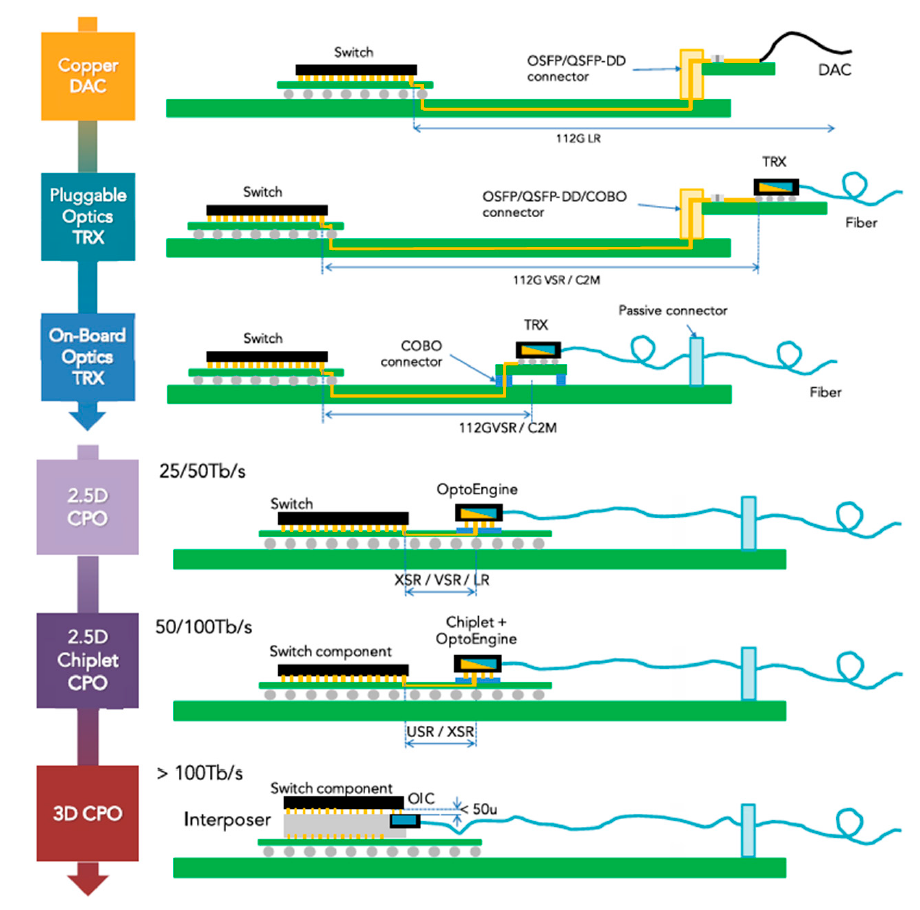
 光电共封装技术的实现方案
光电共封装技术的实现方案

以下文章来源于逍遥设计自动化,作者逍遥科技
CPO技术转型的必然性
数据中心网络架构正在经历向光电共封装(CPO)交换机的根本性转变,这种转变主要由其显著的功耗效率优势所驱动。在OFC 2025展会上,这一趋势变得极为明显,从Jensen Huang在GTC 2025上的演示到众多供应商展示集成在ASIC封装内的光引擎,CPO技术已经成为塑造高带宽网络基础设施未来的主导力量。
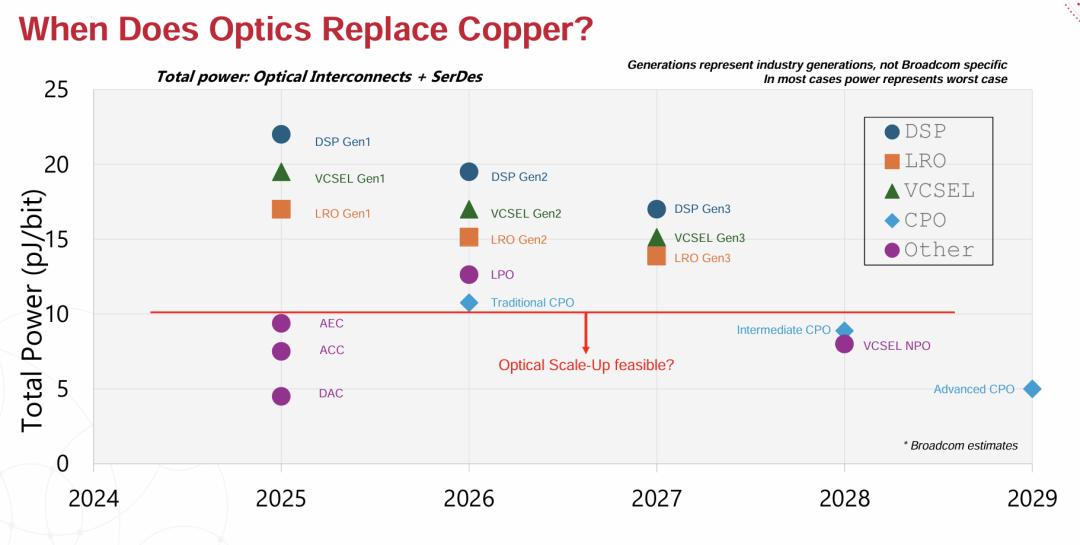
CPO技术的强有力论据在于其解决传统可插拔光模块所面临的日益严重功耗挑战的能力。尽管像Andy Bechtolsheim这样的行业资深人士继续倡导线性可插拔光模块(LPO)作为替代方案,但扩展到更高SerDes速度的技术现实使CPO的采用几乎不可避免。LPO虽然通过消除板载数字信号处理器相比传统可插拔光模块节省30%到50%的功耗,但在数据速率攀升至每通道400千兆位世代时,在ASIC与前面板光模块之间的电气界面上面临着无法克服的插入损耗挑战[1]。
1理解CPO集成方法
在ASIC封装内集成光引擎遵循两种主要的架构策略,每种策略都为不同的部署场景提供独特的优势。这些方法代表了管理电气、热学和光学设计约束之间复杂相互作用的完全不同的理念。
硅Interposer方法将核心die和电子集成线路(EIC)共同放置在硅Interposer上,光电子集成芯片(PIC)要么3D堆叠在EIC之上,要么位于有机基板内。这种配置创造了业内专家称为"光学I/O"的结构,通过高密度die到die连接和复杂的Interposer布线实现核心die与光引擎之间的电气连接缩短。然而,当高功耗EIC与核心die共享空间时,这种方法引入了显著的热管理复杂性,特别是当PIC堆叠在EIC顶部时,散热变得相当困难。
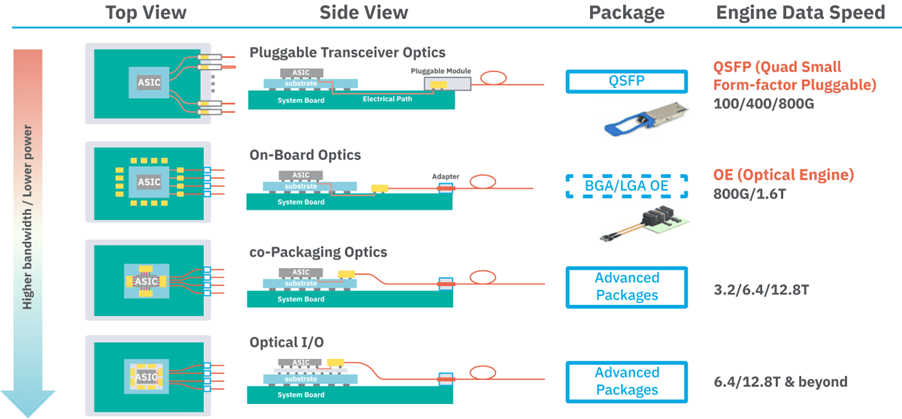
