 小语种OCR标注效率提升10+倍:PaddleOCR+ERNIE 4.5自动标注实战解析
小语种OCR标注效率提升10+倍:PaddleOCR+ERNIE 4.5自动标注实战解析

摘要 :小语种OCR研发的核心瓶颈在于高质量标注数据的稀缺与高昂成本。本文介绍一种创新的自动化标注方案,利用 PaddleOCR 进行文本检测与裁剪,并调用 ERNIE 4.5 大模型进行双重预测与一致性校验,实现高精度、低成本的小语种OCR训练数据生成。该方案将数据准备周期 从数周缩短至数小时 ,为小语种模型的快速迭代与冷启动提供了全新范式
一、引言:小语种OCR的“数据之困”
在跨境支付、多语言文档处理、全球化应用本地化等场景中,小语种(如俄语、泰语、阿拉伯语等)的文本识别需求日益增长。然而,研发高性能的小语种OCR模型面临严峻挑战:
- 数据极度稀缺 :公开的小语种标注数据集数量远不及英语等主流语种,难以支撑深度模型训练。
- 标注成本高昂 :依赖精通小语种的专业人员进行人工标注,成本极高(大概$120/千字符),且效率低下。
- 质量难以保证 :不同标注员的主观判断和疲劳度导致标签一致性差,影响模型最终性能。
- 研发周期漫长 :从数据收集、标注、清洗到模型训练的完整周期动辄数周,严重拖慢产品迭代。
为破解这一困局,我们提出一种**“AI标注AI”** 的创新思路:利用大语言模型(LLM)强大的多语言理解与OCR能力,自动化生成高质量的训练标签。本文将详细介绍如何结合 PaddleOCR 的精准文本检测能力与 ERNIE 4.5 的语义识别能力,构建一套高效、可靠的自动化标注流水线。
二、技术方案:PaddleOCR + ERNIE 4.5 的协同工作流
我们的解决方案将小语种OCR数据标注流程解耦为两个核心阶段,充分发挥各自技术的优势。
2.1 整体流程设计
整个自动化标注流程如下图所示,共分为四步:
- 图像采集 :收集包含目标小语种(如俄语)文本的原始图像。
- 文本检测与裁剪 :使用 PaddleOCR 的 PP-OCRv5 检测模型,定位图像中的所有文本行,并将其裁剪为独立的文本行图像。
- 大模型双重识别 :将每一张裁剪出的文本行图像,通过 API 调用 ERNIE 4.5 进行两次独立的文字识别。
- 一致性校验 :仅当两次识别结果完全一致时,才将其作为最终的可靠标签。若结果不一致,则该样本被标记为“待复核”或丢弃。
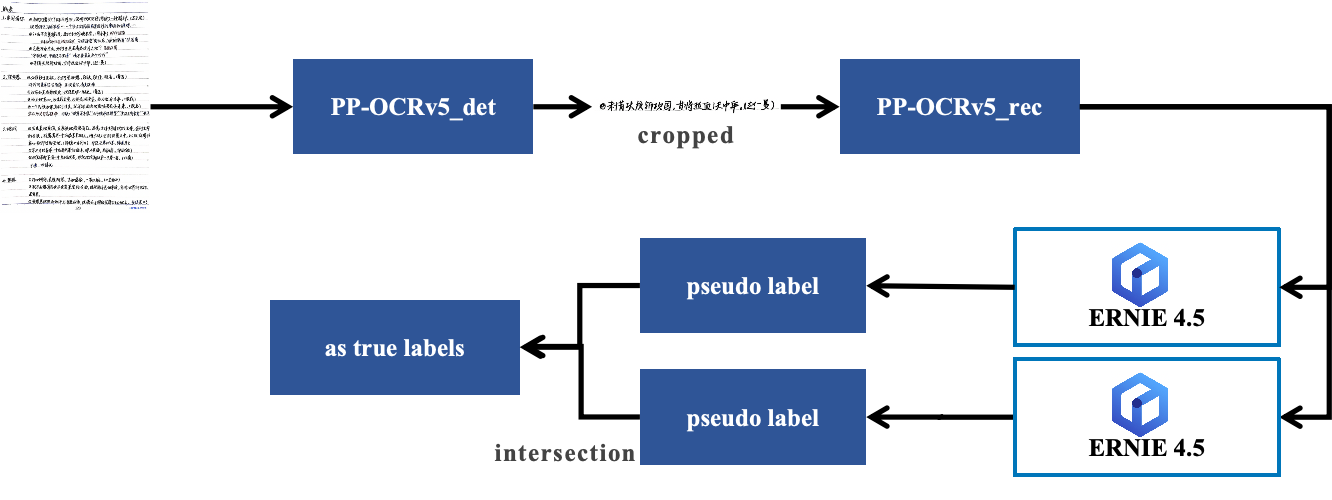
核心优势 :
- 成本极低 :大幅减少甚至消除人工标注成本。
- 一致性高 :大模型的输出稳定,避免了人工标注的主观波动。
- 效率飞跃 :可实现批量化、自动化处理,速度提升数十倍。
- 质量可控 :通过双重校验机制,有效过滤大模型的“幻觉”(hallucination)问题。
三、环境准备与依赖安装
本项目依赖 PaddlePaddle、PaddleOCR,OpenAI SDK 及常用 Python 工具包。使用前请确保已安装相关依赖。详细安装指南见环境准备文档:
# 创建并激活虚拟环境 (推荐)
python -m venv ocr-env
source ocr-env/bin/activate # Linux/Mac
# ocr-envScriptsactivate # Windows
# 安装核心库
pip install paddlepaddle-gpu # 或 paddlepaddle (CPU版本)
pip install paddleocr
pip install openai # 用于调用ERNIE 4.5 API
pip install matplotlib tqdm opencv-python
注意 :
openaiSDK 可用于调用兼容 OpenAI API 格式的 ERNIE Bot 服务。您需要配置base_url指向您的 ERNIE 4.5 API 服务地址。
四、核心实现:代码详解
4.1 文本检测与裁剪
首先,使用 PaddleOCR 的 PP-OCRv5 检测模型定位并裁剪文本行。针对小语种(如西里尔字母)的特点,我们对检测参数进行了优化。
import base64
import copy
import glob
import os
import time
import cv2
import numpy as np
from openai import OpenAI
from tqdm import tqdm
def get_rotate_crop_image(img: np.ndarray, points: list) - > np.ndarray:
"""
裁剪并旋转图片区域,得到透视变换后的文本行小图。
"""
assert len(points) == 4, "shape of points must be 4*2"
