 利用Arm i8mm指令优化llama.cpp
利用Arm i8mm指令优化llama.cpp

本文将为你介绍如何利用 Arm i8mm 指令,具体来说,是通过带符号 8 位整数矩阵乘加指令 smmla,来优化 llama.cpp 中 Q6_K 和 Q4_K 量化模型推理。
llama.cpp 量化
llama.cpp 是一个开源的 C++ 库,用于运行大语言模型 (LLM),针对加速 CPU 推理进行了优化。通过量化等技术(例如 8 位或 4 位整数格式)来减少内存占用并加快计算速度,从而实现在消费级和服务器级硬件上高效部署模型。
llama.cpp 支持多种量化方式。量化可在模型精度和性能之间取得平衡。数据量越小,推理速度越快,但可能会因困惑度升高而致使精度降低。例如,Q8_0 采用 8 位整数表示一个数据点,而 Q6_K 则将数据量缩减至 6 位。
量化以块为单位进行,同一个块中的数据点共享一个缩放因子。例如,Q8_0 的处理以 32 个数据点为一个块,具体过程如下:
从原始数据中提取 32 个浮点值,记为 f[0:32]
计算绝对值的最大值,即 mf = max(abs(f[0:32]))
计算缩放因子:scale_factor = mf / (max(int8)) = mf / 127
量化:q[i] = round(f[i] / scale_factor)
反量化:v[i] = q[i] * scale_factor
Q6_K 则更为复杂。如下图所示,数据点分为两个层级:
一个超级块包含 256 个数据点,并对应一个浮点格式的超级块缩放因子
每个超级块由 16 个子块组成。每个子块包含 16 个数据点,这些数据点共享一个整数格式的子块级缩放因子。

