 Untether AIТэБмНЁУГAIНЖАнјУЛЩЖчКРіЎ
Untether AIТэБмНЁУГAIНЖАнјУЛЩЖчКРіЎ

ЖѕЅиЖд¶АМШµДat-memoryјЖЛгјЬ№№Ј¬Untether AIПЈНыТэБмНЁУГAIНЖАнјУЛЩЖчКРіЎЎЈХвјТіхґґ№«ЛѕДЬ·сИЎґъЦчµјAIСµБ·БмУтЎўІўЅ«ґҐЅЗЙмПтAIНЖАнБмУтµДБмПИCPUєНGPU№©У¦ЙМЈїХвР©БоИЛУЎПуЙоїМµДХ№КѕЧгТФИГХвјТ№«ЛѕіЙ№¦ВрЈї Untether AIКЗТ»јТЧЬІїО»УЪ¶аВЧ¶аµДAIРѕЖ¬іхґґ№«ЛѕЈ¬ЙПЦЬФЪHot Chips 2022ЙП·ўІјБЛЖдЧоРВµДНЁУГAIНЖАнјУЛЩЖчЈ¬ГыОЄspeedAIЈ¬»щУЪёГ№«ЛѕµДЎ°at-memoryЎ±јЖЛгјЬ№№ЎЈ
SpeedAIЦјФЪЅвѕцAIјЖЛ㹤ЧчБїµД±¬ХЁРФФці¤Ј¬ТФј°ФЪ№г·єµДAIНЖАнУ¦УГЦР¶ФёьёЯѕ«¶ИЎўёьµНСУіЩЎўёьБй»оєНёьУЕДЬР§ИХТжФці¤µДРиЗуЎЈ
Untether AIЧЁЧўУЪНЖАнУ¦УГЈ¬ХэКФНјДЈ·ВNvidiaФЪAIСµБ··ЅГжµДіЙ№¦ЎЈ
AIґ¦Ан·ЦОЄБЅёцЅЧ¶ОЎЈФЪСµБ·ЅЧ¶ОЈ¬їЄ·ўИЛФ±ПтЛыГЗµДДЈРНМṩһёцѕ№эІЯ»®µДКэѕЭјЇЈ¬ХвСщЛьѕНїЙТФЎ°С§П°Ў±ЛьЅ«·ЦОцµДКэѕЭАаРНЛщРиµДТ»ЗРЎЈИ»єуЈ¬ФЪНЖАнЅЧ¶ОЈ¬ДЈРНїЙТФёщѕЭКµК±КэѕЭЅшРРФ¤ІвЈ¬ІъЙъїЙІЩЧчµДЅб№ыЎЈєуХЯХэКЗUntether AIЛщЧ·ЗуµДПё·ЦКРіЎЎЈ
Untether AIµДДї±кКЗ·с№эУЪРЫРДІЄІЄЈїТІРнЎЈµ«»щУЪЖдРѕЖ¬З°ЛщОґУРµД30 TFLOPS/WєН2 PFLOPSµДРФДЬЈ¬Untether AIПаРЕЛьУР»ъ»бЎЈёГ№«ЛѕЙщіЖЖдЧоРВµДНЖАнјУЛЩЖчЎ°ОЄДЬР§єНјЖЛгГЬ¶ИЙи¶ЁБЛРВµД±кЧјЎ±ЎЈ
Yole IntelligenceјЖЛгєНИнјюјјКхєНКРіЎ·ЦОцК¦Adrien SanchezіЖspeedAIµД30FLOPS/WЎ°БоИЛУЎПуЙоїМЎ±ЎЈЛыІ№ідЛµЈ¬Хв»ч°ЬБЛNvidiaµДA100Ј¬ІўУлNvidiaµДHopperЙи±ёПажЗГАЎЈSanchezЛµЈєЎ°іПИ»Ј¬Ѕ«ОЄСµБ·БїЙн¶ЁЦЖµДУІјюУлТФНЖАнОЄЦШµгµДУІјюЅшРР±ИЅПКЗНкИ«І»Н¬µДЈ¬µ«ХвИФИ»БоИЛУЎПуЙоїМЎЈЎ±AIНЖАнКРіЎєёЗБЛґУЧФ¶ЇјЭК»ЖыіµµЅЦЗДЬіЗКР/БгКЫЎўЧФИ»УпСФґ¦АнєНїЖС§У¦УГµИ·Ѕ·ЅГжГжЎЈ
