 如何以模型和场景为中心的方式控制数据生成
如何以模型和场景为中心的方式控制数据生成

训练计算机视觉模型通常需要在各种场景配置和属性下收集和标注大量图像。这个过程非常耗时,确保捕获的数据分布很好地映射到应用程序场景的目标域也是一个挑战。
最近,合成数据已成为解决这两个问题的一种方法。然而,现有的方法要么需要人类专家手动调整每个场景属性,要么用几乎没有控制的自动方法;这需要渲染大量随机的数据变异,其过程很慢,并且对于目标域来说通常是次优的。
作者提出了第一个完全可微分的合成数据流水线,在闭环中用神经辐射场(NERF),其具备目标应用的损失函数。这个方法按需生成数据,无需人力,最大限度地提高目标任务的准确性。
该方法在合成和真实目标检测任务中具备有效性。一个新的“YCB-in-the-Wild”数据集和基准,为现实环境中具有不同姿态的目标检测提供了测试场景。
最近,图像生成技术神经辐射场(NeRF),作为用基于神经网络的渲染器,替代传统光栅化和光线跟踪图形学流水线的方法。这种方法可以生成高质量的场景新视图,无需进行明确的3D理解。NeRF的最新进展允许控制其他渲染参数,如照明、材质、反照率、外观等。因此,被广泛应用于各种图形和视觉任务。
NeRF及其变型具有一些诱人的特性:(i)可差分渲染,(ii)与GANs和VAEs不同的对场景属性的控制,以及(iii)与传统渲染器相比,数据驱动的模式,而传统渲染器需要精心制作3D模型和场景。这些属性适合于为给定目标任务按需生成最佳数据。
NeRF更适合学习生成合成数据集的优势在于两个方面。 首先,NeRF学习仅基于图像数据和摄像头姿态信息从新视图生成数据。
相反,传统的图形学流水线需要目标的3D模型作为输入。获得具有正确几何、材质和纹理属性的精确3D模型通常需要人类专家(即艺术家或建模师)。这反过来限制了传统图形学流水线在许多新目标或场景的大规模渲染中的可扩展性。
其次,NeRF是一种可微分的渲染器,因此允许通过渲染流水线进行反向传播,学习如何以模型和场景为中心的方式控制数据生成。 工作目标是自动合成最佳训练数据,最大限度地提高目标任务的准确性,取名为Neural-Sim。