图1:将光引擎集成到半导体封装中的不同方法,显示了硅Interposer和有机基板方法及其各自的优势和热考虑因素。
替代的有机基板方法将光引擎保持在围绕主die的有机基板上,避免了与大型硅Interposer相关的复杂性和成本。在这种配置中,PIC和EIC组件组装在一起,通常EIC堆叠在PIC之上,形成紧凑的光引擎模块,战略性地安装在核心die周围。这种排列允许优越的热隔离,因为光引擎可以分开放置,并可能配备单独的散热器或定位以优化气流和冷板可达性。
2比较行业领导者:Broadcom和Nvidia的实现方案
当前的CPO领域由来自行业领导者Broadcom和Nvidia的两种截然不同的方法主导,每种方法都反映了不同的优先级和目标应用。这些实现为CPO技术部署中固有的实际挑战和权衡提供了宝贵的见解。
Broadcom的Bailly CPO交换机基于Tomohawk-5 ASIC构建,在封装内集成了八个6.4Tbps光引擎,提供51.2Tbps的总封装外光带宽。这个解决方案支持64个800Gbps端口或128个400Gbps端口,代表了在800G以太网时代与当前网络基础设施需求相一致的实用方法。

图2:Broadcom的实现方案,其特点是围绕Tomohawk-5 ASIC集成的八个6.4Tbps光引擎,提供51.2Tbps总带宽,专注于在当前数据中心环境中的实际部署。
Nvidia采用更激进的方法,其Quantum-X InfiniBand和Spectrum-X以太网平台针对显著更高的带宽容量。Quantum-X系统通过四个CPO封装提供115.2Tbps,每个提供28.8Tbps带宽,而Spectrum-X系列从102.4Tbps扩展到令人印象深刻的409.6Tbps配置。这些雄心勃勃的规格反映了Nvidia专注于使用200G SerDes技术支持未来百万GPU集群需求。

图3:Nvidia雄心勃勃的Quantum-X系统架构,展示了为大规模AI集群部署提供115.2Tbps带宽而设计的四封装配置。
