 如何优雅地使用bert处理长文本
如何优雅地使用bert处理长文本

这是今年清华大学及阿里巴巴发表在NIPS 2020上的一篇论文《CogLTX: Applying BERT to Long Texts》,介绍了如何优雅地使用bert处理长文本。作者同时开源了不同NLP任务下使用COGLTX的代码:
论文题目:
CogLTX: Applying BERT to Long Texts
论文链接:
http://keg.cs.tsinghua.edu.cn/jietang/publications/NIPS20-Ding-et-al-CogLTX.pdf
Github:
https://github.com/Sleepychord/CogLTX
bert在长文本处理一般分为三种方法[1]:
截断法;
Pooling法;
压缩法。
该论文就是压缩法的一种,是三种方法中最好的。我们在科研和工作中都会遇到该问题,例如我最近关注的一个文本分类比赛:
面向数据安全治理的数据内容智能发现与分级分类 竞赛 - DataFountain[2].
其文本数据长度就都在3000左右,无法将其完整输入bert,使用COGLTX就可以很好地处理该问题,那么就一起来看看该论文具体是怎么做的吧。
1.背景
基于以下情形:
bert作为目前最优秀的PLM,不用是不可能的;
长文本数据普遍存在,且文本中包含的信息非常分散,难以使用滑动窗口[3]截断。
而由于bert消耗计算资源和时间随着token的长度是平方级别增长的,所以其无法处理太长的token,目前最长只支持512个token,token过长也很容易会内存溢出,所以在使用bert处理长文本时需要设计巧妙的方法来解决这个问题。

2.提出模型
COGLTX模型在三类NLP任务中的结构如下:
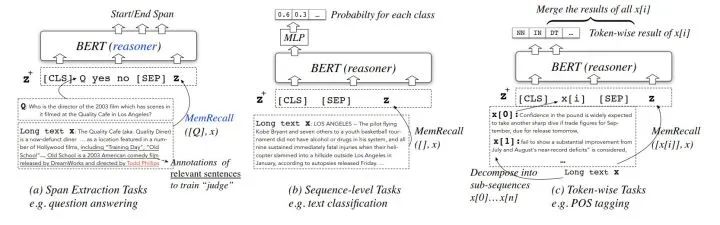
首先假设:存在短文本 可以完全表达原长文本 的语义:
那么令 代替 输入原来的模型即可,那么怎么找到这个 呢
1、使用动态规划算法将长文本 划分为文本块集合 ;
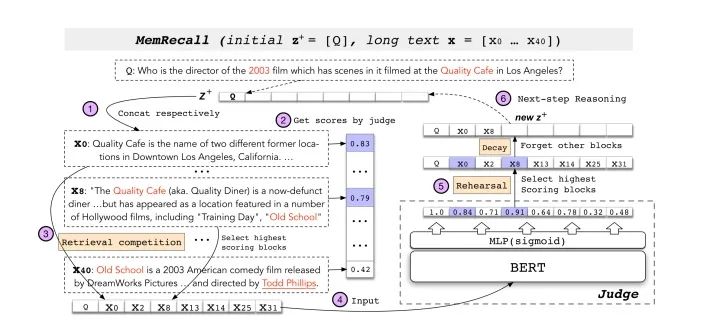
2、使用MemRecall对原长句中的子句进行打分,MemRecall结构如图,而表现如下式:
从而选择出分数最高的子句组成 再进行训练,这样一来的话,COGLTX相当于使用了了两个bert,MemRecall中bert就是负责打分,另一个bert执行原本的NLP任务。
可以发现刚才找到 例子将问题Q放在了初始化 的开头,但是并不是每个NLP任务都可以这么做,分类的时候就没有类似Q的监督,这时候COGLTX采用的策略是将每个子句从原句中移除判断其是否是必不可少的(t是一个阈值):
作者通过设计不同任务下的MemRecall实现了在长文本中使用bert并通过实验证明了方法的有效性。
3.实验
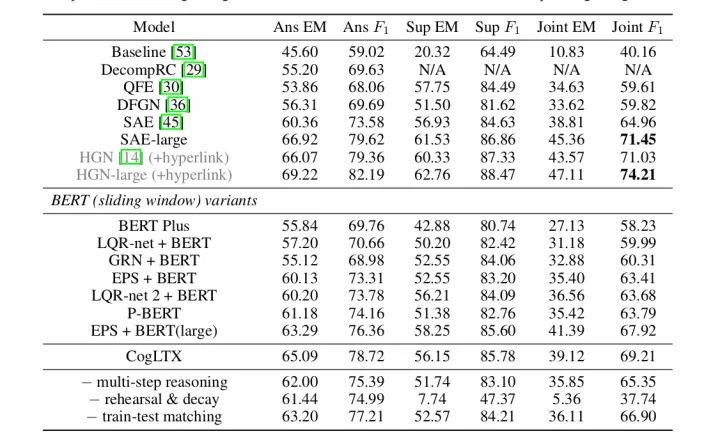
通过多维度地对比,证明了本文提出算法的有效性。
参考文献
[1]https://zhuanlan.zhihu.com/p/88944564
[2]https://www.datafountain.cn/competitions/471
[3]Z. Wang, P. Ng, X. Ma, R. Nallapati, and B. Xiang. Multi-passage bert: A globally normalized bert model for open-domain question answering. arXiv preprint arXiv:1908.08167, 2019.
责任编辑:xj
原文标题:【NIPS 2020】通过文本压缩,让BERT支持长文本
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
文本
+关注
关注
0文章
119浏览量
17535 -
nlp
+关注
关注
1文章
490浏览量
22728
原文标题:【NIPS 2020】通过文本压缩,让BERT支持长文本
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
飞书开源“RTV”富文本组件 重塑鸿蒙应用富文本渲染体验
推荐!如何优雅地摆好PCB丝印?
把树莓派打造成识别文本的“神器”!

?VLM(视觉语言模型)?详细解析

飞凌RK3588开发板上部署DeepSeek-R1大模型的完整指南(一)

BQ3588/BQ3576系列开发板深度融合DeepSeek-R1大模型
阿里云通义开源长文本新模型Qwen2.5-1M
【6千字长文】车载芯片的技术沿革与趋势分析

Linux三剑客之Sed:文本处理神器

如何优化自然语言处理模型的性能
如何使用自然语言处理分析文本数据
图纸模板中的文本变量
如何在文本字段中使用上标、下标及变量

如何掌握Linux文本处理
内置误码率测试仪(BERT)和采样示波器一体化测试仪器安立MP2110A






 工商网监
工商网监
评论