 AI?时代来袭,手机芯片面临哪些新挑战?
AI?时代来袭,手机芯片面临哪些新挑战?

本文翻译自Semiengineering
边缘AI、生成式AI(GenAI)以及下一代通信技术正为本已面临高性能与低功耗压力的手机带来更多计算负载。
领先的智能手机厂商正努力应对本地化生成式AI、常规手机功能以及与云之间日益增长的数据传输需求所带来的计算与功耗挑战。
除了人脸识别等边缘功能以及各种本地应用,手机还必须持续适配新的通信协议以及系统和应用更新。更重要的是,这一切都要在单次电池充电下完成,同时确保设备在用户手中或贴近面部时保持低温。
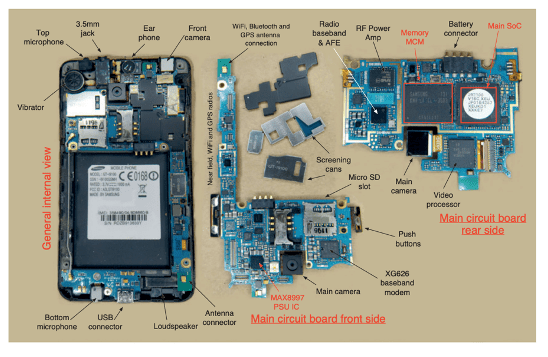
图1:移动电话主板,右上为SoC(系统级芯片),包含Arm CPU及其他组件。
图片来源:Arm
“如果你查看任何一款高端手机的配置,你会发现所有的SoC都采用异构架构,不同的模块处理不同的任务,同时又协同工作。”Imagination Technologies细分市场战略与产品管理高级总监Vitali Liouti表示,“从系统角度来看,所有移动SoC厂商都会以平台的方式同时考虑硬件和软件的协同设计。”
Cadence公司硅解决方案事业部Tensilica DSP产品管理与市场营销总监Amol Borkar表示,AI网络的快速演进和模型需求的多样化使得移动SoC设计变得日益复杂。“与传统工作负载不同,AI模型——尤其是大语言模型(LLMs)和变换器(Transformer)变体——在架构、规模和计算需求上都在不断变化。这对芯片设计者来说是一个移动靶,因为芯片一旦投片就无法更改,但他们仍需预置未来AI能力的支持。更复杂的是,芯片还必须兼顾云端的大型模型与本地推理的小型高效模型(如TinyLlama)。这些小型LLM对于移动和嵌入式设备至关重要,因为它们需要在极低功耗与存储限制下实现智能功能。”
除了从系统角度整体规划外,AI也正在推动单个处理器架构和任务分配的变革。
“当前的变化主要体现在两个方向。”Synaptics物联网与边缘AI处理器部门副总裁兼总经理John Weil表示,“一是Arm和RISC-V生态系统中的CPU架构持续增强,人们正在为Transformer模型添加矢量数学单元以加速各类数学运算;二是神经处理器(NPU)的改进,它们类似GPU,但专用于边缘AI模型加速,基本上也是矢量计算单元,用于加速模型内部的各种算子。如果查看Arm的TOSA(Tensor Operator Set Architecture)规范,里面定义了各种AI操作,开发者也在为其编写类似GPU的OpenGL加速程序。”
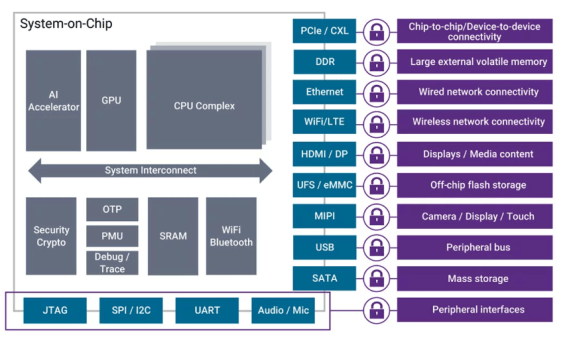
图2:移动SoC设计示意图,AI加速器可以是GPU、NPU或高端ASIC。图片来源:Synopsys
过去几年,GPU和NPU的设计都经历了快速演进以适应新应用场景。Imagination的Liouti指出,在高端手机中,GPU通常占芯片面积的约25%,而NPU的体积也持续扩大以承担更多工作负载。“具体在哪个模块上运行任务取决于模型。例如某些层适合NPU执行,而有些则需要GPU配合。NPU已成为低功耗任务的关键,尤其适用于‘始终在线’(Always-On)的场景。同时,还必须搭配高性能CPU,因为它承担初始加载和任务管理。如果CPU性能不足,再强大的GPU或NPU也难以发挥作用。”
在所有并行处理任务(图形、通用计算或AI)中,功耗效率始终是核心。“我们对标量单元(ALU)进行了全面重构和调优,以实现更高的能效。”Imagination产品管理副总裁Kristof Beets表示,“接下来我们要将更多NPU技术引入GPU,例如更专用的数据类型和处理管线,以在保持可扩展性的同时提供更强性能。当然,我们也不能忽视开发者社区,如何实现开箱即用、如何进行高效优化与调试,这是我们重点关注的方向。”
如今,将AI集成进芯片的难度已大幅降低。“五年前大家还在问AI到底该怎么做,是不是得雇一整个数据科学家团队?现在完全不是这样了。”Infineon IoT、消费及工业MCU部门高级副总裁Steve Tateosian说,“我们拥有一整个DSP博士工程师团队,他们在调试音频前端,开发工程师通过AI工具来建模即可。开发流程也变得极为顺畅:数据采集、标注、建模、测试、优化——工具链已大幅提升,很多专业知识已内嵌其中,让更多工程师都能上手。”
