 AI推理的存储,看好SRAM?
AI推理的存储,看好SRAM?

电子发烧友网报道(文/黄晶晶)近几年,生成式AI引领行业变革,AI训练率先崛起,带动高带宽内存HBM一飞冲天。但我们知道AI推理的广泛应用才能推动AI普惠大众。在AI推理方面,业内巨头、初创公司等都看到了其前景并提前布局。AI推理也使得存储HBM不再是唯一热门,更多存储芯片与AI推理芯片结合,拥有了市场机会。
已经有不少AI推理芯片、存算一体芯片将SRAM替代DRAM,从而获得更快的访问速度、更低的刷新延迟等。
静态随机存取存储器(Static Random-Access Memory,SRAM)是随机存取存储器的一种。这种存储器只要保持通电,里面储存的数据就可以恒常保持。相对之下,动态随机存取存储器(DRAM)里面所储存的数据就需要周期性地更新。但当电力供应停止时,SRAM储存的数据还是会消失,这与在断电后还能储存资料的ROM或闪存不同。
SRAM具有较高的性能,但SRAM的集成度较低,功耗较DRAM大,SRAM需要很大的面积。同样面积的硅片可以做出更大容量的DRAM,因此SRAM显得更贵。SRAM可作为置于CPU与主存间的高速缓存,不需要定期刷新,响应速度非常快,可用于CPU的一级缓冲、二级缓冲。
GroqLPU近存计算
在AI推理大潮下,Groq公司开发的语言处理单元(Language Processing Unit,即LPU),以其独特的架构,带来了极高的推理性能的表现。
Groq的芯片采用14nm制程,搭载了230MB SRAM以保证内存带宽,片上内存带宽达80TB/s。
SRAM 的访问速度比 DRAM 快得多,这使得它在某些计算密集型应用中表现得非常出色。Groq LPU 芯片采用大容量 SRAM内存有助于提高机器学习和人工智能等计算密集型工作负载的效率。
Groq成立于 2016 年,总部位于美国加利福尼亚州山景城,是一家 AI 推理芯片厂商。该公司核心团队来源于谷歌最初的张量处理单元(TPU)工程团队。Groq 创始人兼CEO Jonathan Ross是谷歌TPU项目的核心研发人员。
2024年8月,Groq 在最新一轮融资中筹集了 6.4 亿美元,由 BlackRock Inc. 基金领投,并得到了思科和三星投资部门的支持。
2024 年 12 月Groq在沙特阿拉伯达曼构建了中东地区最大的推理集群,该集群包括了 19000 个Groq LPU,并在 8 天内上线。
今年2月,Groq成功从沙特阿拉伯筹集 15 亿美元融资,用于扩展其位于沙特阿拉伯的 AI 基础设施。
AxeleraAIPU芯片:内存计算+RISC-V架构
Axelera公司介绍,内存计算是一种完全不同的数据处理方法,在这种方法中,存储器设备的横杆阵列可以用来存储矩阵,并在没有中间数据移动的情况下“就地”执行矩阵向量乘法。专有的数字内存计算(D-IMC)技术是实现高能效和卓越性能的关键。基于SRAM(静态随机访问存储器)和数字计算相结合,每个存储单元有效地成为一个计算单元。这从根本上增加了每个计算机周期的操作数(每个存储单元每个周期一次乘法和一次累加),而不受噪音或较低精度等问题的影响。
已经有不少AI推理芯片、存算一体芯片将SRAM替代DRAM,从而获得更快的访问速度、更低的刷新延迟等。
