 MQTT物联网数据解析的难点有哪些?
MQTT物联网数据解析的难点有哪些?

MQTT物联网数据解析的难点主要源于物联网场景中设备的多样性、数据的复杂性以及系统的高要求,具体可归纳为以下几个方面:
1.数据格式碎片化与协议不统一
物联网设备来源广泛(不同厂商、不同型号、不同应用场景),导致数据格式高度碎片化:
既有结构化的JSON、XML,也有二进制、自定义协议(如私有Modbus变体、厂商专属二进制格式),甚至同一类型设备的不同批次可能采用不同格式;
协议文档往往不规范(如字段含义模糊、单位未明确、数据类型标注错误),导致解析逻辑设计困难,需反复调试匹配设备实际输出;
部分老旧设备沿用传统工业协议(如BACnet、OPCUA),与MQTT的轻量特性适配时需额外转换,增加解析层复杂度。
2.二进制协议解析的高精度要求
为节省带宽和硬件资源,工业设备常采用二进制格式传输数据,但其解析对精度要求极高,易出现疏漏:
需精确处理字节对齐、位运算(如某字段占3个字节中的后12位)、大小端字节序(LittleEndian/BigEndian)等细节,稍有偏差就会导致数据完全错误;
数据类型转换复杂(如将16位无符号整数解析为温度值时,需结合厂商定义的缩放因子、偏移量计算,公式错误会导致结果失真);
二进制格式可读性差,调试时难以通过肉眼识别问题,需借助专用工具(如Wireshark)逐字节比对,排错效率低。
3.数据完整性与容错性挑战
物联网环境的网络不稳定性(如弱网、断连重连)和设备硬件限制,常导致数据不完整或异常,增加解析难度:
数据丢失:MQTT虽能保证消息送达,但设备突发断电可能导致发送半截数据(如预期10字节仅收到6字节),解析时需识别不完整包并丢弃或补全;
异常值处理:设备传感器故障可能发送超出合理范围的数据(如温度=200℃),解析系统需结合业务规则过滤无效值,避免污染后续分析;
格式混叠:同一Topic下可能混入不同格式数据(如设备固件升级后格式变更但未更换Topic),需动态识别数据版本并切换解析规则,否则会批量解析失败。
4.高并发与实时性的性能瓶颈
在大规模物联网场景(如智慧工厂、智慧城市)中,数万甚至数百万设备同时发送数据,解析环节需平衡效率与实时性:
解析逻辑若过于复杂(如多层嵌套JSON解析、高频加密解密),会导致CPU占用过高,成为系统瓶颈,影响数据处理时效;
边缘计算场景中,边缘节点硬件资源有限(如嵌入式设备),复杂解析逻辑可能超出其算力,需在解析精度与轻量化之间妥协;
动态扩展困难:当设备数量激增时,解析规则的分布式部署需保证一致性,否则可能出现部分节点解析逻辑滞后,导致数据不一致。
5.版本兼容性与迭代成本
设备固件升级、业务需求变更会导致数据格式迭代,解析系统需持续适配,成本较高:
旧设备与新设备的数据格式可能共存(如老设备用JSON,新设备用二进制),解析系统需同时维护多套规则,增加代码复杂度;
协议升级可能引入新字段或废弃旧字段,若解析逻辑未及时更新,可能导致新数据被误判为异常,或旧数据解析缺失关键信息;
缺乏标准化的版本协商机制(如MQTT协议本身不定义数据格式版本),需额外设计版本标识(如在Topic中加入版本号),否则难以区分数据格式。
这些难点的核心在于“多样性”与“稳定性”的矛盾——物联网场景的设备异构性决定了数据格式的复杂性,而工业级应用对数据准确性、实时性的要求又需要解析系统具备极高的稳定性和适应性。因此,实际落地中常需结合规则引擎、设备孪生(DigitalTwin)等技术,通过可视化配置、动态更新解析规则等方式降低维护成本。
-
物联网
+关注
关注
2933文章
46461浏览量
395443 -
MQTT
+关注
关注
5文章
697浏览量
23851
发布评论请先 登录
MQTT网关具备边缘计算功能吗?有什么功能?