视觉化、无线化与触控挑战
随着AI应用增长,界面也趋于视觉化,对处理能力的要求更高。
“过去是计算机或基于文本的界面,如今一切都变成了视频或全图形界面,而这类界面的计算需求要高得多。”Ansys产品营销总监Marc Swinnen表示,“无论是屏幕输入还是1080p等格式的视频输出,视频的输入输出管理都需要大量计算资源。”
此外,如今手机中的所有功能几乎都是无线的,因此模拟电路的比例大幅上升。“现在的手机大约配有六根天线——这太疯狂了。”Swinnen说,“所有这些高频通信功能,包括Wi-Fi、5G、蓝牙、AirDrop等,都有各自的频段、芯片和天线。”
通信标准不断演进的事实,也为SoC设计者带来了额外挑战。
“当前的关键在于推动AI应用落地,并加速UFS(通用闪存存储)的标准推进。”Synopsys移动、汽车和消费类IP产品管理执行总监、MIPI联盟主席Hezi Saar表示,“MIPI联盟成功将推进时间提前了一年,这大大降低了风险。行业现在正在定义这个规范。SoC和IP厂商需要在规范尚未完全定稿时就开始开发自己的IP。他们需要在规范尚不完整时完成流片、拿到初步的硅片,同时还要为下一版规范做规划,提前考虑互操作性以及生态系统的构建。这在过去是不可想象的。以前标准的更新是有节奏的,比如每两年一个版本。但现在节奏被大大压缩,因为AI更偏向软件领域,而它对硬件的影响巨大。硬件终究不是软件。”
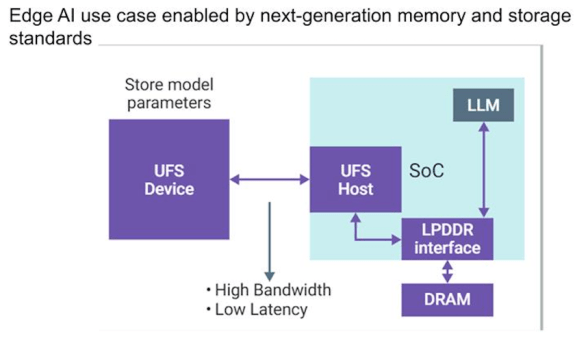
图3:智能手机中的LLM或AI引擎依赖高效存储访问。
图片来源:Synopsys
“当你启动设备时,大部分模型需要加载到DRAM中,这意味着从UFS存储设备到SoC的读取链路必须非常高效。”Saar表示,“这关乎延迟——你不能按下按钮提问,然后等两秒钟。当然,也有其他处理方式,比如你不必读取整个模型,可以进行部分读取。但这些系统的核心任务就是将数据快速传输到DRAM。我已经在芯片上运行了LLM,比如通过某个加速器,但它需要和DRAM高效连接以完成计算,然后再将结果返回给用户,比如音频输出。在移动设备中,这个流程必须非常高效,功耗尤为关键。因此厂商会尽可能减少传输次数,并将UFS存储尽可能多地置于休眠状态。我预计未来存储接口和DRAM接口都会发展得非常非常快——远快于以往。”
多模态模型和像Stable Diffusion这样的生成式AI工具也加大了系统的复杂性。这类模型将文本、图像,甚至音频处理集成到统一架构中。Cadence的Borkar表示:“这些模型需要一种灵活高效的计算架构,能够处理多样的数据类型和执行模式。为了在快速演进的AI环境中保持韧性,AI子系统在设计时必须具备面向未来的可扩展性。这通常意味着在NPU旁边集成可编程IP块,使SoC能在芯片量产后仍能适配新模型和新负载。支持如此广泛的AI应用场景,要求SoC不仅性能强大、能效高,还要具备高度的架构灵活性,这也让AI中心化芯片设计成为移动计算领域最具挑战性的前沿方向之一。”
算法在手机上的另一个典型应用是判断哪些触控是有效的,哪些不是,无论是传统的“糖块机”还是折叠屏手机。后者由于屏幕极薄,挑战更大。
“屏幕变得很薄时,触控层必须贴得非常接近带噪声的显示层。”Synaptics产品营销总监Sam Toba表示,“我们需要处理来自单个像素的大量显示噪声。这在超薄显示器中是个问题。背景层越薄,电容板之间越接近,整体电容就越高。而触控本身依赖检测非常微小的电容变化,在背景电容极高的情况下,识别出有效手指信号就变得更加困难。”
这种超低功耗芯片必须在本地判断哪些信号是有效的,只有在确认是有效触控后才唤醒主SoC。“如果由主控芯片来识别触控信号,它就必须持续运行,这将导致巨大的功耗。因此,大部分无效触控必须在本地就被过滤掉。”
本地AI处理与模型部署
手机中集成了众多AI应用,且数量还在持续增加。Ansys的Swinnen指出,在可能的情况下,AI推理应尽量在本地完成,仅将精简过的信息上传至云端。例如,人脸识别或图像处理等机器学习功能应靠近摄像头完成处理。
