 谷歌推出AI模型Gemma 3 270M
谷歌推出AI模型Gemma 3 270M

作者 / 小组产品经理 Olivier Lacombe、研究工程师 Kathleen Kenealy、Kat Black、Ravin Kumar、Francesco Visin、Jiageng Zhang
过去几个月,Gemma 开放模型系列的发展是激动人心的。我们推出了 Gemma 3 和 Gemma 3 QAT,为单一云端和桌面加速器带来了最先进的性能。以移动设备优先的架构 Gemma 3n 的推出,能够将强大的实时多模态 AI 直接应用于边缘设备。我们的目标是为开发者提供使用 AI 进行构建的实用工具,也一直对大家共同创造的 Gemmaverse 生态系统蓬勃发展而倍感欣喜,目前下载量已经突破 2 亿次,让我们共同庆祝这一时刻。
现在,我们在 Gemma 3 工具包中新增了一款高度专业化的工具: Gemma 3 270M。此模型是拥有 2.7 亿参数的紧凑型模型,专为针对特定任务进行微调而设计,并且已内置强大的指令遵循和文本结构化能力。
Gemma 3 270M 为小尺寸模型带来强大的指令遵循能力。正如 IFEval 基准测试 (该测试用于检验模型遵循可验证指令的能力) 所示,它为同尺寸模型确立了新的性能水平,使复杂的 AI 功能更容易用于设备端和研究应用。
Gemma 3 270M 的核心能力
紧凑但功能强大的架构: 我们的新模型总共有 2.7 亿参数: 其中的 1.7 亿是嵌入参数 (因词汇量较大),另外的 1 亿参数用于我们的 Transformer 模块。得益于 256k token 的大词汇量,该模型可以处理特定和罕见的 token,使其成为可在特定领域和语言中进一步微调的强大基础模型。
极致的能效表现: Gemma 3 270M 的一个关键优势是其低功耗。在 Pixel 9 Pro SoC 上进行的内部测试显示,由于采用了 INT4 量化技术,该模型在 25 次对话中仅消耗了 0.75% 的电量,成为我们最节能的 Gemma 模型。
指令遵循: 我们同步发布了指令微调版模型和预训练检查点。虽然此模型并非专为复杂的对话用例而设计,但它是一个强大的模型,能够开箱即用直接遵循一般指令。
可用于生产环境的量化: 量化感知训练 (QAT) 检查点已正式推出,使您能够在 INT4 精度下运行模型,同时将性能损失降至最低,这对于在资源受限的设备上部署模型至关重要。
选择合适的工具
在工程领域,衡量成功的标准在于效率,而不仅仅是原始算力。避免 "大材小用",同样的道理也适用于使用 AI 进行构建。
Gemma 3 270M 体现了 "选择合适的工具" 这一理念。这是一款性能卓越的基础模型,开箱即用即可遵循指令,而通过微调更能释放其全部潜能。经过专业化设置后,模型能以惊人的准确率、速度和成本效益执行文本分类和数据提取等任务。从一款功能强大的紧凑型模型着手,您可以构建出精简、快速且显著降低运营成本的生产系统。
现实世界的成功蓝图
这种方法已经在现实世界中取得了令人惊叹的成果。Adaptive ML 与 SK Telecom 合作完成的项目便是一个绝佳的例证。面对复杂、多语言的内容审核这一挑战,他们选择了走专业化路线。Adaptive ML 没有使用大型通用模型,而是对 Gemma 3 4B 模型进行了微调。结果令人惊叹: 专业的 Gemma 模型在特定任务上的性能不仅比肩、甚至超越了更大规模的专有模型。
Gemma 3 270M 旨在让开发者更进一步地采用这种方法,从而更高效地处理明确的任务。该模型是打造小型专业模型的完美起点,因为每个模型都有各自擅长处理的任务类型。
而且,这种专业化的能力不仅适用于企业任务,还能赋能强大的创意应用。例如下面这款 "睡前故事生成器" Web 应用:
何时选择使用 Gemma 3 270M
Gemma 3 270M 沿袭了 Gemma 3 系列的先进架构和强大的预训练能力,为您的自定义应用奠定了坚实的基础。
理想应用场景如下:
您有大量明确的任务。非常适合情感分析、实体提取、查询路由、非结构化文本到结构化文本的转换、创意写作以及合规性检查等功能。
您需要充分利用每分每秒的时间。大幅降低或消除生产环境中的推理成本,并为用户提供更快的响应速度。经过微调的 270M 模型可以在轻量级、低成本的基础设施上运行,也可以直接在设备上运行。
您需要快速迭代和部署。Gemma 3 270M 体积小巧,可进行快速微调实验,帮助您在数小时而非几天内找到适合用例的理想配置。
您需要确保用户隐私。由于该模型可以完全在设备上运行,因此您可以构建处理敏感信息的应用,而无需将数据发送到云端。
您想拥有一系列能够处理各种任务的专业模型。构建并部署多个自定义模型,每个模型都针对不同的任务经过专业训练,并且不会超出您的预算。
微调入门
我们致力于让每一位开发者都能轻松地将 Gemma 3 270M 打造为专属的定制化解决方案。该模型采用与其他 Gemma 3 模型相同的架构,并配备了相关教程和工具,助您快速入门。您可以
在 Gemma 文档中查阅关于使用 Gemma 3 270M 进行全面微调的指南。
下载模型: 从 Hugging Face、Ollama、Kaggle、LM Studio 或 Docker 获取 Gemma 3 270M 模型。我们将发布经过预训练和指令微调的模型。
试用模型: 在 Vertex AI 或热门推理工具 (如 llama.cpp、Gemma.cpp、LiteRT、Keras 和 MLX) 上试用模型。
开始微调: 使用您最喜欢的工具,包括 Hugging Face、UnSloth 和 JAX。
部署解决方案: 微调完成后,您可以在任何地方部署您的专业模型,从您自己的本地环境到 Google Cloud Run。
Gemmaverse 建立在 "创新无关大小" 这一理念之上。借助 Gemma 3 270M,我们让开发者能够构建更智能、更迅捷、更高效的 AI 解决方案。我们热切期待您创建的专业模型。
-
AI
+关注
关注
88文章
36381浏览量
285268 -
模型
+关注
关注
1文章
3580浏览量
51016
原文标题:Gemma 3 270M 发布 | 兼具轻量化与卓越性能的 AI 模型
文章出处:【微信号:Google_Developers,微信公众号:谷歌开发者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
谷歌Gemma 3n模型的新功能
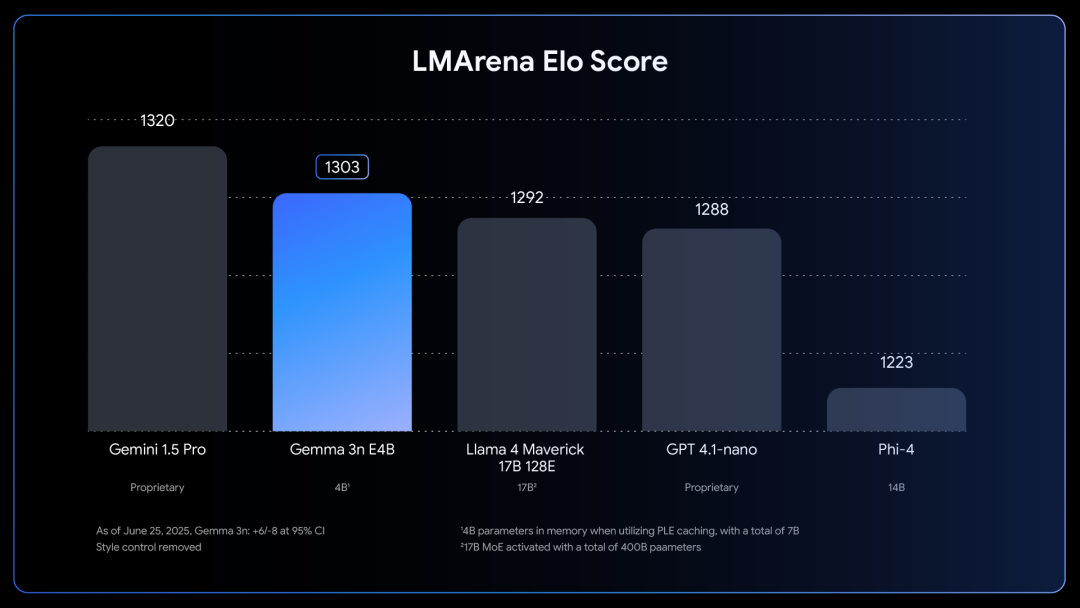
谷歌Gemma 3n预览版全新发布
树莓派5上的Gemma 2:如何打造高效的边缘AI解决方案?