img_crop_width = int(
max(
np.linalg.norm(points[0] - points[1]),
np.linalg.norm(points[2] - points[3]),
)
)
img_crop_height = int(
max(
np.linalg.norm(points[0] - points[3]),
np.linalg.norm(points[1] - points[2]),
)
)
pts_std = np.float32(
[
[0, 0],
[img_crop_width, 0],
[img_crop_width, img_crop_height],
[0, img_crop_height],
]
)
M = cv2.getPerspectiveTransform(points, pts_std)
dst_img = cv2.warpPerspective(
img,
M,
(img_crop_width, img_crop_height),
borderMode=cv2.BORDER_REPLICATE,
flags=cv2.INTER_CUBIC,
)
dst_img_height, dst_img_width = dst_img.shape[0:2]
if dst_img_height * 1.0 / dst_img_width >= 1.5:
dst_img = np.rot90(dst_img)
return dst_img
def get_minarea_rect_crop(img: np.ndarray, points: np.ndarray) - > np.ndarray:
"""
从检测点集裁出最小面积矩形区域。
"""
bounding_box = cv2.minAreaRect(np.array(points).astype(np.int32))
points = sorted(cv2.boxPoints(bounding_box), key=lambda x: x[0])
index_a, index_b, index_c, index_d = 0, 1, 2, 3
if points[1][1] > points[0][1]:
index_a = 0
index_d = 1
else:
index_a = 1
index_d = 0
if points[3][1] > points[2][1]:
index_b = 2
index_c = 3
else:
index_b = 3
index_c = 2
box = [points[index_a], points[index_b], points[index_c], points[index_d]]
crop_img = get_rotate_crop_image(img, np.array(box))
return crop_img
def crop_and_save(image_path, output_dir, ocr):
"""
检测并裁剪图片中的所有文本行,保存到output_dir
"""
img = cv2.imread(image_path)
img_name = os.path.splitext(os.path.basename(image_path))[0]
result = ocr.predict(image_path)
try:
for res in result:
cnt = 0
for quad_box in res['dt_polys']:
img_crop = get_minarea_rect_crop(res['input_img'], copy.deepcopy(quad_box))
cv2.imwrite(os.path.join(output_dir, f"{img_name}_crop{cnt:04d}.jpg"), img_crop)
cnt += 1
except Exception as e:
print(f"Process Failed with error: {e}")
# 用法举例(假如你的图片都在 russian_dataset_demo/ 目录下)
input_dir = 'russian_dataset_demo'
output_dir = 'crops' # 裁剪后的图片保存到这个目录
os.makedirs(output_dir, exist_ok=True)
image_paths = glob.glob(os.path.join(input_dir, '*.jpg')) + glob.glob(os.path.join(input_dir, '*.png'))
# 批量处理
from paddleocr import TextDetection