在可维护性方法上出现了一个关键的架构差异。Broadcom将光引擎永久绑定在封装内,创造了一个更简单但可维护性较低的解决方案。Nvidia通过创新的可拆卸光学子Assembly(OSA)解决了可维护性问题,其中三个1.6Tbps光子引擎聚集成可更换的4.8Tbps模块。这种模块化设计使得在制造测试期间可以更换有故障的光组件而无需丢弃整个交换机,尽管现场可维护性仍然具有挑战性。
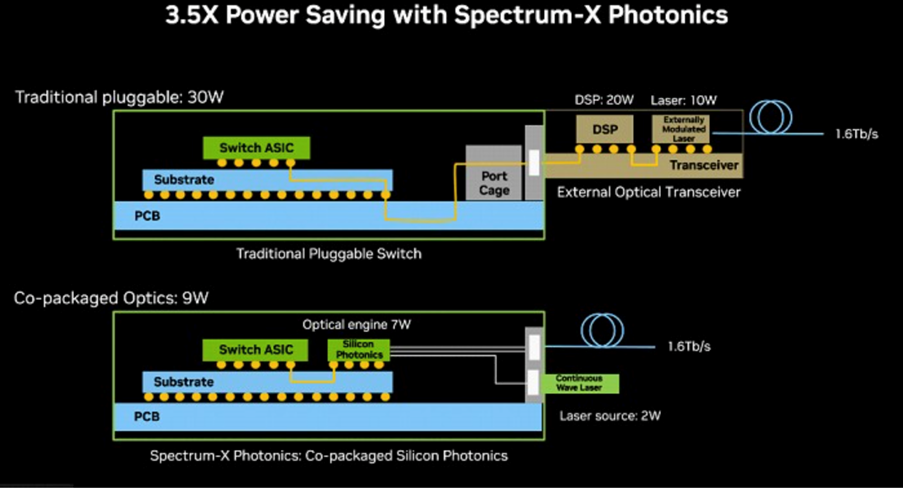
图4:Nvidia对CPO实现的复杂方法,其特点是可拆卸光学子Assembly(OSA)和使用TSMC的COUPE工艺的先进2.5D/3D集成技术,以增强可维护性。

图5:Quantum-X和Spectrum-X CPO封装。提供了对Nvidia chiplet组织的详细见解,主核心交换die与通过die到die接口紧密集成的八个I/O die,被有机基板中的光子引擎所包围。
3技术实现细节
CPO系统背后的技术复杂性在检查其光纤耦合和激光集成策略时变得明显。Broadcom和Nvidia都开发了巧妙的解决方案来管理其高带宽系统所需的大规模光连接。
Broadcom采用边缘耦合光纤连接,通过使用自动化、高精度Assembly工艺将精确对准的光纤阵列永久绑定到波导端面来实现出色的海滨密度。其第一代CPO利用400G-FR4技术,实施粗波长分复用(CWDM)在单根光纤上承载四个100G通道,每个6.4Tbps光引擎需要16对光纤。
Nvidia的方法在激光集成中展现了显著的效率,仅需要18个激光模块就能为其Quantum-X系统中的所有144个光通道提供光源。每个激光模块包含八个集成激光器并支持八个1.6Tbps光子引擎,相比Broadcom的实现方案激光模块需求减少了四倍。这种效率伴随着容错性的权衡,因为单个激光故障会影响更多的光通道。