ґ¦ФЪК®ЧЦВ·їЪµДAIНЖАн
ФЪµ±ЅсµДНЁУГAIґ¦АнЖчКРіЎЈ¬NvidiaОЮТЙКЗСµБ·БмУтµДНхХЯЎЈѕЎ№ЬNvidiaµДёЯ№¦єДЅвѕц·Ѕ°ёІ»М«ККєПAIНЖАнУ¦УГЈ¬µ«ФЪПЦКµЦРЈ¬Рн¶аNvidiaїН»§ЧоЦХТІ»бК№УГNvidia»щУЪGPUµДЅвѕц·Ѕ°ёАґВъЧгЛыГЗµДНЖАнРиЗуЎЈ
И»¶шЈ¬AIНЖАнКРіЎХэґ¦УЪК®ЧЦВ·їЪЎЈРн¶аУГ»§єЬДСФЪAIНЖАнТэЗжЦРХТµЅДЬР§єНБй»оРФЦ®јдµДХЫЦР·Ѕ°ёЎЈ
Т»·ЅГжЈ¬УР№г·єК№УГµД»щУЪCPUєНGPUµДЅвѕц·Ѕ°ёЎЈБнТ»·ЅГжЈ¬Рн¶аНЖАнґ¦АнЖчНЁіЈЧЁГЕЧчОЄКУѕхґ¦АнЖчЎЈUntether AI№«ЛѕІъЖ·ё±ЧЬІГBob Beachler±нКѕЈ¬MobileyeєНAmbarellaµИ№«ЛѕЎ°їЙТФФЪЛьГЗµДSoCЙПКµПЦТ»Р©AI№¦ДЬЈ¬ЖдЦРТ»Р©ТСѕіЙ№¦КµПЦБЛБїІъЎЈЎ±
ФЪДїЗ°ЛйЖ¬»ЇµДAIНЖАнКРіЎЦРЈ¬И±ЙЩТ»ЦЦДЬ№»ґ¦АнёчЦЦУ¦УГЦРAI№¤ЧчёєФШµДНЖАнТэЗжЎЈ
TechInsightsµДКЧПЇ·ЦОцLinley GwennapИПОЄЈ¬Ў°їјВЗµЅЙсѕНшВзµД¶аСщРФєН±д»ЇЎ±Ј¬јґК№КЗУГУЪНЖАнЈ¬ЧојСЅвѕц·Ѕ°ёИФКЗНЁУГAIґ¦АнЖчЎЈБнТ»ЦЦСЎФсКЗЎ°Т»ЦЦёьѕЯМеµДґ¦АнЖчЈ¬АэИзЈ¬Ц»ФЪѕн»эНшВзЙП№¤ЧчЎ±ЎЈ
GwennapЛµЈєЎ°GPUёьјУНЁУГЈ¬ХвѕНКЗОЄКІГґЛьИзґЛЖХ±йµДФТтЎЈЎ±Untether AIЈЁФЪspeedAIЈ©ФцјУБЛёь¶аµДБй»оРФЈ¬ТФВъЧгAIНЖАнУ¦УГµДХвР©ёь№г·єµДРиЗуЎЈ
їЙА©Х№µДІъЖ·ПµБР