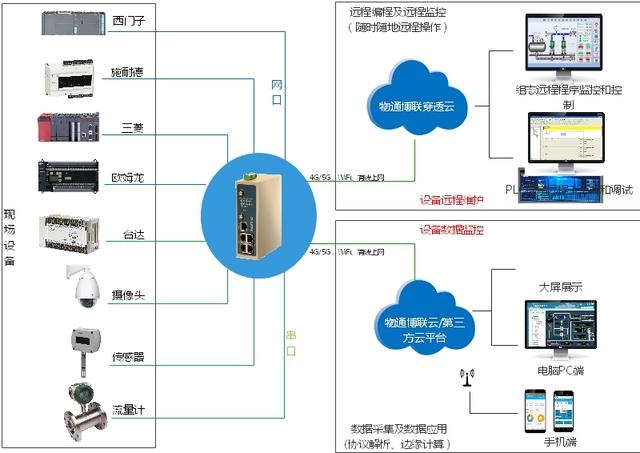
MQTT为何成为物联网协议
IO数据采集物联网平台是什么?有什么功能?
MQTT网关接入工业物联网平台解析
MQTT调试助手中文版(物联网开发必备)
MQTT智能网关接入物联网平台:实现高效连接与数据交互
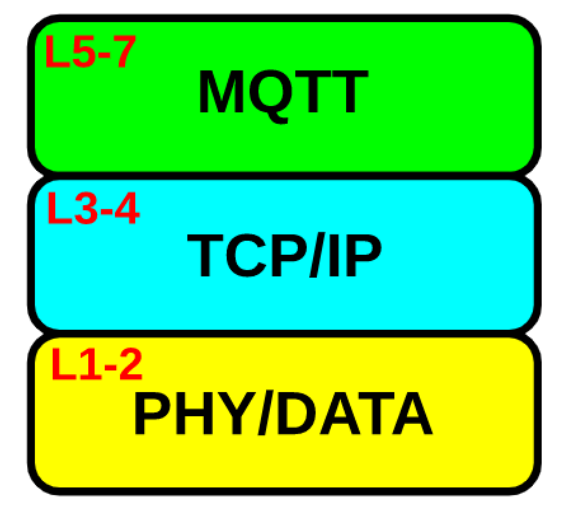
物联网行业中MQTT通信协议详解以及使用
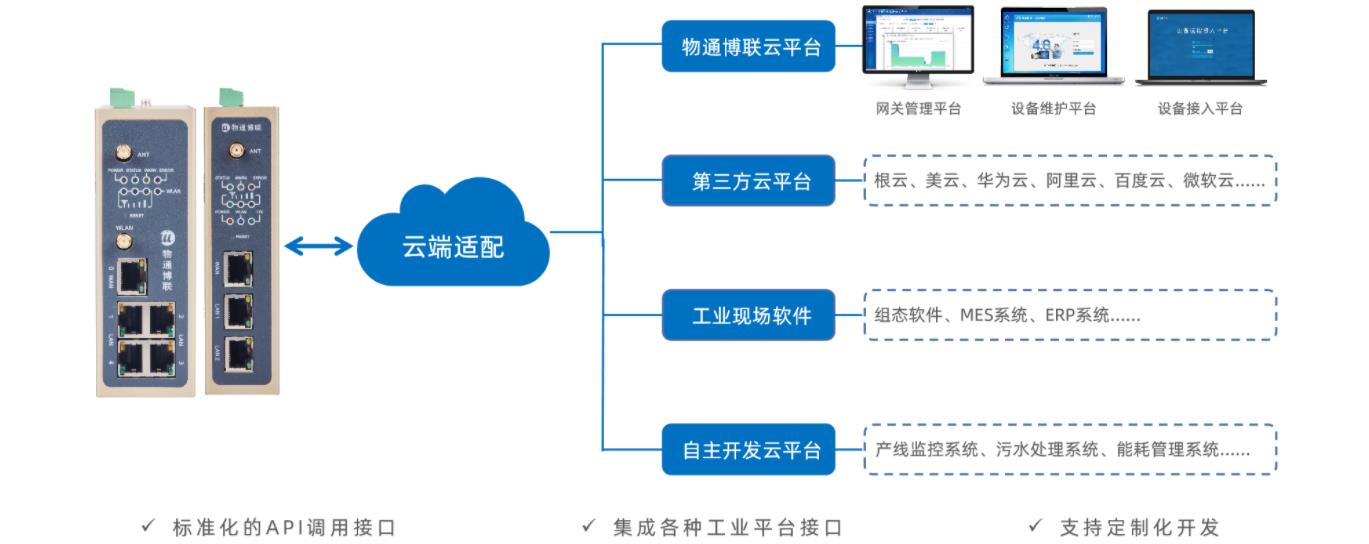
MQTT网关:物联网中的关键桥梁





 工商网监
工商网监
评论