 堪称史上最强推理芯片!英伟达发布 Rubin CPX,实现50倍ROI
堪称史上最强推理芯片!英伟达发布 Rubin CPX,实现50倍ROI

电子发烧友网报道(文/梁浩斌)近日,英伟达在AI infra峰会上发布了专为大规模上下文推理设计的全新GPU系列Rubin CPX,性能堪称炸裂!
英伟达创始人兼CEO黄仁勋表示,“正如 RTX 革新了图形技术与物理 AI,Rubin CPX 则是首款专为大规模上下文 AI 设计的 CUDA GPU—— 在该场景下,模型可一次性基于数百万个token进行推理。”
作为基于Rubin架构的一款AI芯片,Rubin CPX采用了成本效益极高的单芯片设计,集成强大的NVFP4计算资源,其GPU专为AI推理任务优化,可以实现极高的性能和能效比。按照英伟达的说法,Rubin CPX平台可实现 30 至 50 倍的投资回报率(ROI),这意味着1亿美元的资本性支出(CAPEX)投入,能带来高达50亿美元的收入,又呼应了老黄此前的名言“买得越多赚得越多”,这不是新一代“印钞机”吗?
那么Rubin CPX是怎么实现高效AI推理的?
为什么需要Rubin CPX?
要理解Rubin CPX的作用,首先要知道分布式推理的架构原理。
AI推理过程包含两个截然不同的阶段:上下文阶段与生成阶段,这两个阶段对AI基础设施的需求存在本质差异。其中,上下文阶段受计算能力限制,需要通过高吞吐量处理来接收并分析大量输入数据,进而生成首个token输出结果。
与之不同的是,生成阶段受内存带宽限制,需依赖高速内存传输及NVLink等高速互联方案,以维持逐推理单元(token-by-token)的输出性能。
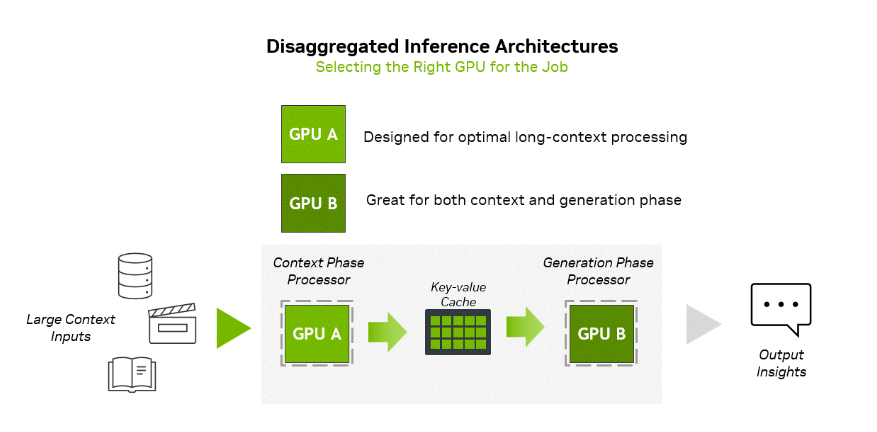 为了提高计算效率,英伟达通过分布式推理可以实现这两个阶段的独立处理,从而对计算和内存资源进行针对性优化。这一架构变革能够提升吞吐量、降低延迟,并提高整体资源利用率。
为了提高计算效率,英伟达通过分布式推理可以实现这两个阶段的独立处理,从而对计算和内存资源进行针对性优化。这一架构变革能够提升吞吐量、降低延迟,并提高整体资源利用率。
具体来说,分布式推理的流程是,文档 / 数据库 / 视频等数据输入至上下文处理器;其输出会传输至键值缓存(KV 缓存),供 GPU B 生成节点读取以生成结果。GPU A 针对长上下文处理进行了优化,而 GPU B 则在上下文阶段与生成阶段均能实现出色的总拥有成本表现。
然而,分布式架构也带来了新的复杂性层级,需要在低延迟 KV 缓存传输、大语言模型感知路由(LLM-aware Routing)及高效内存管理之间实现精准协同。英伟达 Dynamo可作为这些组件的编排层,其功能在最新的 MLPerf 推理基准测试结果中发挥了关键作用。
而分布式推理要发挥出其优势,在上下文处理阶段的效率提升尤为重要。Rubin CPX GPU就是专为解决这个阶段的计算效率的一种解决方案,目标是为高价值长上下文推理工作负载提供高吞吐量性能,同时可无缝集成至分布式基础设施中。
Vera Rubin NVL144 CPX平台:GB300 NVL72的7.5倍性能
Rubin CPX 具备30 petaFLOPs的NVFP4计算能力、128 GB的GDDR7内存、硬件级别的视频解码/编码支持,以及三倍于NVIDIA GB300的注意力机制加速性能。
