端到端+模块化结合”的策略,既保留可追溯路径,也提升建模能力。
在实际部署时,Transformer常被用于“策略融合层”或“全局语义层”。在系统完成环境感知之后,Transformer可用来处理如“当前进入学校区域需减速”、“根据红绿灯逻辑调整等待时间”等上下文规则。这种基于语义的规则推理与路径重组,正是传统神经网络难以处理的抽象逻辑任务,也是Transformer最为擅长的部分。从长远来看,这种认知能力的引入或将推动自动驾驶从“感知驱动”向“意图驱动”转型,让车辆不仅看到周围发生了什么,还能理解“为什么”会发生,从而更好地预测“接下来会发生什么”。
还有一些技术方案正在探索更为极致的端到端方式,如将Transformer作为唯一的大模型,从传感器输入到控制输出全部涵盖。特斯拉的FSD Beta系统便试图走这条路径,尝试用Transformer编排整个感知-决策流程,规避中间人工规则的干预。然而,目前该方案仍面临大量质疑。其在面对突发情况时缺乏故障冗余;系统行为的不可解释性也令监管机构难以接受。因此,哪怕在特斯拉公布的Robotaxi项目中,仍需配备人工监控机制以确保安全兜底。这充分说明,在安全为前提的自动驾驶场景中,Transformer在端到端中的应用尚处于“受限”阶段。
综上,Transformer在端到端自动驾驶架构中的角色定位,绝不是“替代一切”的通用工具,也不是某些理想主义者期待的“万能大脑”。更准确地说,它是一种用于抽象建模、高阶推理、语义决策与交互理解的智能补丁。它填补了传统深度学习难以处理的认知空白,为系统带来了更强的泛化能力与策略灵活性。它并不取代感知、控制等需要硬实时与高稳定性的基础模块,而是通过融合架构提升整个系统的智能密度。在未来的系统演进中,Transformer将可能更多地参与“认知层”设计,成为辅助驾驶系统的“推理引擎”,但真正掌握方向盘的,仍然是深度学习与工程控制的“执行大脑”。
-
自动驾驶
+关注
关注
790文章
14364浏览量
171130 -
Transformer
+关注
关注
0文章
153浏览量
6551
发布评论请先 登录
Nullmax端到端自动驾驶最新研究成果入选ICCV 2025
为什么自动驾驶端到端大模型有黑盒特性?

端到端数据标注方案在自动驾驶领域的应用优势
东风汽车推出端到端自动驾驶开源数据集
动量感知规划的端到端自动驾驶框架MomAD解析
DiffusionDrive首次在端到端自动驾驶中引入扩散模型









 工商网监
工商网监
评论