Beachler±нКѕЈ¬Untether AIЅ«°СspeedAI±діЙТ»ёцїЙА©Х№µДПµБРЎЈЙПЦЬ·ўІјµДSpeedAI 240±»КЗЧоґуµДЙи±ёЈ¬¶шТ»Р©БРµДЛхРЎ°жЈЁФЪІ»Н¬µД№¦ВКЅЪµгЙПУРёьЙЩµДmemory bankЈ©ХэФЪїЄ·ўЦРЎЈХвР©јУЛЩЖчµД№¦ВК·¶О§ґУ10WµЅ5WЙхЦБКЗСЗНЯЈ¬BeachlerЛµЈ¬ТтґЛЎ°ОТГЗµДРѕЖ¬їЙТФіЙОЄИОєОЗ¶ИлКЅSoCµДРґ¦АнЖчЈ¬ХвИЎѕцУЪДгїЙДЬРиТЄ¶аЙЩAIјЖЛгЎЈЎ±
SpeedAI 240јЖ»®ФЪ2023ДкіхіцСщЎЈ°ґ±ИАэЛхРЎµДНЖАнјУЛЩЖчјЖ»®ФЪГчДкНнР©К±єтНЖіцЎЈ
At-memoryјЖЛг
Untether AIЦ®ЛщТФіцГыЈ¬КЗТтОЄЛьЧФјє·ўГчБЛТ»ЦЦЎ°at-memoryЎ±јЖЛгјЬ№№ЎЈ
ХвјТіхґґ№«ЛѕЙијЖБЛat-memoryјЖЛгЈ¬Ѕ«ЖдAIНЖАнјУЛЩЖчґУCPUєНGPU·лЎ¤ЕµТБВьјЬ№№№МУРµДµНДЬР§ЦРЅв·ЕіцАґЎЈХвКЗТтОЄФЪ·лЎ¤ЕµТБВьјЬ№№ПВЈ¬КэѕЭґУDRAMґ«КдµЅ±ѕµШ»єґжЈ¬И»єуЅшИ봦АнФЄЛШµДѕаАлТЄФ¶µГ¶аЎЈ
Untether AIµДat-memory·Ѕ°ёФЪКэѕЭЧ¤БфµДµШ·Ѕґ¦АнЈ¬ЧЁУГSRAMК№УГ¶М¶шїнµДЧЬПЯЎЈХвЦЦmemory bankјЬ№№ФКРнAIјЖЛгЛщРиµДР§ВКєНґшїнЈ¬Н¬К±Ц§іЦјЖЛгµДґу№жДЈІўРРЦ±ЅУБ¬ЅУЎЈ
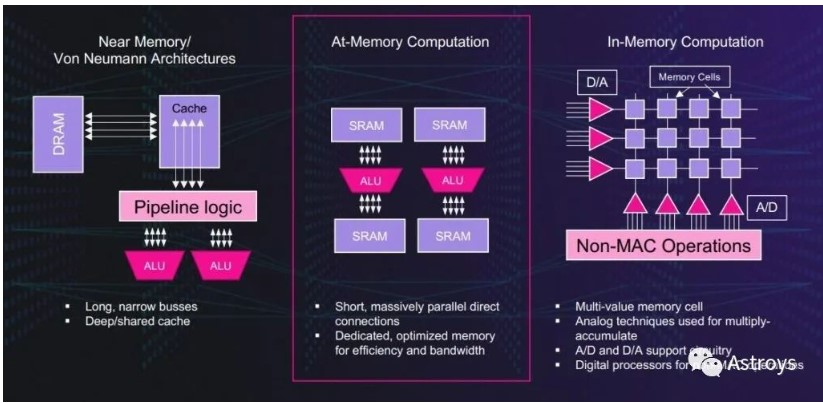
Untether AIК№УГAt-Memory ComputationЅшРРAIјУЛЩЎЈ
ХвІўІ»КЗUntetherAIµДat-memoryјЖЛгјЬ№№µДµЪТ»ґОХ№КѕЎЈёГ№«ЛѕКЧПИНЁ№эЖдЧоіхµДAIНЖАнјУЛЩЖчrunAIХ№КѕБЛЖд·Ѕ·ЁµДУЕКЖЎЈrunAIУЪ2020ДкЗпјѕРыІјЅ«УЪ±ѕјѕ¶ИН¶ІъЎЈ
¶ФУЪРВµДspeedAIјЬ№№Ј¬Untether AIФЪДЬР§ЎўЧјИ·РФєННМНВБї·ЅГжФцјУБЛРн¶аёДЅшЎЈЛьГЗ°ьАЁµЪ¶юґъat-memoryјЖЛгјЬ№№Ј¬і¬№э1400ёцѕ№эУЕ»ЇµДRISC-Vґ¦АнЖчУл¶ЁЦЖЦёБоЈ¬ІўІЙУГёЎµгКэѕЭАаРНFP8Ј¬УГУЪФцЗїНЖАнјУЛЩЎЈХвР©Цё±к±кЦѕЧЕrunAIµДФКјРФДЬЈЁIntegerКэѕЭАаРНОЄ8ёцTOPS/WЈ©МбёЯµЅ30TFLOPS/WЈЁёЎµгјЖЛгЈ©ЎЈ