在这项工作中,将目标检测作为目标任务。此外,最近,NeRF及其变型(NeRFs)已用于合成复杂场景的高分辨率真实感图像。这里提出了一种优化NERF渲染参数的技术,生成用于训练目标检测模型的最佳图像集。
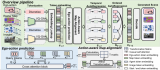
如图所示:(a) 按需合成数据生成:给定目标任务和测试数据集,Neural- Sim使用完全可微分的合成数据生成流水线按需生成数据,最大限度地提高目标任务的精度。(b) 训练/测试域间隙导致检测精度显著下降(黄色条至灰色条)。动态优化渲染参数(姿势/缩放/照明),生成填充该间隙的最佳数据(蓝色条)。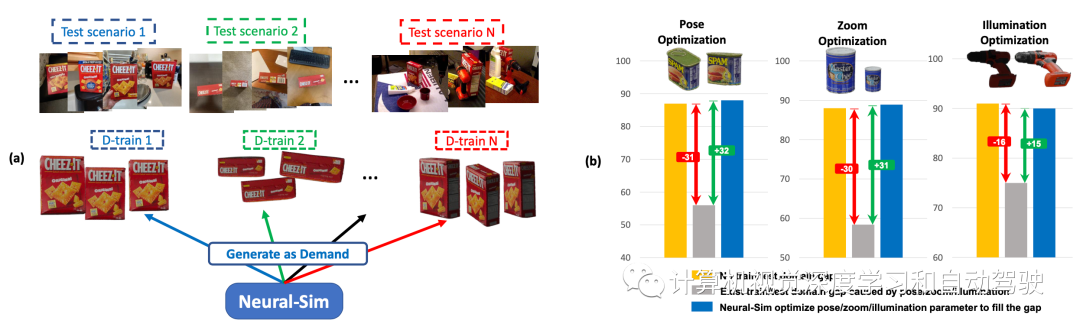
NeRF模型
NeRF表示为V =(φ,ρ),把观察方向(或摄像头姿态)作为输入,并渲染沿V观看的场景图像x=NeRF(V)。注意,这里技术通常广泛适用于不同的渲染器。这项工作中还优化了NeRF-in-the-wild(NeRF-w),允许外观和照明变化以及姿势变化。
合成训练数据生成
考虑渲染参数V的参数概率分布pψ,其中ψ表示分布的参数。应注意,ψ对应于所有渲染参数,包括姿势/缩放/照明,这里,为了简单起见,ψ表示姿势变量。为了生成合成训练数据,首先采样渲染参数V1、V2、…、VN~ pψ。然后,用NeRF生成具有各自渲染参数Vi的合成训练图像xi=NeRF(Vi)。 使用现成的前景提取器获得标签y1,y2,…,yN。由此生成的训练数据集表示为Dtrain = {(x1,y1)、(x2,y2),…,(xN,yN)}。
优化合成数据生成
目标是优化渲染分布pψ,在Dtrain上训练目标检测模型使得在Dval上获得良好的性能。如此构建一个两层优化,即: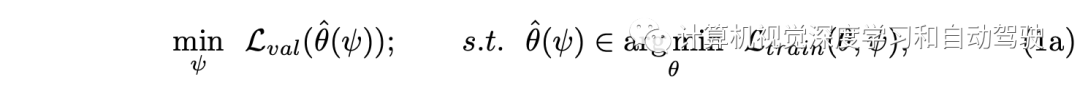
其中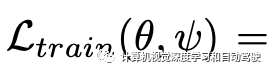
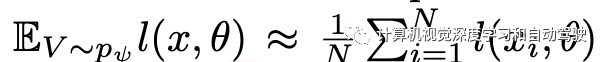
