 奇异摩尔携手UALink联盟助力AI网络繁荣发展
奇异摩尔携手UALink联盟助力AI网络繁荣发展

随着AI大模型训推集群的规模不断扩大,Scale-up网络的重要性已不限于训练集群侧,云端推理集群对于多机之间组成超节点HBD方案的需求正在逐步增加。面对其对互联性能的极致追求,目前业内主要采用专门设计的协议比如NVIDIA的NVLink及NVSwitch技术。在今年的GTC大会上,NVIDIA已经明确将GPU 的HBD域互联从72卡推进到576卡。 然而,NVIDIA的解决方案是基于私有协议,不仅成本高昂,且不对外开放。为了打破这一局面,AI网络产业链在去年共同发起了UALink 加速器互联协议联盟,旨在推动AI网络Scale-up互联的创新技术发展。
奇异摩尔在2024年就加入了UALink(Ultra Accelerator Link ) 加速器间互联协议联盟,并积极参与UALink标准的制定。 就在本周,UALink联盟终于迎来了1.0标准的正式发布,这一标准的发布将进一步加速AI训推基础设施的生态完善,助力AI网络的繁荣发展。
关于第一版标准,UALink 联盟董事会主席 Kurtis Bowman 表示:“随着对 AI 计算的需求不断增长,我们很高兴能够提供一项必不可少的开放行业标准技术,使下一代 AI/ML 应用能够推向市场。UALink 是唯一一款针对扩展 AI 的内存语义解决方案,它针对降低功耗、延迟和成本进行了优化,同时增加了有效带宽。UALink 200G 1.0 规范带来的突破性性能将彻底改变云服务提供商、系统 OEM 和 IP/芯片提供商处理 AI 工作负载的方式。
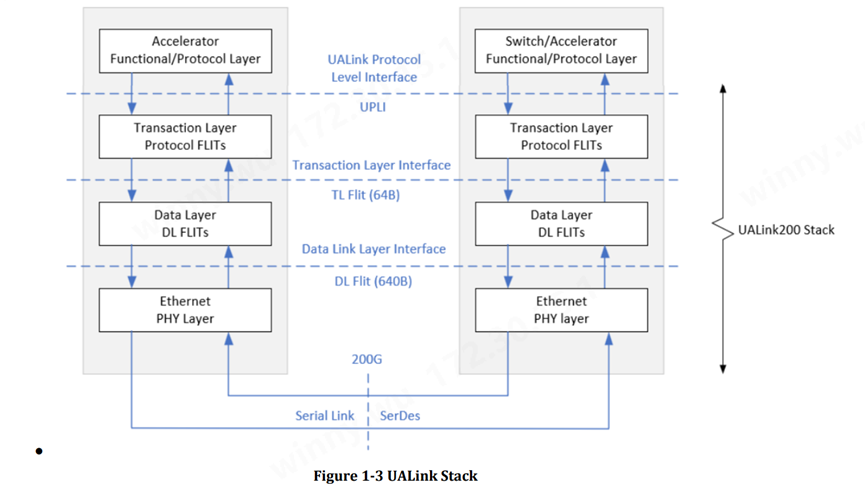
UALink 协议栈包括四个硬件优化层:物理层(physical)、数据链路层(data link)、事务层(transaction)和协议层(protocol)。
基于内存语义的快速GPU HBM访问
(图:UALink Specification 1.0Rev)
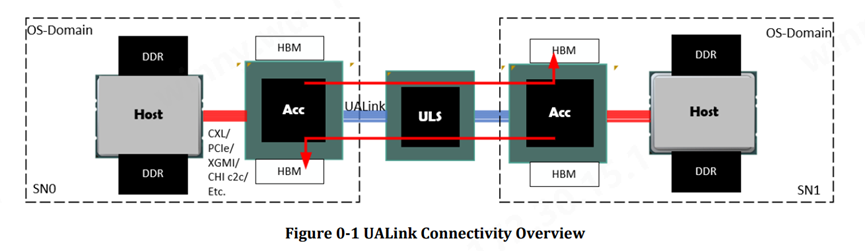
和其他Scale-up生态有所区别的是UALink从诞生那刻起就是基于内存语义。上述表格描述了两个基于UALink的系统节点通过UAL交换机实现互联。在这个Domain中,CPU Host可通过CXL, PCIe, AMD Infinity Fabric, XGMI等协议与GPU加速器互联。基于UALink协议,GPU之间通过UAlink Switch交换机与HBD域内的其他GPU互联。
图中特别突出的是红线所指示的部分,在该HBD Domain中的任意GPU 都可以访问其他GPU的HBM,从而实现加速器之间的快速读取和写入,相较于消息语义,它的通信和互联效率是非常高的。
奇异摩尔作为Scale-up网络主要芯粒提供商自研的 NDSA-G2G IO Die 未来将支持内存语义,通过与UAlink生态适配,建立更完善的内存语义互联系统。
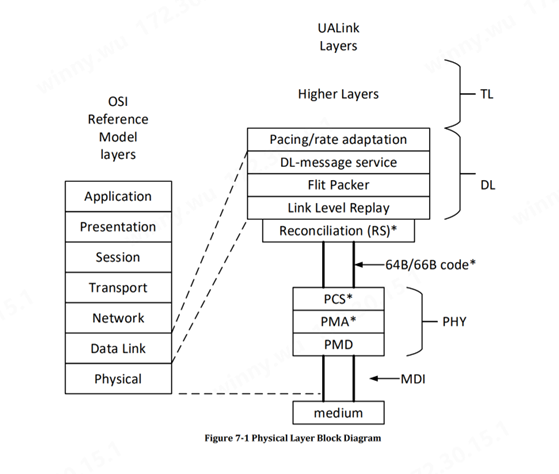
物理层特点Physical Layer
(图:UALink Specification 1.0Rev)