比如处理视频时,AI模型每处理1小时的内容可能需要多达100 万个token,这突破了传统 GPU的计算极限。Rubin CPX在单芯片中集成了视频解码器与编码器,以及长上下文推理处理功能,从而在视频搜索、高质量生成式视频等长时长应用场景中,实现了前所未有的性能。
同时,英伟达也推出了一套集成Rubin CPX 、NVIDIA Vera CPU、Rubin GPU的完整高性能分布式服务解决方案——NVIDIA Vera Rubin NVL144 CPX。
 ?
?
Vera Rubin NVL144 CPX 图源:英伟达
NVIDIA Vera Rubin NVL144 CPX机架集成144个Rubin CPX GPU、144个Rubin GPU 以及36个 Vera CPU,能够实现8 exaFLOPs的NVFP4计算性能,是GB300 NVL72的7.5倍,同时还提供100 TB的高速内存和高达1.7 PB/s的内存带宽。
Vera Rubin NVL144 CPX采用了NVIDIA Quantum-X800 InfiniBand或Spectrum-X以太网技术,与NVIDIA ConnectX-9 SuperNIC配合使用,并由Dynamo平台进行管理。英伟达表示,在规模化应用中,该平台能够实现30至50倍的投资回报。
 值得一提的是,对于已经订购Vera Rubin NVL144系统的用户,英伟达也提供专用的Rubin CPX 计算托盘,可以在现有的Vera Rubin NVL144系统上拓展推理能力。
值得一提的是,对于已经订购Vera Rubin NVL144系统的用户,英伟达也提供专用的Rubin CPX 计算托盘,可以在现有的Vera Rubin NVL144系统上拓展推理能力。
根据此前英伟达的上市时间表,Rubin架构GPU预计在2026年正式上市,预计在今年9月交付客户测试。而同为Rubin架构的Rubin CPX GPU,英伟达预计会在2026年下半年上市,Vera Rubin NVL144 CPX则预计在2026年底上市。
近日英伟达宣布,年度技术大会GTC2026将会在2026年3月16日至19日举行,预计在大会上将正式推出Rubin GPU和Vera CPU两大产品。
写在最后
Rubin CPX的推出,可以说是AI推理侧的一颗“重磅炸弹”。正如黄仁勋提到的“Rubin CPX 是 AI 推理领域的 RTX”,AI算力硬件正在通过细分场景的优化,实现革命性的效率提升。同时借助Rubin CPX,英伟达开拓了算力硬件的新形式,占领长上下文推理领域的“无人区”。在视频、代码生成等用到巨量Token的领域,未来Rubin CPX可能会占据极为有利的生态位,继续筑牢英伟达在AI基建市场的护城河。
英伟达创始人兼CEO黄仁勋表示,“正如 RTX 革新了图形技术与物理 AI,Rubin CPX 则是首款专为大规模上下文 AI 设计的 CUDA GPU—— 在该场景下,模型可一次性基于数百万个token进行推理。”
作为基于Rubin架构的一款AI芯片,Rubin CPX采用了成本效益极高的单芯片设计,集成强大的NVFP4计算资源,其GPU专为AI推理任务优化,可以实现极高的性能和能效比。按照英伟达的说法,Rubin CPX平台可实现 30 至 50 倍的投资回报率(ROI),这意味着1亿美元的资本性支出(CAPEX)投入,能带来高达50亿美元的收入,又呼应了老黄此前的名言“买得越多赚得越多”,这不是新一代“印钞机”吗?