这里求解方法采用如下的梯度计算:其分成两个项分别估计,?NeRF对应于通过从NeRF生成数据集的反向传播,以及?TV对应于通过训练和验证的近似反向传播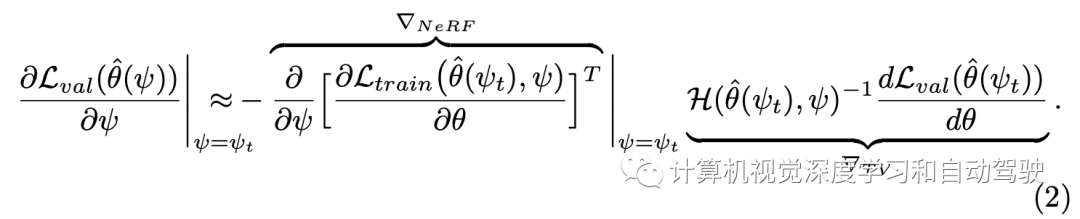
如图所示Neural-Sim的流水线:从经过训练的神经渲染器(NeRF)中找到生成视图的最佳参数,用作目标检测的训练数据。目标是找到能够生成合成训练数据Dtrain的最佳NeRF渲染参数ψ,在Dtrain上训练的模型(取RetinaNet为例)最大化验证集Dval表示的下游任务的精度。
近似计算: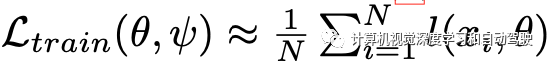
然后基于链式法则得到: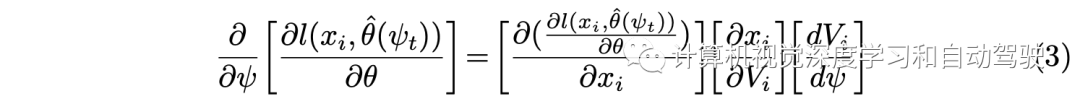
为计算采用一些近似方法:
对于位姿参数离散区间上的分布pψ,提出了一种ψ的重新参数化,提供了dVi/dψ的有效近似(工具 1)。
用一种两次向前一次向后(twice-forward-once-backward)的方法(工具2),大大减少了(2)中梯度近似的内存和计算开销。如果没有这种新技术,实现中需要涉及大矩阵和计算图的高计算开销。
即使使用上述技术,在GPU内存方面,(3)中计算第一项和第二项的开销很大,取决于图像大小。用逐块梯度计算方法(工具 3)克服了这一问题。
关于工具1中重新参数化的实现,采用bin-samplinng,如图所示:首先将位姿空间离散为一组k个bins,然后对其进行采样以生成NeRF的视图参数。为了在采样过程中反向传播,用Gumble softmax的“重新参数化技巧”,从类别(即bin)分布中近似样本。在每个bin中,均匀采样。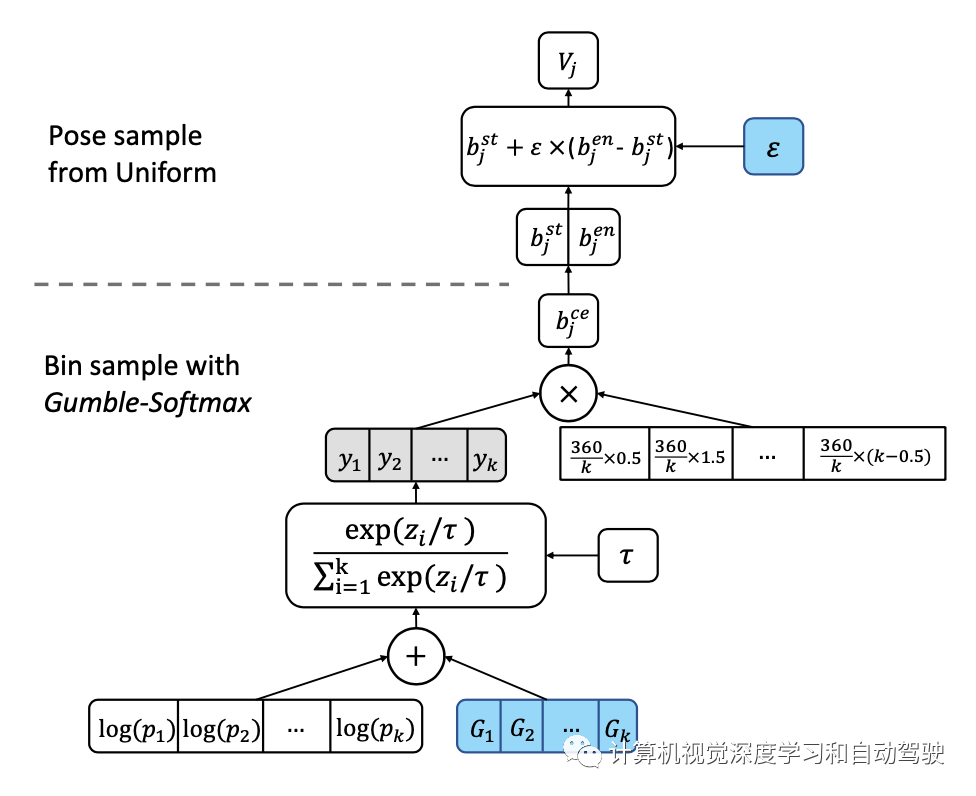
这里y的计算如下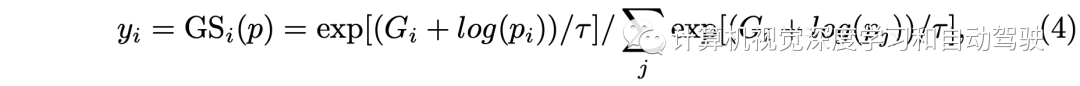
这样?NeRF的计算变成: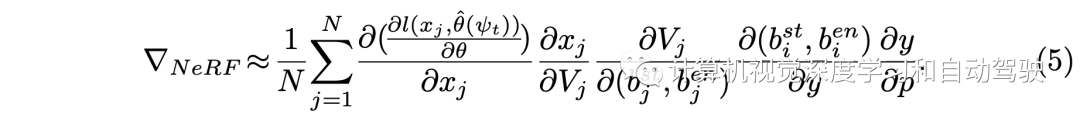
整个梯度计算包括三项:
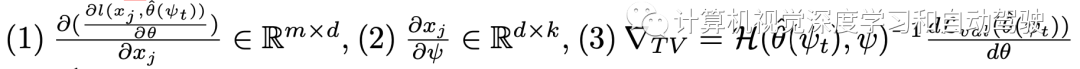 ?
?