静态随机存取存储器(Static Random-Access Memory,SRAM)是随机存取存储器的一种。这种存储器只要保持通电,里面储存的数据就可以恒常保持。相对之下,动态随机存取存储器(DRAM)里面所储存的数据就需要周期性地更新。但当电力供应停止时,SRAM储存的数据还是会消失,这与在断电后还能储存资料的ROM或闪存不同。
SRAM具有较高的性能,但SRAM的集成度较低,功耗较DRAM大,SRAM需要很大的面积。同样面积的硅片可以做出更大容量的DRAM,因此SRAM显得更贵。SRAM可作为置于CPU与主存间的高速缓存,不需要定期刷新,响应速度非常快,可用于CPU的一级缓冲、二级缓冲。
GroqLPU近存计算
在AI推理大潮下,Groq公司开发的语言处理单元(Language Processing Unit,即LPU),以其独特的架构,带来了极高的推理性能的表现。
Groq的芯片采用14nm制程,搭载了230MB SRAM以保证内存带宽,片上内存带宽达80TB/s。
SRAM 的访问速度比 DRAM 快得多,这使得它在某些计算密集型应用中表现得非常出色。Groq LPU 芯片采用大容量 SRAM内存有助于提高机器学习和人工智能等计算密集型工作负载的效率。
Groq成立于 2016 年,总部位于美国加利福尼亚州山景城,是一家 AI 推理芯片厂商。该公司核心团队来源于谷歌最初的张量处理单元(TPU)工程团队。Groq 创始人兼CEO Jonathan Ross是谷歌TPU项目的核心研发人员。
2024年8月,Groq 在最新一轮融资中筹集了 6.4 亿美元,由 BlackRock Inc. 基金领投,并得到了思科和三星投资部门的支持。
2024 年 12 月Groq在沙特阿拉伯达曼构建了中东地区最大的推理集群,该集群包括了 19000 个Groq LPU,并在 8 天内上线。
今年2月,Groq成功从沙特阿拉伯筹集 15 亿美元融资,用于扩展其位于沙特阿拉伯的 AI 基础设施。
AxeleraAIPU芯片:内存计算+RISC-V架构
Axelera公司介绍,内存计算是一种完全不同的数据处理方法,在这种方法中,存储器设备的横杆阵列可以用来存储矩阵,并在没有中间数据移动的情况下“就地”执行矩阵向量乘法。专有的数字内存计算(D-IMC)技术是实现高能效和卓越性能的关键。基于SRAM(静态随机访问存储器)和数字计算相结合,每个存储单元有效地成为一个计算单元。这从根本上增加了每个计算机周期的操作数(每个存储单元每个周期一次乘法和一次累加),而不受噪音或较低精度等问题的影响。
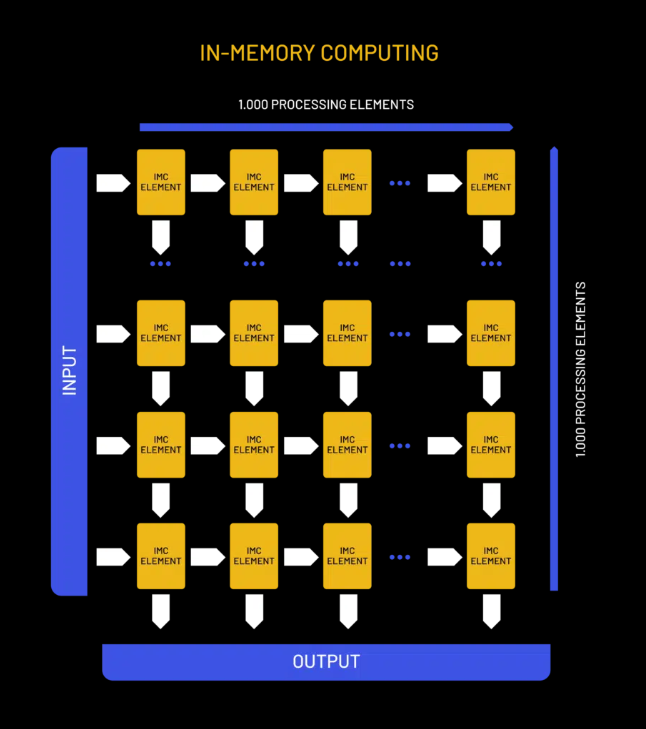
Axelera的AIPU芯片采用了创新的内存计算技术。与传统的磁盘存储相比,内存计算将数据存储在主内存(RAM)中,从而加快了数据处理速度。这一技术使得Axelera的芯片在提供高计算性能的同时,能以更低的成本和能耗来进行边缘AI计算。该芯片还采用了开源的RISC-V指令集架构(ISA)。RISC-V作为一种低成本、高效且灵活的ISA,允许根据特定的应用需求进行定制。它为Axelera提供了极大的设计自由度和创新空间。
去年,Axelera获得了来自三星电子风险投资部门三星Catalyst的大力支持,成功筹集了6800万美元,至此Axelera的总融资额已达到1.2亿美元。新投资者包括三星基金、欧洲创新委员会基金、创新产业战略伙伴关系基金和Invest-NL。
EnCharge AI:模拟存内计算