谷歌新一代生成式AI媒体模型登陆Vertex AI平台
谷歌新一代 TPU 芯片 Ironwood:助力大规模思考与推理的 AI 模型新引擎?
Google Gemma 3开发者指南
Google发布最新AI模型Gemma 3
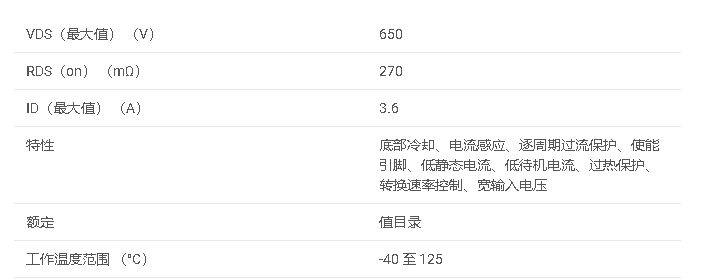
技术文档:LMG3626 650V 270mΩ GaN FET,集成驱动器、保护和电流感应
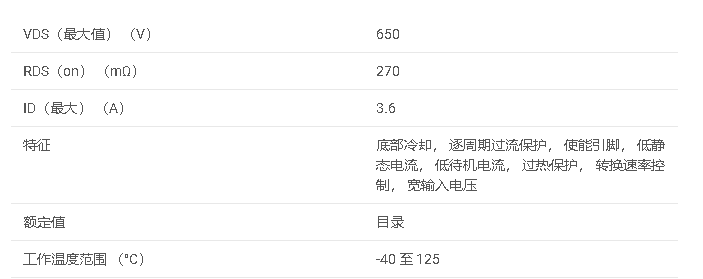
技术文档:LMG3616 具有集成驱动器和保护功能的 650V 270mΩ GaN FET





 工商网监
工商网监
评论