而工具2提出的“两次向前一次向后“方法是这样的:在第一个前向路径中,不计算梯度,只渲染图像形成Dtrain,保存用于渲染的y,φj的随机样本。然后,转向梯度计算(3)。在第二次通路NeRF时,保持相同的样本,去计算梯度(1)和(2)。 所谓工具3的逐块梯度计算如下: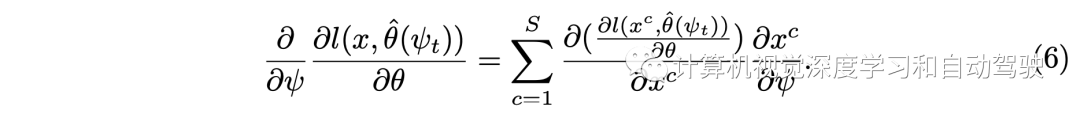
NeRF-in-the-wild(NeRF-w)扩展了普通NeRF模型,允许依赖于图像的外观和照明变化,从而可以显式模拟图像之间的光度差异。
NeRF-w沿观看方向V作为输入的是外观嵌入,表示为l,图像呈现为x=NeRF(V,l)。
对于NERF-w,位姿(V)的优化与上述相同。照明的有效优化,则利用NeRF-w的一个值得注意的特性:允许在颜色和照明之间进行平滑插值。这能够将照明优化为连续变量,其中照明(l)可以写成可用照明嵌入(li)的仿射函数,l = sum(ψi? li)其中sum(ψi)= 1。
为从等式(3)计算梯度,?xi/?l使用工具2和工具3,以与上述相同的方式计算l,并且dl/dψ项计算是直接的,并通过投影梯度下降(projected gradient descent)进行优化。
实现细节如下:用传统渲染Blender-Proc,100幅具有不同摄像头姿态和缩放因子的图像,为每个YCB目标训练一个NeRF-w模型。用RetinaNet作为下游目标检测器。
为了加速优化,在训练期间固定主干。在双层优化步骤中,用Gumble softmax 温度τ = 0.1。在每次优化迭代中,为每个目标类渲染50幅图像,并训练两个epoch的 RetinaNet。
基线方法包括:提出的方法与学习模拟器参数的两种流行方法进行比较。第一个基线是“Learning to simulate (LTS)“,它提出了一种基于REINFORCE的方法来优化模拟器参数。
还要注意,meta-sim是一种基于REINFORCE的方法。接下来,第二个考虑Auto-Sim,它提出了一种学习模拟器参数的有效优化方法。