near-memory/·лЎ¤ЕµТБВьјЬ№№ґшАґµДНМНВБїєНДЬР§І»ЧгµИѕЦПЮРФКЗЦЪЛщЦЬЦЄµДЎЈПсMythicsХвСщµДРѕЖ¬ЙијЖ№«ЛѕТ»Ц±ФЪНЖ№гЛщОЅµДЎ°in-memoryјЖЛгЎ±ЎЈ
И»¶шЈ¬at-memoryјЖЛгКЗІ»Н¬µДЎЈBeachlerЈєЎ°ИЛГЗКФНјУГДڴ浥ԪАґЧціЛ»эЎЈЎ±ЛыЅвКНЛµЈ¬ОКМвКЗЎ°ДгКФНјК№УГДЈДвјјКхЈ¬ХвµјЦВБЛДЈДвР§У¦Ј¬ТвО¶ЧЕДгРиТЄФЪЛьЦЬО§°ІЧ°єЬ¶аІ№іҐµзВ·ЎЈЎ±ЛыІ№ідЛµЈ¬¶оНвµДµзВ·ІўІ»ДЬК№in-memoryјЖЛгЙи±ёёьёЯР§ЎЈ
Па±ИЦ®ПВЈ¬ФЪUntether AIЈ¬Ў°ОТГЗЅ«ґ¦АнФЄЛШЦ±ЅУёЅјУµЅ±кЧјSRAMµҐФЄЙПЎЈЎ±SpeedAIКЗКэЧЦ»ЇµДЈ¬ІЙУГБЛTSMC 7nm CMOSјјКхЎЈBeachlerІ№ідµАЈєЎ°ОТГЗО§ИЖSRAMЧцЛщУРµДКВЗйЈ¬ЧоґуПЮ¶ИµШЅµµН№¦єДЎЈОТГЗІ»Чц»єґжЈ¬ГїёцЛгКхВЯјµҐФЄ¶јУРЧФјєµДДЪґжЎЈЎ±
RISC-Vґ¦АнЖч
Untether AIµЪ¶юґъat-memoryјЖЛгјЬ№№µД¶АМШЦ®ґ¦ФЪУЪК№УГБЛRISC-Vґ¦АнЖчЎЈ
БЅДк°лЗ°Ј¬µ±BeachlerјУИлUntether AIК±Ј¬ЛыФшОКНЕ¶УЈєЎ°ОТЦЄµАДгГЗОЄКІГґІ»К№УГArmЈ¬µ«ДгГЗОЄКІГґІ»К№УГRISC-Vґ¦АнЖчДШЈїЎ±
¶ФУЪrunAIЈ¬Untether AI±ШРлЙијЖТ»ёц¶ЁЦЖµДRISCґ¦АнЖчЎЈBeachlerЛµЈ¬RISC-VµДЙъМ¬ПµНіЎ°»№Г»УРНкИ«РОіЙЎ±ЎЈ
¶ФУЪspeedAIЈ¬НЕ¶УЎ°МнјУБЛТ»¶СА©Х№ЦёБоЈ¬ОТГЗіЖЦ®ОЄЧФ¶ЁТеЦёБоЈ¬і¬№э20¶аёцЎ±ЎЈBeachlerЅвКНµАЈєЎ°ХвКЗМШ¶ЁУЪОТГЗХэФЪЅшРРµДјЖЛгАаРНµДЈ¬°ьАЁЙсѕНшВзјЖЛгЈ¬ТФј°ОТГЗµДat-memoryјЖЛгјЬ№№ЎЈЎ±
BeachlerЦёіцЈ¬ХвЦЦ¶ЁЦЖ»ЇКЗUntether AIјґК№ФЪЅсМмµДArmґ¦АнЖчЙПТІОЮ·ЁЧцµЅµДЈ¬ТтОЄArmІ»їЄ·ЕЖдЦёБојЇЎЈПа·ґЈ¬Ў°RISC-VФКРнХвЦЦЗйїц·ўЙъЎЈОТГЗДЬ№»УГОТГЗЧФјєµДЦёБоЙијЖЧФјєµД¶ЁЦЖґ¦АнЖчЈ¬µ«ОТГЗИФИ»К№УГRISC-VЦёБојЇјЬ№№ЎЈЎ±