UALink 物理层基于 802.3 以太网物理层。UALink 定义了 1、2 或 4 个串行通道,运行速率为 212.5Gbps(200GBASE-KR1/CR1、400GBASE-KR2/CR2、800GBASE-KR4/CR4)。物理层包括了使用 FEC 减少延迟的修改。该以太网物理层具有标准的前向 (FEC) 并遵循 IEEE P802.3dj 规范。通过单向和双向码字交错,让延迟得到改善,并且有一点变化以支持 680 字节的 flit。(Flit 或流控制单元是链路级别的原子数据单元)
在 PCI-Express 6.0 中,控制该标准(并且主要由英特尔主导)的 PCI-SIG 组织,并没有仅仅实现标准的 FEC,而新的FEC是转向了一种流量控制和循环冗余检查 (CRC) 错误检测的混合方式,实际上提高了信号传输的可靠性,同时降低了延迟。这样的一些机制被 UALink 采纳,并且许多对于内存架构来说不必要的东西并没有包含在其中从而轻量化了该协议。
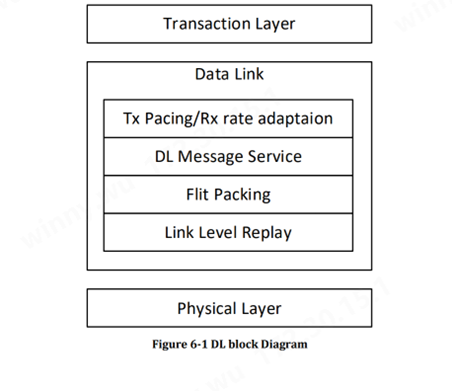
数据链路层特点Data Link Layer
(图:UALink Specification 1.0Rev)
数据链路层位于事务层和物理层之间。数据链路层将事务层的 64 字节 Flit 打包成物理层的 640 字节 Flit。数据链路层还提供链接伙伴之间在数据链路层发起和终止的消息服务。消息服务用于宣传事务层速率、查询连接链路伙伴上的设备和端口 ID 以及其他功能。消息服务还提供链接伙伴之间的 UART 式通信,用于固件通信。链路级重放是基于 640 字节 Flit 提供的。计算并检查 32 位 CRC,并且是 640 字节 Flit 的一部分。此外Link Level Replay的功能确保了物理层 FEC 无法纠正的比特错误存在的情况下,DL Flits 的有序传递。发送器保留有效负载 Flits的副本,直到接收器确认它们。
事务层特点Transaction Layer
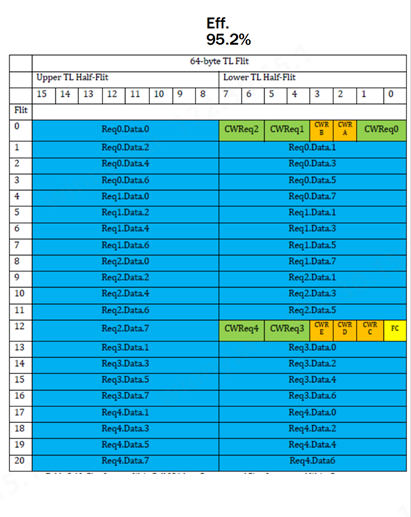
(图:UALink Specification 1.0Rev)
UALink 1.0 Spec实现压缩寻址,在实际工作负载下以高达 95% 的协议效率简化数据传输。它支持直接内存操作,例如加速器之间的读取、写入和原子事务(atomic transactions),从而保留本地和远程内存空间之间的顺序。
协议层特点Protocol Layer
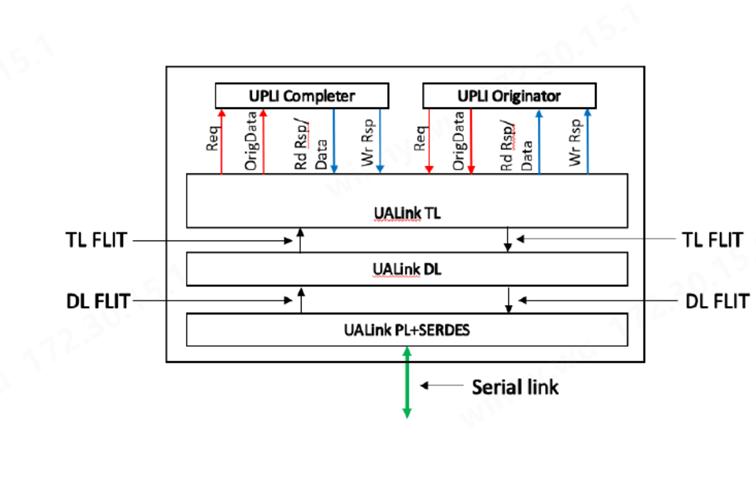
(图:UALink Specification 1.0Rev)
UALink 的协议层称为 UALink 协议级接口 (UPLI)。UPLI 定义了一个逻辑信号接口和协议,通过该协议,设备可以通过一组请求和响应消息交换数据和控制信息。UALink 规范完全定义了 UPLI 协议,并期望遵循该协议的实现将与 UALink 交换机兼容。UPLI 协议具有内置的灵活性,允许供应商创建自定义协议消息,用于相同类型的加速器之间的通信,而无需对 UALink 交换机进行任何修改。UALink 协议级接口是主要接口,实现可能在此基础上开发,通常使用第三方供应商提供的堆栈其余部分的 IP。