NS是指提出的方法没有做两层优化的情况,NSO是指提出的方法采用两层优化的情况。
实验结果如下: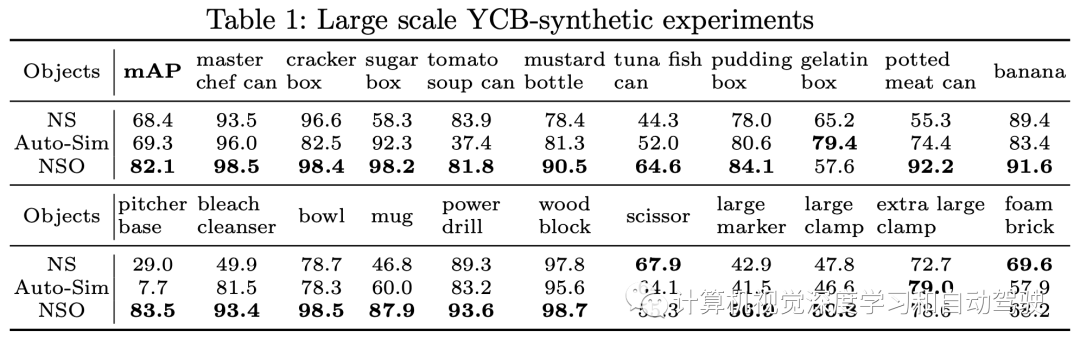
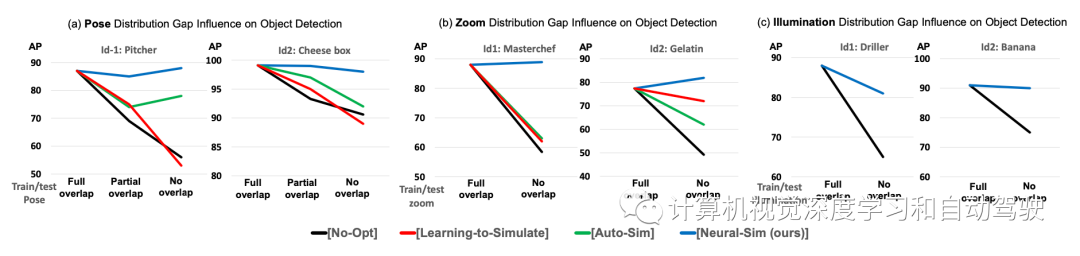
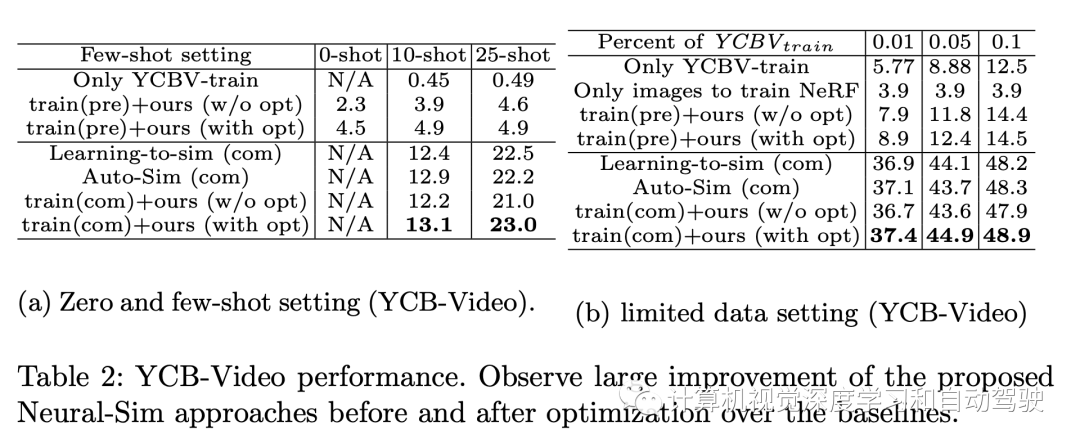
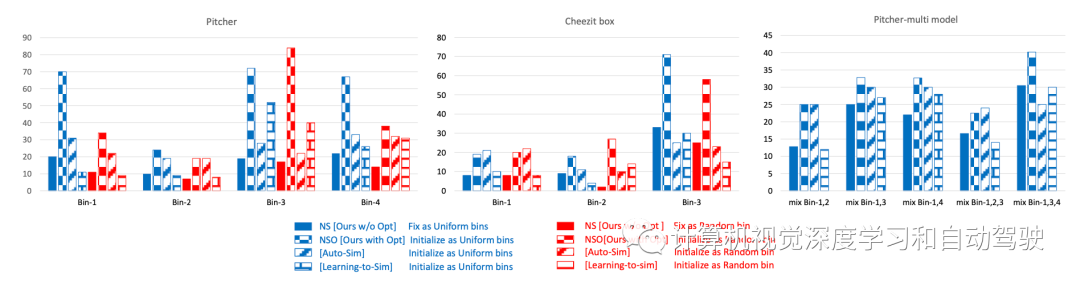
审核编辑:刘清
-
gpu
+关注
关注
28文章
4981浏览量
132161 -
摄像头
+关注
关注
61文章
5002浏览量
99178 -
3D模型
+关注
关注
1文章
76浏览量
16553 -
提取器
+关注
关注
0文章
14浏览量
8199
原文标题:Neural-Sim: 采用NeRF学习如何生成训练数据
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
生成式 AI 重塑自动驾驶仿真:4D 场景生成技术的突破与实践

PCIe协议分析仪在数据中心中有何作用?
KaihongOS操作系统FA模型与Stage模型介绍
适用于数据中心和AI时代的800G网络
一种多模态驾驶场景生成框架UMGen介绍
英伟达GTC2025亮点 NVIDIA推出Cosmos世界基础模型和物理AI数据工具的重大更新
了解DeepSeek-V3 和 DeepSeek-R1两个大模型的不同定位和应用选择
华为支付-(可选)特定场景配置操作
AN-715::走近IBIS模型:什么是IBIS模型?它们是如何生成的?

【「大模型启示录」阅读体验】营销领域大模型的应用
【「大模型启示录」阅读体验】如何在客服领域应用大模型
NVIDIA Isaac Sim满足模型的多样化训练需求
NVIDIA Nemotron-4 340B模型帮助开发者生成合成训练数据






 工商网监
工商网监
评论