图 1:Llama.cpp Q6_K 量化
利用 Arm i8mm 指令
优化 llama.cpp
与大多数人工智能 (AI) 工作负载相同,在 LLM 推理过程中,大部分 CPU 周期都耗费在矩阵乘法运算上。Arm i8mm(具体是指 smmla 指令)能够有效加速 8 位整数矩阵乘法运算。
为了说明 smmla 指令的作用及其高效性,假设我们要对下图中的两个矩阵进行乘法运算。
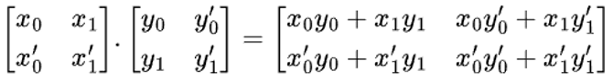
图 2:矩阵乘法
按照教科书上的方法,我们可以逐一计算输出矩阵中的四个标量,即第一个输出标量是矩阵 x 的第一行与矩阵 y 的第一列的内积。依此类推,需要进行四次内积运算。
还有一种更高效的方法,即外积法。如下图所示,我们可以用矩阵 x 的第一列乘以矩阵 y 的第一行,一次性得出四个部分输出标量。将这两个部分输出相加就能得到结果,这样只需要两次外积运算即可。
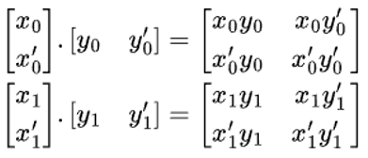
图 3:外积
smmla 指令实现了向量级别的外积运算,如下图所示。请注意,vmmlaq_s32 是实现 smmla 指令的编译器内建函数。
每个输入向量 (int8x16) 被拆分为两个 int8x8 向量
计算四对 int8x8 向量的内积
将结果存储到输出向量 (int32x4) 的四个通道中
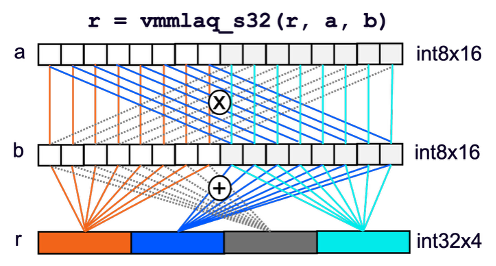
图 4:smmla 指令
借助 smmla 指令,我们可以通过同时处理两行和两列来加速矩阵乘法。如下图所示,计算步骤如下:
从矩阵 x 中加载两行数据 (int8x16) 到 vx0 和 vx1,从矩阵 y 中加载两列数据到 vy0 和 vy1
对 vx0 和 vx1 进行“压缩”操作,将这两个向量的下半部分合并为一个向量,上半部分合并为另一个向量。这是确保 smmla 指令正确工作的必要步骤。对 vy0 和 vy1 执行相同操作
使用两条 smmla 指令计算四个临时标量结果
处理下一个数据块并累积临时结果,直到处理完所有数据
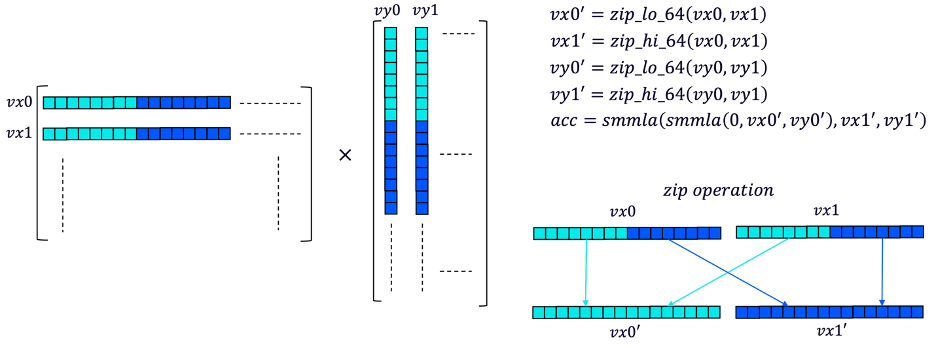
图 5:使用 smmla 指令进行矩阵乘法
我们利用 smmla 指令对 llama.cpp 的 Q6_K 和 Q4_K 矩阵乘法内核进行了优化,并在 Arm Neoverse N2 平台上进行了测试,观察到性能有显著提升。下图展示了 Q6_K 优化前后 llama.cpp 的性能对比,其中:
S_TG 代表词元生成速度,数值越高代表性能越好
S_PP 代表提示词预填充速度,数值越高代表性能越好
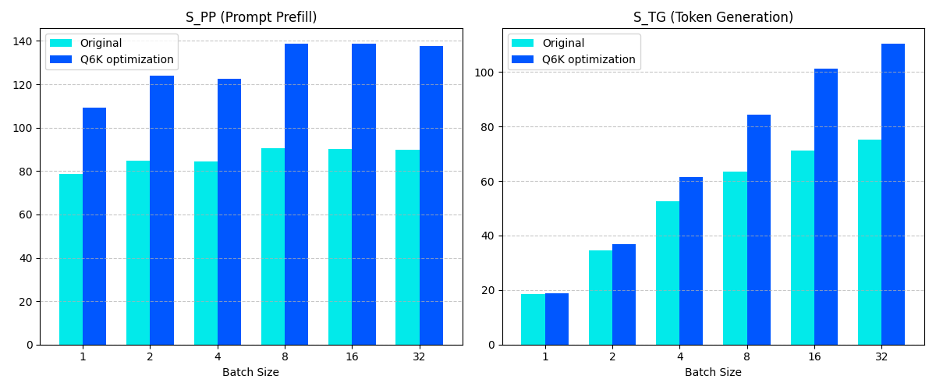
图 6:Arm i8mm 提升 llama.cpp Q6_K 模型性能
上游补丁
[1]利用 Arm i8mm 优化 llama.cpp Q6_K 内核:
https://github.com/ggml-org/llama.cpp/pull/13519
[2]利用 Arm i8mm 优化 llama.cpp Q4_K 内核:
https://github.com/ggml-org/llama.cpp/pull/13886
-
ARM
+关注
关注
134文章
9361浏览量
378077 -
指令
+关注
关注
1文章
617浏览量
36579 -
开源
+关注
关注
3文章
3716浏览量
43902 -
模型
+关注
关注
1文章
3527浏览量
50498
原文标题:一文详解如何利用 Arm i8mm 指令优化 llama.cpp
文章出处:【微信号:Arm社区,微信公众号:Arm社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【飞腾派4G版免费试用】仙女姐姐的嵌入式实验室之五~LLaMA.cpp及3B“小模型”OpenBuddy-StableLM-3B
[技术] 【飞凌嵌入式OK3576-C开发板体验】llama2.c部署
将Deepseek移植到i.MX 8MP|93 EVK的步骤
使用 NPU 插件对量化的 Llama 3.1 8b 模型进行推理时出现“从 __Int64 转换为无符号 int 的错误”,怎么解决?
《电子发烧友电子设计周报》聚焦硬科技领域核心价值 第21期:2025.07.21--2025.07.25
ARM程序设计优化策略与技术
介绍一些ARM NEON编程中常见的优化技巧

如何优化 Llama 3 的输入提示
K1 AI CPU基于llama.cpp与Ollama的大模型部署实践

Arm Neoverse N2平台实现DeepSeek-R1满血版部署






 工商网监
工商网监
评论