调制器技术选择反映了功耗和可扩展性方面的不同优先级。Broadcom可能采用马赫-曾德调制器(MZM),提供优越的温度稳定性和激光不稳定性容忍度,但功耗更高,为每比特5-10皮焦耳。Nvidia选择微环谐振器调制器(MRM)实现了每比特1-2皮焦耳的显著更低功耗,具有适合高密度应用的更小占用面积,尽管需要更复杂的调谐和数字信号处理来管理热敏感性和串扰。
4功耗效率和未来展望
CPO技术的功耗效率成就代表了其相对于传统可插拔解决方案最引人注目的优势。Broadcom报告每800Gbps端口约5.5瓦,相比等效可插拔模块的15瓦,转化为6-7皮焦耳每比特的性能,在2024年部署中领先行业。Nvidia声称通过其硅基光电子实现方案实现了更激进的3.5倍功耗效率改进。
这些效率提升使满载的高带宽交换机相比可插拔替代方案节省数百瓦特,尽管热管理仍然具有挑战性。两种实现方案都需要复杂的冷却解决方案,液体冷却对于管理ASIC封装内的集中功率密度变得必要。
展望未来发展,几项新兴技术有望进一步增强CPO能力。垂直耦合技术可以通过在芯片表面而不仅仅是周边实现光输入/输出来克服边缘长度约束。多芯光纤和减小光纤间距技术为显著增加带宽密度提供了途径,研究演示实现了低至18微米的光纤间距。
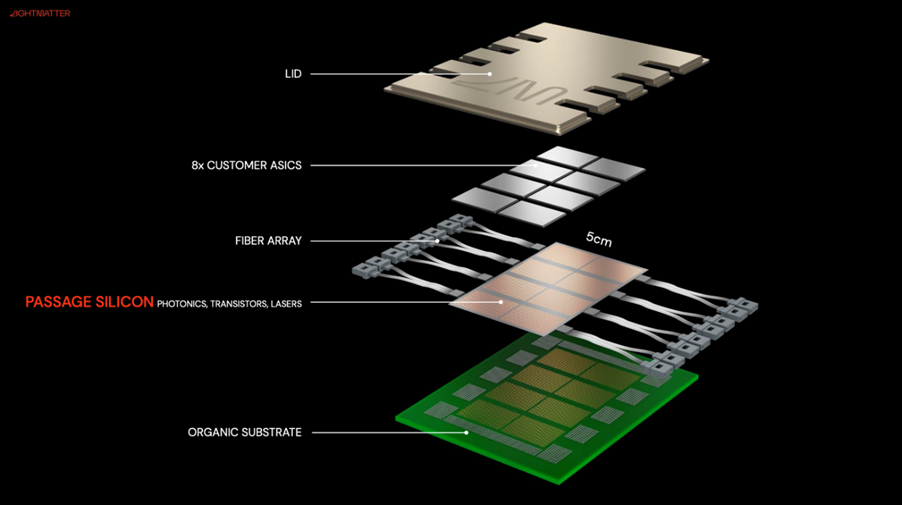
图6:光子Fabric或Interposer示意图,展示了光子Interposer或Fabric的概念,如何将光交换和路由能力集成到计算chiplet下方的基础层中,本质上为未来高带宽应用创建光学主板。
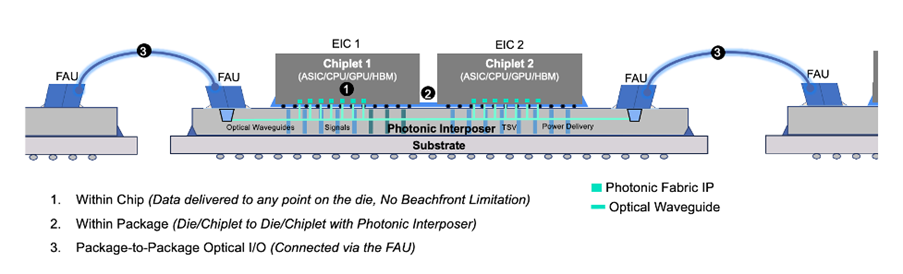
图7:光子Interposer示意图,显示了光子Interposer实现的另一种愿景,说明了光连接如何能够为内存分解和封装内chiplet间超低延迟通信的新架构提供支持。来源:Celestial.ai
CPO技术的未来延伸超越了传统交换应用,进入了令人兴奋的新领域。光子Fabric和Interposer代表了下一个演进步骤,可能实现光学主板,其中激光器、波导和光交换位于支持上方计算和存储chiplet的基础层中。虽然这些3D配置中的热管理挑战仍然存在,但成功的CPO交换机部署将建立技术基础、供应链基础设施和这些先进实现所需的行业信心。