MemoryBank
Untether AIµДµЪ¶юґъmemory bankЅ«К№УГRISC-Vґ¦АнЖчЈ¬УГУЪБй»оЎўёЯР§µДAIјУЛЩЎЈ
ѕЭUntether AIіЖЈ¬speedAIјЬ№№ЦРµДГїёцmemory bank¶јУР512ёцґ¦АнФЄЛШЈ¬Ц±ЅУБ¬ЅУµЅЧЁУГSRAMЎЈХвР©ґ¦АнФЄЛШЦ§іЦINT4ЎўFP8ЎўINT8єНBF16КэѕЭАаРНЈ¬ТФј°УГУЪЅЪДЬµДБгјмІвµзВ·Ј¬ІўЦ§іЦ2:1Ѕб№№ПЎКиРФЎЈ
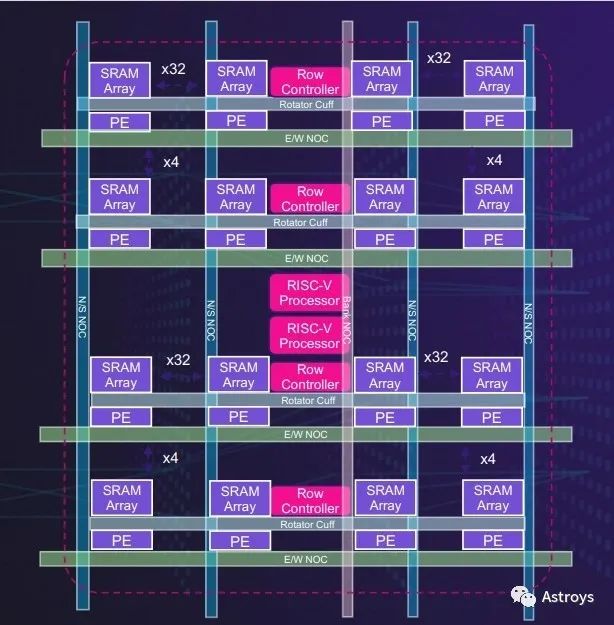
SpeedAIјУЛЩЖчК№УГЛ«¶аПЯіМRISC-VАґМбёЯmemory bankµД±аіМБй»оРФЎЈ
ТФ8РР64ёцґ¦АнФЄЛШЕЕБРЈ¬ГїТ»РРУРЧФјєµДЧЁУГРРїШЦЖЖчєНУІЅУПЯјхЙЩ№¦ДЬЈ¬ТФФКРн±аіМµДБй»оРФєН±дС№ЖчНшВ繦ДЬµДёЯР§јЖЛгЎЈ
БЅёцRISC-Vґ¦АнЖчЈЁГїёцґ¦АнЖч¶јУР20¶аМхУГУЪНЖАнјУЛЩµД¶ЁЦЖЦёБоЈ©№ЬАнёчРРЎЈёГ№«Лѕ±нКѕЈ¬ХвЦЦБй»оµДmemory bankїЙТФККУ¦Рн¶аІ»Н¬µДЙсѕНшВзјЬ№№Ј¬°ьАЁѕн»эЎўtransformerєННЖјцНшВзТФј°ПЯРФґъКэДЈРНЎЈ
ѕ«¶ИОКМв
іэБЛДЬР§Ј¬UntetherAIНЕ¶У»№ЧЁЧўУЪМбёЯЖдёЯЛЩAIРѕЖ¬µДAIѕ«¶ИЎЈBeachlerЛµЈєЎ°AIНЖАнРѕЖ¬µДУГ»§·ўПЦЈ¬µ±ЛыГЗЅшРРБї»ЇІЅЦиК±Ј¬УРК±»біцПЦІ»їЙЅУКЬµДЧјИ·РФЛрК§ЎЈ¶ФУЪДіР©У¦УГАґЛµЈ¬ХвГ»ОКМвЈ¬µ«µ±AIНЖАнјУЛЩЖчУГУЪНЖјцТэЗжєНЧФ¶ЇјЭК»ЖыіµК±ѕНІ»РРБЛЎЈЎ±
BeachlerЅвКНЛµЈ¬ФЪAIНЖјцТэЗжЦРЈ¬Ў°Из№ыДгµДЧјИ·ВКЅцПВЅµ0.1%Ј¬ѕНїЙДЬ»бЛрК§5000НтЦБ1ТЪГАФЄµД№гёжКХИлЈ¬ТтОЄДгПтПы·СХЯМṩБЛґнОуµД№гёж»тНЖјцЎЈЧјИ·РФєЬЦШТЄµДБнТ»ёцБмУтКЗЧФ¶ЇјЭК»ЖыіµЈ¬ТтОЄіµі§ФЪЧјИ·РФЙПІ»»бНЧРЎЈЎ±
