 K1 AI CPU基于llama.cpp与Ollama的大模型部署实践
K1 AI CPU基于llama.cpp与Ollama的大模型部署实践

为了应对大模型(LLM)、AIGC等智能化浪潮的挑战,进迭时空通过AI指令扩展,在RISC-V CPU中注入了原生AI算力。这种具有原生AI能力的CPU,我们称之为AI CPU。K1作为进迭时空第一颗AI CPU芯片,已于今年4月份发布。
下面我们以K1为例,结合llama.cpp来展示AI CPU在大模型领域的优势。
llama.cpp是一个开源的高性能CPU/GPU大语言模型推理框架,适用于消费级设备及边缘设备。开发者可以通过工具将各类开源大语言模型转换并量化成gguf格式的文件,然后通过llama.cpp实现本地推理。
得益于RISC-V社区的贡献,已有llama.cpp在K1上高效运行的案例,但大语言模型的CPU资源使用过高,使其很难负载其他的上层应用。为此进迭时空在llama.cpp社区版本的基础上,基于IME矩阵加速拓展指令,对大模型相关算子进行了优化,在仅使用4核CPU的情况下,达到目前社区最好版本8核性能的2-3倍,充分释放了CPU Loading,给开发者更多空间实现AI应用。
Ollama是一个开源的大型语言模型服务工具,它帮助用户快速在本地运行大模型。通过简单的安装指令,用户可以执行一条命令就在本地运行开源大型语言模型,如Llama、Qwen、Gemma等。
部署实践
工具与模型准备
#在K1上拉取ollama与llama.cpp预编译包apt updateapt install spacemit-ollama-toolkit
#k开启ollama服务ollama serve
#下载模型wget -P /home/llm/ https://archive.spacemit.com/spacemit-ai/ModelZoo/gguf/qwen2.5-0.5b-q4_0_16_8.gguf
#导入模型,例为qwen2.5-0.5b#modelfile地址:https://archive.spacemit.com/spacemit-ai/ollama/modelfile/qwen2.5-0.5b.modelfileollama create qwen2 -f qwen2.5-0.5b.modelfile
#运行模型ollama run qwen2
Ollama效果展示
性能与资源展示
我们选取了端侧具有代表性的0.5B-4B尺寸的大语言模型,展示K1的AI扩展指令的加速效果。
参考性能分别为llama.cpp的master分支(下称官方版本),以及RISC-V社区的优化版本(下称RISC-V社区版本,GitHub地址为:
https://github.com/xctan/llama.cpp/tree/rvv_q4_0_8x8)
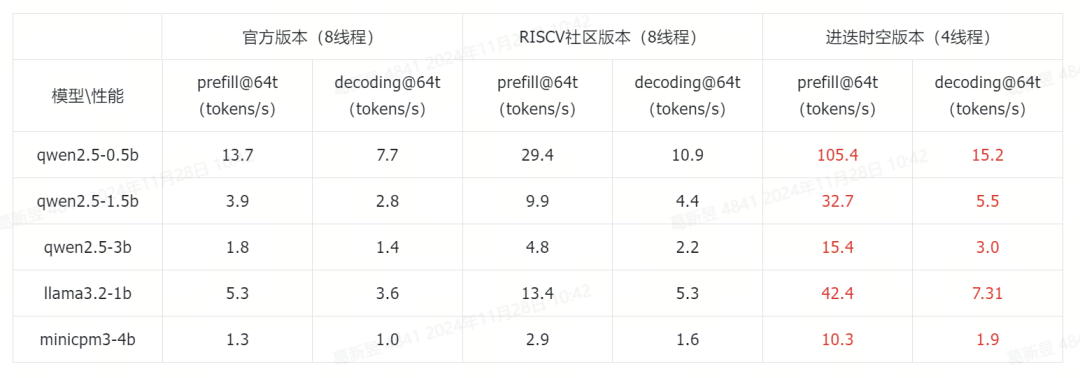
所有模型均采用4bit量化。其中RISC-V社区版本以及官方版本模型为最优实现的加速效果,模型量化时将token-embedding-type设置为q8_0。
llama.cpp的进迭时空版本CPU占用情况:


llama.cpp的RISC-V社区版本CPU占用情况:


参考文档
https://github.com/ggerganov/llama.cpp
https://github.com/ollama/ollama
https://github.com/QwenLM/Qwen2.5
Qwen2 Technical Report
https://ollama.com
结语
进迭时空在K1平台上大模型部署方面取得了初步进展,其卓越的性能与高度的开放性令人瞩目。这为开发者们提供了一个极为友好的环境,使他们能够轻松依托社区资源,进一步拓展和创新,开发出更多丰富的应用。
我们满怀期待地憧憬着K1平台上未来可能出现的更多大语言模型应用的创新设想。在此过程中,我们将持续保持关注并不断推进相关工作。此外,本文所提及的预发布软件包,将在年底以源代码的形式开源,以供广大开发者共同学习与探索。
-
芯片
+关注
关注
460文章
52616浏览量
442623 -
cpu
+关注
关注
68文章
11097浏览量
217577 -
大模型
+关注
关注
2文章
3191浏览量
4146
发布评论请先 登录
利用Arm i8mm指令优化llama.cpp

【VisionFive 2单板计算机试用体验】3、开源大语言模型部署
Arm Neoverse N2平台实现DeepSeek-R1满血版部署

【幸狐Omni3576边缘计算套件试用体验】CPU部署DeekSeek-R1模型(1B和7B)
如何在Ollama中使用OpenVINO后端
将Deepseek移植到i.MX 8MP|93 EVK的步骤
在MAC mini4上安装Ollama、Chatbox及模型交互指南
K230D部署模型失败的原因?
添越智创基于 RK3588 开发板部署测试 DeepSeek 模型全攻略
进迭时空 K1 系列 8 核 64 位 RISC - V AI CPU 芯片介绍
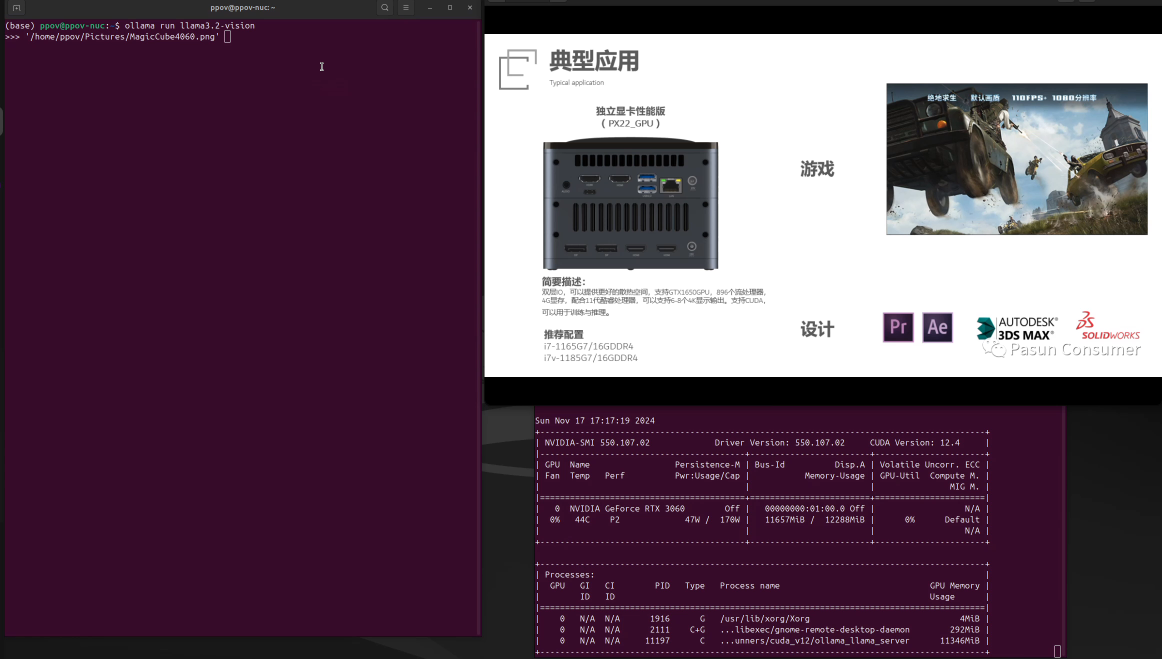
用Ollama轻松搞定Llama 3.2 Vision模型本地部署

Llama 3 与开源AI模型的关系
使用OpenVINO 2024.4在算力魔方上部署Llama-3.2-1B-Instruct模型





 工商网监
工商网监
评论