向CPO技术的转变不仅仅是简单的组件升级,而是通过在显著降低功耗的同时实现空前的带宽密度从根本上重塑数据中心架构。随着行业继续推向更高数据速率和更苛刻的AI工作负载,CPO作为连接当前能力与未来需求的基础技术,使其不仅是一个有吸引力的选择,而且是下一代网络基础设施的必然需求。
关于我们:
深圳逍遥科技有限公司(Latitude Design Automation Inc.)是一家专注于半导体芯片设计自动化(EDA)的高科技软件公司。我们自主开发特色工艺芯片设计和仿真软件,提供成熟的设计解决方案如PIC Studio、MEMS Studio和Meta Studio,分别针对光电芯片、微机电系统、超透镜的设计与仿真。我们提供特色工艺的半导体芯片集成电路版图、IP和PDK工程服务,广泛服务于光通讯、光计算、光量子通信和微纳光子器件领域的头部客户。逍遥科技与国内外晶圆代工厂及硅光/MEMS中试线合作,推动特色工艺半导体产业链发展,致力于为客户提供前沿技术与服务。
-
封装技术
+关注
关注
12文章
587浏览量
68736 -
数据中心
+关注
关注
16文章
5305浏览量
73771 -
光模块
+关注
关注
81文章
1494浏览量
60681
原文标题:光电共封装技术解析
文章出处:【微信号:深圳市赛姆烯金科技有限公司,微信公众号:深圳市赛姆烯金科技有限公司】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录

Broadcom光电共封装技术解析
CPO光电共封装如何破解数据中心“功耗-带宽”困局?
用于高速光电组件的光焊球阵列封装技术
Avago推出新封装光电耦合器
微光电子机械系统器件技术与封装
光电共封装
光电共封装

光芯片和电芯片共封装技术的创新应用







 工商网监
工商网监
评论