ЅсДкФзР©К±єтЈ¬µ±NvidiaРыІјЖдHopperјЬ№№К±Ј¬ХвјТGPUѕЮН·МёµЅБЛТ»ЦЦРВµД8О»ёЎµгЈЁFP8Ј©КэѕЭАаРНЎЈУл±кЧјµДFP16СµБ·Па±ИЈ¬FP8ёсКЅµДНМНВБїФцјУБЛТ»±¶ЎЈ
SpeedAIТІФЪК№УГFP8ЎЈѕ№эЧФјєµДСРѕїЈ¬ёГНЕ¶УµГіцЅбВЫЈ¬БЅЦЦІ»Н¬µДFP8ёсКЅОЄAIНЖАнМṩБЛѕ«¶ИЎў·¶О§єНР§ВКµДЧојСЧйєПЎЈёГ№«ЛѕЅвКНЛµЈ¬Ѕ«4-ОІКэЈЁFP8pУГУЪѕ«¶ИЈ©єН3-ОІКэЈЁFP8rУГУЪ·¶О§Ј©ПаЅбєПЈ¬ОЄїзёчЦЦІ»Н¬НшВзµДНЖАнМṩБЛЧојСµДѕ«¶ИєННМНВБїЎЈЎ±
¶ФУЪѕн»эНшВзЈ¬Untether AIЙщіЖЈ¬К№УГFP8Ў°УлК№УГBF16КэѕЭАаРНПа±ИЈ¬ѕ«¶ИЛрК§І»µЅ1%µДК®·ЦЦ®Т»Ј¬НМНВБїєНДЬР§МбёЯБЛЛД±¶Ў±ЎЈ
І»КЗЎ°Т»µ¶ЗРЎ±
ОЄКІГґКРіЎРиТЄТ»ёцНЁУГµДAIНЖАнјУЛЩЖчЈїКЧПИЈ¬ТтОЄAIНЖАнјУЛЩУ¦УГµДіцПЦЎЈ
BeachlerЦёіцЈ¬іэБЛЦРСлјЖЛгПµНі±ШР봦АнФЅАґФЅ¶аёРЦЄКэѕЭµДЧФ¶ЇјЭК»ЖыіµЦ®НвЈ¬ЦЗДЬіЗКР»№ІїКрЧЕ№г·єµДјаїШКРіЎЎЈЎ°ЛыГЗРиТЄѕЫјЇКэ°ЩёцЙгПсН·АґЙъіЙКµК±їЙІЩЧчµДЗй±ЁЎЈЎ±ХвН¬СщККУГУЪѕьКВAIУ¦УГЈ¬АэИз¶Фї№ОЮИЛ»ъЎЈЎ°ЛыГЗКФНјУГІ»Н¬µДґ«ёРЖчЙЁГиМмїХЈ¬ТФ¶Фї№ОЮИЛ»ъЎЈ»тХЯЛыГЗ»бС°ХТАЧґпРЕєЕЈ¬ТФБЛЅвїХУтДЪµДЗйїцЎЈЎ±ЖдЛыµДAIНЖАнУ¦УГ°ьАЁЧФИ»УпСФґ¦АнјУЛЩЈ¬Untether AIЅ«ЖдјУИлµЅspeedAIЦРЎЈ
Yole IntelligenceµДSanchez±нКѕЈ¬НЁУГAIНЖАнµДЖдЛыУ¦УГ°ьАЁКµК±·ЦАаµДЦЗДЬБгКЫЎўЅрИЪБмУтµДУпТфµЅОД±ѕЎўЖуТµКэѕЭЦРРДєНёЯРФДЬјЖЛгБмУтµДЖшєтЅЁДЈЎЈ