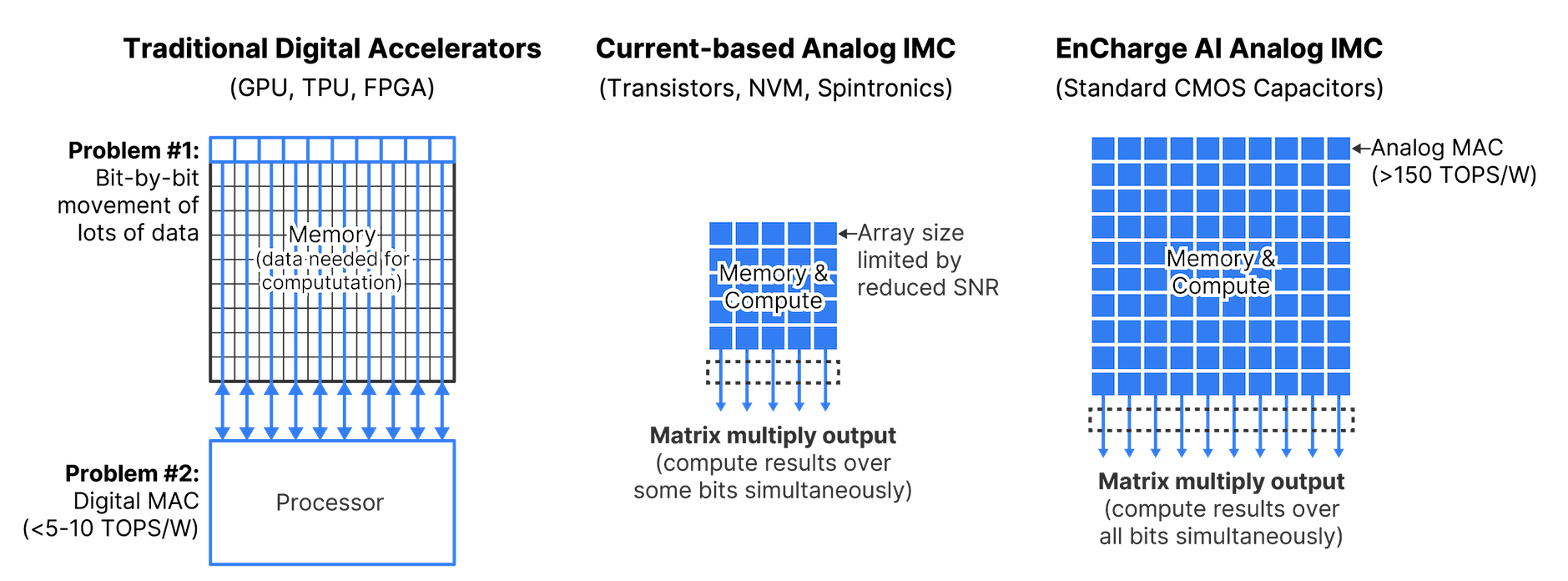
AI 芯片初创公司 EnCharge AI表示,已开发出一种用于 AI 推理的新型内存计算架构,EnCharge AI的核心技术是基于模拟存内计算的AI芯片。这种创新的芯片设计采用"基于电荷的存储器",通过读取存储平面上的电流而非单个比特单元来处理数据,使用更精确的电容器替代了传统的半导体。
与GPU等数字加速器相比,每瓦性能提高了 20 倍。EnCharge AI的推理芯片仅需一瓦的功率就能以8位元精度提供150 TOPS的AI运算。
EnCharge AI源自普林斯顿大学,该公司创始人兼CEO Naveen Verma的相关研究项目涉及到内存计算。用于机器学习计算的内存计算采用在RAM中运行计算的方式,以减少存储设备带来的延迟。
今年初,EnCharge AI完成超额认购的1亿美元b轮融资。此轮超额认购融资使EnCharge AI的总融资额超过1.44亿美元,将推动其首款以客户端运算为主的AI加速器产品,并在2025年实现商业化。
d-Matrix:数字内存计算DIMC架构
d-Matrix采用数字内存计算(DIMC)的引擎架构将计算移动到RAM(内存)附近,该数字存算一体技术将存储器与计算单元中的乘法累加器(MAC)进行了合并,获得了更大的计算带宽和效率,降低延迟,减少能耗。首批采用d-Matrix的DIMC架构的产品Jayhawk II处理器,包含约165亿晶体管的Chiplet。每个Jayhawk II Chiplet都包含一个RISC-V核心对Chiplet进行管理,每个核心有八个并行操作的DIMC单元。
去年底d-Matrix首款人工智能芯片Corsair开始出货。每张Corsair卡由多个DIMC计算核心驱动,具有2400 TFLOP的8位峰值计算能力、2GBSRAM和高达256GB的LPDDR6。
d-Matrix公司是一家位于加利福尼亚州圣克拉拉市的初创公司,专注于人工智能芯片的研发。该公司的主要产品是针对数据中心和云计算中的AI服务器设计的芯片,旨在优化人工智能推理工作负载。d-Matrix公司已经获得了多家知名投资机构的支持,包括微软风险投资部门、新加坡投资公司淡马锡、Palo Alto Networks等,D-Matrix曾在2022年4月获得了4400万美元融资,由 M12 和韩国半导体制造商 SK 海力士公司领投。累计融资超过1.6亿美元。
虽然说SRAM的拥有成本比较高,但其在AI推理运算中能够减少数据来回传输的延迟,避免拖慢整个AI处理的速度。在AI推理的浪潮下,SRAM将发挥更大的作用。还有哪些存储芯片因AI推理而赢得机会,我们将持续关注报道。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
存储
+关注
关注
13文章
4542浏览量
87595 -
sram
+关注
关注
6文章
787浏览量
116220 -
AI
+关注
关注
88文章
35476浏览量
281298
发布评论请先 登录
相关推荐
热点推荐
AI驱动新型存储器技术,国内新兴存储企业进阶
为了加速AI的训练与推理应用。但另一方面,新型存储也在AI时代扮演越来越重要的角色,最近国内新兴存储企业也将目光投向于此,并推出新产品等,以
发表于 10-16 08:10
?1501次阅读