即便是像ChatGPT或具备智能代理功能的GenAI模型,其推理过程也可本地完成。Synopsys的Saar表示,AI模型现在更高效也更紧凑,大小从几兆到几十兆不等,完全可以部署在设备本地,视具体模型与设备而定。
在本地处理AI带来诸多优势。Siemens Digital Industries Software的网络解决方案专家Ron Squiers指出:“将AI硬件集成到移动设备中,可以直接在本地运行大语言模型的推理,不再需要将数据发回云端处理。这带来的好处是双重的:延迟更低,响应更及时,闭环控制性能更好;同时还可提升数据隐私,因为数据不会离开设备。”
Infineon的Tateosian也表示赞同:“数据不再上传云端,这降低了功耗和成本。有些边缘AI应用甚至可以在不引入连接成本的前提下提升智能水平,或者减少对连接的依赖——这意味着减少云端通信和终端设备的整体功耗。”
Imagination的Liouti指出,如今是一个“极致优化(hyper-optimization)”的时代,设计者必须消除一切“技术债务”,从而榨取设备更多性能:“数据搬移消耗了约78%的功耗。我们工作的重点是如何减少这些数据移动。这可以通过GPU实现,也是我们主要发力的地方,但也可以在平台级或SoC层面优化。我们需要开发非常先进的技术来解决这个问题。而对于神经网络尤其是大型模型而言,数据搬运的挑战会更大。”
尽管本地AI推理正在快速发展,但由于电池和功耗的限制,仍有部分任务需要依赖云端。“你总要有所取舍。”Liouti说,“这只是一个旅程的开始,几年后情况会截然不同。我们现在还只是刚刚起步。我认为transformer是未来更大系统的基础模块。目前,我们需要将炒作和现实区分开。以本地运行图像生成模型为例,虽然现在手机上也能跑,但性能远不如你在PC上用Midjourney生成的图像。不过几年后,情况就会变了。”
更强大的GPU也将成为解决方案的一部分。“在移动平台上,我们可以把省下来的功耗转化为更高的主频和更强的性能,同时依然保持在同一个功耗与热预算范围内。”Imagination的Kristof表示。
不过Infineon的Tateosian也指出,尽管设备每一代的性能和内存都在增长,但用户实际体验变化不大。“因为软件的增长完全吞噬了这些性能提升。”
结语
移动SoC设计正受到多项关键趋势的驱动。
“模拟部分的增长、一切内容视频化与AI化,再加上当今应用对高性能计算(HPC)的需求,使得芯片必须具备极强的算力。”Ansys的Swinnen表示,“这些因素正在推动SoC的演进,但手机制造商面临的限制在于,他们必须保持低功耗和小尺寸设计,同时相比于像NVIDIA这样的GPU公司,他们在成本上受到更严格的限制。NVIDIA可以优先考虑性能,即使成本略高也无妨。但手机芯片不一样,它必须能以极低成本大规模量产。”
芯片设计者必须从软硬件协同的角度出发来设计SoC。“任何忽视这点的人,最终都会失败。”Imagination的Liouti强调,“我们必须将语言模型的层级、操作类型等问题纳入考虑。听起来简单,但实际上并不容易。你必须找到一种方式,最大化利用硬件来完成数学运算,从而确保你的解决方案在竞争中脱颖而出,因为我们面对的是行业巨头。必须进行软硬件协同设计,而这绝非一个工程师就能独立完成的任务,而是需要多个学科背景的专家共同合作,其中有些领域甚至看起来毫不相关。”
原文链接:https://semiengineering.com/mobile-chip-challenges-in-the-ai-era/
-
手机芯片
+关注
关注
9文章
375浏览量
50033 -
AI
+关注
关注
88文章
35476浏览量
281280
发布评论请先 登录
传AMD再次进军手机芯片领域,能否打破PC厂商折戟移动市场的“诅咒”

【书籍评测活动NO.64】AI芯片,从过去走向未来:《AI芯片:科技探索与AGI愿景》

手机芯片:从SoC到Multi Die

今日看点丨传英特尔或被拆分,台积电、博通考虑接手;英伟达联手联发科开发AI PC和手机芯片
国内汽车芯片面临的挑战及发展建议
天玑 9400拿下AI性能榜冠军,最强NPU引领手机AI应用变革
浪潮信息剖析智能时代数据存储领域面临的挑战与机遇
AMD MI300X AI芯片面临挑战
什么造就了优秀的手机芯片?





 工商网监
工商网监
评论