ЖдґОЈ¬ЙсѕНшВзТФј°їН»§ФЪЦґРРAIК±К№УГЛьГЗµД·ЅКЅУРОЮКэЦЦ±д»ЇЎЈBeachlerЛµЈєЎ°ОТГЗТСѕ·ЦОцБЛ50¶аёцІ»Н¬µДїН»§ЙсѕНшВзЎЈГїёц¶јКЗІ»Н¬µДЎЈЛыГЗїЙДЬґУ»щ±ѕµДїЄКјЈ¬µ«ЛжєуЛыГЗ»бЧціцЎ°ККєПЛыГЗКэѕЭјЇєНСµБ·Ў±µДЖ«ІоЎЈ
ЧЫЙПЛщКцЈ¬ДгРиТЄµДКЗѕЯУРА©Х№РФєНБй»оРФµДAIНЖАнјУЛЩЖчјЬ№№ЎЈ
И»¶шЈ¬ДїЗ°Рн¶аAIУ¦УГ¶јТААµУЪПЦУРµДНЁУГCPUєНGPUЎЈ¶ФУЪ·юОсЖчЦРµДAIУ¦УГЈ¬SanchezЛµЈєЎ°ОТГЗїґµЅґуІї·ЦµДНЖАн¶јКЗУЙCPUНкіЙµДЎЈХвКЗТтОЄ¶ФНЖАнИООсµДРиЗуКЗБгРЗµДЎЈ¶ФУЪїН»§АґЛµЈ¬К№УГјёёцXeon»тEpycДЪєЛЅшРРїмЛЩНЖАн±ИК№УГХыёцУІјюіШёь·Ѕ±гЎЈЎ±
Untether AIГжБЩµДТ»ґуМфХЅКЗК¶±рРиТЄЧЁУГНЖАнУІјюµДПё·ЦКРіЎЎЈSanchezЛµЈєЎ°і¬А©Х№РФєН·юОсЖч·ЦАлїЙДЬ»бФцјУНЖАнЧЁУГУІјюУ¦¶ФМфХЅµД»ъ»бЎЈЎ±
ИнјюПЭЪе
ФшФЪAltera№¤Чч№эµДBeachlerЈЁѕНПсUntether AIЦґРРНЕ¶УµДРн¶аіЙФ±Т»СщЈ©єЬЗеіюИнјюєН№¤ѕЯБчµДЦШТЄРФЎЈѕНПсFPGAїН»§УцµЅБЛИнјю±аТлОКМв»тДвТйУІјюјЬ№№µДАыУГВКєЬІоТ»СщЈ¬Т»Р©AIРѕЖ¬їН»§ТІУцµЅБЛАаЛЖµДОКМвЈ¬Ў°ДгІ»ДЬ±аіМЈ¬»тХЯЛьМ«ДС±аіМЎЈЎ±
BeachlerЛµЈєЎ°ХэИзОТГЗФЪAlteraС§µЅµДЈ¬ОТГЗИ·±ЈОТГЗµД№¤ѕЯУАФ¶КЗРРТµЦРЧоєГµДЈ¬ОТГЗФЪUntether AIТІФЪЕ¬Б¦ЧцН¬СщµДКВЈ¬¶ФИнјюЅшРР№э¶ИН¶ЧКЎЈЎ±
И»¶шЈ¬Untether AI»№Г»УРМбЅ»ёшMLPerf¶ФЖдAIРѕЖ¬ЅшРР»щЧјІвКФЎЈBeachlerЛµЈ¬№«ЛѕµД№¤іМНЕ¶У±»50ёцїН»§АИҐЧц50ёцІ»Н¬µДЙсѕНшВзЈ¬ХвјТіхґґ№«ЛѕµДКЧТЄИООсКЗЎ°И·±ЈИнјюДЬ№»ФЛРРЛщУРХвР©І»Н¬µДЙсѕНшВзЎ±ЎЈ
ЛыЛµЈ¬ХвР©¶јКЗЎ°ИОєОAIіхґґ№«Лѕ¶ј»бУцµЅµДіЙі¤µДНґїаЎ±ЎЈµ«UntetherAIµДКЧёцAIјУЛЩЖчrunAIТСѕН¶ИлК№УГЈ¬ІўОЄїН»§ФЛРРНшВзЎЈ