信而泰×DeepSeek:AI推理引擎驱动网络智能诊断迈向 “自愈”时代
DeepSeek-R1:强大的AI推理引擎底座DeepSeek是由杭州深度求索人工智能基础技术研究有限公司开发的新一代AI大模型。其核心优势在于强大的推理引擎能力,融合了自然语言处理(
发表于 07-16 15:29
谷歌第七代TPU Ironwood深度解读:AI推理时代的硬件革命
谷歌第七代TPU Ironwood深度解读:AI推理时代的硬件革命 Google 发布了 Ironwood,这是其第七代张量处理单元 (TPU),专为推理而设计。这款功能强大的 AI

英伟达GTC25亮点:NVIDIA Blackwell Ultra 开启 AI 推理新时代
英伟达GTC25亮点:NVIDIA Blackwell Ultra 开启 AI 推理新时代
英伟达GTC25亮点:NVIDIA Dynamo开源库加速并扩展AI推理模型
DeepSeek-R1 上的吞吐量提高了 30 倍 NVIDIA 发布了开源推理软件 NVIDIA Dynamo,旨在以高效率、低成本加速并扩展 AI 工厂中的 AI 推理模型。 作
NVIDIA 与行业领先的存储企业共同推出面向 AI 时代的新型企业基础设施
存储提供商构建搭载 AI 查询智能体的基础设施,利用 NVIDIA 计算、网络和软件,针对复杂查询进行推理并快速生成准确响应 ? 美国加利福尼亚州圣何塞 —— GTC —— 太平洋时间 2025 年
发表于 03-19 10:11
?262次阅读

AI变革正在推动终端侧推理创新
尖端AI推理模型DeepSeek R1一经问世,便在整个科技行业引起波澜。因其性能能够媲美甚至超越先进的同类模型,颠覆了关于AI发展的传统认知。
不再是HBM,AI推理流行,HBF存储的机会来了?
NAND闪存和高带宽存储器(HBM)的特性,能更好地满足AI推理的需求。 ? HBF的堆叠设计类似于HBM,通过硅通孔(TSVs)将多个高性能闪存核心芯片堆叠,连接到可并行访问闪存子阵列的逻辑芯片上。也就是基于 SanDisk


生成式AI推理技术、市场与未来
OpenAI o1、QwQ-32B-Preview、DeepSeek R1-Lite-Preview的相继发布,预示着生成式AI研究正从预训练转向推理(Inference),以提升AI逻辑推理

AI推理CPU当道,Arm驱动高效引擎
AI的训练和推理共同铸就了其无与伦比的处理能力。在AI训练方面,GPU因其出色的并行计算能力赢得了业界的青睐,成为了当前AI大模型最热门的芯片;而在

NVIDIA助力丽蟾科技打造AI训练与推理加速解决方案
丽蟾科技通过 Leaper 资源管理平台集成 NVIDIA AI Enterprise,为企业和科研机构提供了一套高效、灵活的 AI 训练与推理加速解决方案。无论是在复杂的 AI 开发

李开复:中国擅长打造经济实惠的AI推理引擎
10月22日上午,零一万物公司的创始人兼首席执行官李开复在与外媒的交流中透露,其公司旗下的Yi-Lightning(闪电模型)在推理成本上已实现了显著优势,比OpenAI的GPT-4o模型低了31倍。他强调,中国擅长打造经济实惠的AI推
AMD助力HyperAccel开发全新AI推理服务器
HyperAccel 是一家成立于 2023 年 1 月的韩国初创企业,致力于开发 AI 推理专用型半导体器件和硬件,最大限度提升推理工作负载的存储器带宽使用,并通过将此解决方案应用于






 工商网监
工商网监
评论