协议轻量化降低数据中心功耗
UALink的一个非常突出的特点就是整体设计简单轻量化。据悉,UALink 的功耗仅为同等以太网 ASIC 芯片面积的一半到三分之一(每个端口),并且每个内存结构加速器可节省 150 瓦到 200 瓦的功耗。更小的芯片尺寸意味着更便宜的芯片,更低的功耗意味着更少的电力和冷却消耗,从而降低整体 TCO。
UALink如何在中国市场落地
UALink国际互联系统开发标准在中国的应用落地,需要产业链上下游的协同配合。因此,联盟成员囊括了国内芯片制造商、以奇异摩尔为代表的芯粒厂商,以及交换机提供商等关键角色。在今年的ODCC春季全体会议上,ODCC新测组组长郭亮与UALink董事会成员孔阳博士签署了MOU合作备忘录,这标志着国内AI网络Scale-up技术创新与应用将步入快车道。
奇异摩尔作为ALS系统及UALink联盟的生态成员,正与阿里云等头部云厂商、GPU厂商通力合作,通过制定生态标准、提供GPU IO Die(NDSA-G2G)等解决方案,加速国产大模型训练推理技术的发展。
关于我们
AI网络全栈式互联架构产品及解决方案提供商
奇异摩尔,成立于2021年初,是一家行业领先的AI网络全栈式互联产品及解决方案提供商。公司依托于先进的高性能RDMA 和Chiplet技术,创新性地构建了统一互联架构——Kiwi Fabric,专为超大规模AI计算平台量身打造,以满足其对高性能互联的严苛需求。
我们的产品线丰富而全面,涵盖了面向不同层次互联需求的关键产品,如面向北向Scale out网络的AI原生智能网卡、面向南向Scale up网络的GPU片间互联芯粒、以及面向芯片内算力扩展的2.5D/3D IO Die和UCIe Die2Die IP等。这些产品共同构成了全链路互联解决方案,为AI计算提供了坚实的支撑。
奇异摩尔的核心团队汇聚了来自全球半导体行业巨头如NXP、Intel、Broadcom等公司的精英,他们凭借丰富的AI互联产品研发和管理经验,致力于推动技术创新和业务发展。团队拥有超过50个高性能网络及Chiplet量产项目的经验,为公司的产品和服务提供了强有力的技术保障。我们的使命是支持一个更具创造力的芯世界,愿景是让计算变得简单。奇异摩尔以创新为驱动力,技术探索新场景,生态构建新的半导体格局,为高性能AI计算奠定稳固的基石。
-
加速器
+关注
关注
2文章
830浏览量
39323 -
AI
+关注
关注
88文章
35916浏览量
283140 -
奇异摩尔
+关注
关注
0文章
65浏览量
3808
原文标题:生态共建 | UALink 加速器互联协议联盟1.0版本正式发布
文章出处:【微信号:奇异摩尔,微信公众号:奇异摩尔】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Imagination加入龙蜥智算基础设施联盟,携手共建AI开源新生态

奇异摩尔出席第三届芯粒开发者大会AI芯片与系统分论坛
奇异摩尔以互联之长推进OISA GPU卡间互联生态适配

奇异摩尔受邀出席第三届HiPi Chiplet论坛
衢州市领导莅临奇异摩尔考察调研
苹果加入UALink联盟,共推AI加速器新标准
奇异摩尔分享计算芯片Scale Up片间互联新途径






 工商网监
工商网监
评论