УлґуБїПЦіЙµДМШ¶ЁУ¦УГAIНЖАнТэЗжІ»Н¬Ј¬Untether AIµДAIНЖАнјУЛЩЖч±»ЙијЖОЄНЁУГЙи±ёЎЈИ»¶шЈ¬ХвјТіхґґ№«ЛѕЛЖєх±»АПтБЛ¶аёц·ЅПтЈ¬ТФВъЧгїН»§µДІ»Н¬РиЗуЎЈUntether AIіЙ№¦µД№ШјьФЪУЪЛьµДИнјюєН±аіМ№¤ѕЯЈ¬ИГїН»§ФЪК№УГUntether AIµДјУЛЩЖчК±ДЬ№»¶АБўµШЧціцЧФјєµДЖ«ІоєНРЮёДЎЈ
ЙуєЛ±ајЈєБхЗе
-
ґ¦АнЖч
+№ШЧў
№ШЧў
68ОДХВ
19954дЇААБї
237517 -
cpu
+№ШЧў
№ШЧў
68ОДХВ
11116дЇААБї
218317 -
јУЛЩЖч
+№ШЧў
№ШЧў
2ОДХВ
828дЇААБї
39296 -
gpu
+№ШЧў
№ШЧў
28ОДХВ
4980дЇААБї
132120
·ўІјЖАВЫЗлПИ µЗВј
AIНЖАнµДґжґўЈ¬їґєГSRAMЈї
»ЄОЄББПа2025ЅрИЪAIНЖАнУ¦УГВдµШУл·ўХ№ВЫМі
РЕ¶шМ©ЎБDeepSeekЈєAIНЖАнТэЗжЗэ¶ЇНшВзЦЗДЬХп¶ПВхПт Ў°ЧФУъЎ±К±ґъ
°ЛМмИэґОКХ№єЈЎAMDКХ№єAIРѕЖ¬ЦЖФмЙМUntether AIНЕ¶УЈ¬ґМј¤ґґРВ

№ИёиµЪЖЯґъTPU IronwoodЙо¶ИЅв¶БЈєAIНЖАнК±ґъµДУІјюёпГь

Banana Pi ·ўІј BPI-AI2N & BPI-AI2N CarrierЈ¬ЦъБ¦ AI јЖЛгУлЗ¶ИлКЅїЄ·ў
Oracle Ул NVIDIA єПЧчЦъБ¦ЖуТµјУЛЩґъАнКЅ AI НЖАн

З¶ИлКЅAIјУЛЩЖчDRP-AI ПкПёЅйЙЬ
FPGA+AIНхХЁЧйєПИзєОЦШЛЬОґАґКАЅзЈєїґїґDeepSeek¶«·ЅЙсГШБ¦БїИзєОФ¤Ів......
µ±ОТОКDeepSeek AI±¬·ўК±ґъµДFPGAКЗ·сЦШТЄЈїґр°ёКЗ......
УўМШ¶ыGaudi 2D AIјУЛЩЖчЦъБ¦DeepSeek Janus ProДЈРНРФДЬМбЙэ
ЙъіЙКЅAIНЖАнјјКхЎўКРіЎУлОґАґ

Untether·ўІјИЛ№¤ЦЗДЬ(AI)РѕЖ¬
SiFive·ўІјMXПµБРёЯРФДЬAIјУЛЩЖчIP
AMDЦъБ¦HyperAccelїЄ·ўИ«РВAIНЖАн·юОсЖч






 №¤ЙМНшја
№¤ЙМНшја
ЖАВЫ