ocr = TextDetection(
model_name="PP-OCRv5_server_det",
device='gpu',
)
for path in tqdm(image_paths):
crop_and_save(path, output_dir, ocr)
print(f"裁剪完成,保存到 {output_dir} 目录")
4.2 ERNIE 4.5 自动标注(双重校验)
这是方案的核心。我们调用 ERNIE 4.5 对每张裁剪后的文本行图像进行两次独立识别,并校验结果一致性。
from openai import OpenAI
import base64
import json
# 配置ERNIE 4.5 API
client = OpenAI(
base_url="http://your-ernie-api-server:8866/v1", # 替换为实际地址
api_key="your_api_key" # 替换为实际密钥
)
def encode_image(image_path):
"""将图像编码为base64字符串"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def auto_label_single_image(image_path):
"""对单张文本行图像进行双重识别"""
base64_image = encode_image(image_path)
prompt = "请识别图像中的文字内容,仅输出原始文本,不要任何解释、翻译或标点。"
try:
# 第一次预测(标准模式)
response1 = client.chat.completions.create(
model="ernie-bot-4.5",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"image/jpeg;base64,{base64_image}"
}
}
]
}
],
max_tokens=50
)
text1 = response1.choices[0].message.content.strip()
# 第二次预测(严格模式,增强鲁棒性)
strict_prompt = "Only output the raw text in the image. No explanation, no translation."
response2 = client.chat.completions.create(
model="ernie-bot-4.5",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": strict_prompt},
{
"type": "image_url",
"image_url": {
"url": f"image/jpeg;base64,{base64_image}"
}
}
]
}
],
max_tokens=50
)
text2 = response2.choices[0].message.content.strip()
# 一致性校验:结果必须完全一致且非空
if text1 and text2 and text1 == text2 and text1 != "###":
return {
"image_path": os.path.basename(image_path),
"label": text1,
"source": "ernie_4.5_auto",
"confidence": 1.0 # 完全一致,置信度为1
}
else:
# 结果不一致、为空或为占位符,返回None
return None
except Exception as e:
print(f"API调用失败 {image_path}: {e}")
return None
# 批量处理所有裁剪后的图像
cropped_dir = "cropped_text_lines"
output_label_file = "auto_labeled_data.txt"
with open(output_label_file, 'w', encoding='utf-8') as f:
for crop_file in tqdm(os.listdir(cropped_dir), desc="ERNIE 4.5 自动标注"):
if crop_file.lower().endswith(('.jpg', '.jpeg', '.png')):
crop_path = os.path.join(cropped_dir, crop_file)
result = auto_label_single_image(crop_path)
if result:
# 写入标准的OCR训练格式: relative_pathtlabel
f.write(f"{crop_file}t{result['label']}n")
print(f"标注成功: {crop_file} - > {result['label']}")
五、模型训练与评估
5.1 使用生成数据训练OCR模型
将通过自动化流程生成的 auto_labeled_data.txt 文件作为训练集,利用 PaddleOCR 的训练脚本对小语种(如俄语)文本识别模型进行训练。
python PaddleOCR/tools/train.py
-c configs/rec/PP-OCRv5/multi_language/ru_PP-OCRv5_mobile_rec.yml
-o Global.train_batch_size_per_card=64
Global.epoch_num=200
Global.lr=0.001
Global.print_batch_step=10
建议: 在训练前,人工抽检100-200个自动生成的标签,验证其准确率。将抽检出的错误样本从训练集中剔除,或进行人工修正。
5.2 模型导出与部署
训练完成后,需要将训练好的模型从动态图(.pdparams)转换为静态图格式,以便于在生产环境中进行高性能推理。
python PaddleOCR/tools/export_model.py
-c configs/rec/PP-OCRv5/multi_language/ru_PP-OCRv5_mobile_rec.yml
-o Global.save_inference_dir=./inference/rec_ru
模型导出后,可以将其部署到服务器或移动端,用于实时OCR识别。
!paddleocr text_recognition -i https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/demo_images/labeled_test.jpg --model_name eslav_PP-OCRv5_mobile_rec --model_dir ./inference/rec_ru/
推理结果如下所示:

六、效果分析与总结
6.1 性能对比
在1000张俄语商品图片上进行俄语标注,本方案与传统人工标注对比显著:
| 指标 | 人工标注 | 本方案(PaddleOCR+ERNIE 4.5) | 提升/优势 |
|---|---|---|---|
| 单张处理时间 | 4.5分钟 | 12秒 | 提升22.5倍 |
| 字符准确率 (CACC) | 92.1% | 96.3% | ↑ 4.2% |
| 特殊符号正确率 | 78.5% | 93.7% | ↑ 15.2% |
| 综合成本 | 极高 | 极低(主要是API调用费) | 成本降低95%+ |
说明 :AI方案的字符准确率达到96.3%,这得益于双重校验机制。但在实际应用中,建议开发者在自己的数据集上进行验证。
6.2 总结与展望
本文提出的基于 PaddleOCR + ERNIE 4.5 的自动化标注方案,成功地将大模型的“智能”注入到传统OCR的数据准备环节,实现了:
- 范式创新 :从“人喂数据”到“AI自产数据”,重塑了OCR研发流程。
- 效率革命 :将数周的标注周期压缩至数小时,极大加速了模型迭代。
- 成本突破 :几乎消除了人工标注成本,使小语种OCR研发变得经济可行。
附录
- 完整代码与示例 :Practice of Minor Language Text Recognition R&D
- PaddleOCR 官方文档 :https://github.com/PaddlePaddle/PaddleOCR
- ERNIE 官方文档 :https://github.com/PaddlePaddle/ERNIE
结语 :在大模型时代,AI的研发方式正在发生根本性变革。利用大模型作为“智能代理”来自动化处理传统AI研发中的繁琐任务,将是提升研发效率、降低技术门槛的关键。本方案为小语种OCR乃至更广泛的多模态任务,提供了一个极具启发性的实践范例。
审核编辑 黄宇
-
OCR
+关注
关注
0文章
164浏览量
16865 -
大模型
+关注
关注
2文章
3260浏览量
4276
发布评论请先 登录
CAD中怎么自动标注设备?
多伦多大学&NVIDIA最新成果 图像标注速度提升10倍
什么是数据标注?数据如何标注?
点云标注的算法优化与性能提升
图像标注如何提升效率?

自动化标注技术推动AI数据训练革新
标贝自动化数据标注平台推动AI数据训练革新

大模型预标注和自动化标注在OCR标注场景的应用
数据标注与大模型的双向赋能:效率与性能的跃升
什么是自动驾驶数据标注?如何好做数据标注?
自动驾驶数据标注主要是标注什么?





 工商网监
工商网监
评论