那么Rubin CPX是怎么实现高效AI推理的?
为什么需要Rubin CPX?
要理解Rubin CPX的作用,首先要知道分布式推理的架构原理。
AI推理过程包含两个截然不同的阶段:上下文阶段与生成阶段,这两个阶段对AI基础设施的需求存在本质差异。其中,上下文阶段受计算能力限制,需要通过高吞吐量处理来接收并分析大量输入数据,进而生成首个token输出结果。
与之不同的是,生成阶段受内存带宽限制,需依赖高速内存传输及NVLink等高速互联方案,以维持逐推理单元(token-by-token)的输出性能。
具体来说,分布式推理的流程是,文档 / 数据库 / 视频等数据输入至上下文处理器;其输出会传输至键值缓存(KV 缓存),供 GPU B 生成节点读取以生成结果。GPU A 针对长上下文处理进行了优化,而 GPU B 则在上下文阶段与生成阶段均能实现出色的总拥有成本表现。
然而,分布式架构也带来了新的复杂性层级,需要在低延迟 KV 缓存传输、大语言模型感知路由(LLM-aware Routing)及高效内存管理之间实现精准协同。英伟达 Dynamo可作为这些组件的编排层,其功能在最新的 MLPerf 推理基准测试结果中发挥了关键作用。
而分布式推理要发挥出其优势,在上下文处理阶段的效率提升尤为重要。Rubin CPX GPU就是专为解决这个阶段的计算效率的一种解决方案,目标是为高价值长上下文推理工作负载提供高吞吐量性能,同时可无缝集成至分布式基础设施中。
Vera Rubin NVL144 CPX平台:GB300 NVL72的7.5倍性能
Rubin CPX 具备30 petaFLOPs的NVFP4计算能力、128 GB的GDDR7内存、硬件级别的视频解码/编码支持,以及三倍于NVIDIA GB300的注意力机制加速性能。
比如处理视频时,AI模型每处理1小时的内容可能需要多达100 万个token,这突破了传统 GPU的计算极限。Rubin CPX在单芯片中集成了视频解码器与编码器,以及长上下文推理处理功能,从而在视频搜索、高质量生成式视频等长时长应用场景中,实现了前所未有的性能。
同时,英伟达也推出了一套集成Rubin CPX 、NVIDIA Vera CPU、Rubin GPU的完整高性能分布式服务解决方案——NVIDIA Vera Rubin NVL144 CPX。
?Vera Rubin NVL144 CPX 图源:英伟达
NVIDIA Vera Rubin NVL144 CPX机架集成144个Rubin CPX GPU、144个Rubin GPU 以及36个 Vera CPU,能够实现8 exaFLOPs的NVFP4计算性能,是GB300 NVL72的7.5倍,同时还提供100 TB的高速内存和高达1.7 PB/s的内存带宽。
Vera Rubin NVL144 CPX采用了NVIDIA Quantum-X800 InfiniBand或Spectrum-X以太网技术,与NVIDIA ConnectX-9 SuperNIC配合使用,并由Dynamo平台进行管理。英伟达表示,在规模化应用中,该平台能够实现30至50倍的投资回报。
根据此前英伟达的上市时间表,Rubin架构GPU预计在2026年正式上市,预计在今年9月交付客户测试。而同为Rubin架构的Rubin CPX GPU,英伟达预计会在2026年下半年上市,Vera Rubin NVL144 CPX则预计在2026年底上市。
近日英伟达宣布,年度技术大会GTC2026将会在2026年3月16日至19日举行,预计在大会上将正式推出Rubin GPU和Vera CPU两大产品。
写在最后
Rubin CPX的推出,可以说是AI推理侧的一颗“重磅炸弹”。正如黄仁勋提到的“Rubin CPX 是 AI 推理领域的 RTX”,AI算力硬件正在通过细分场景的优化,实现革命性的效率提升。同时借助Rubin CPX,英伟达开拓了算力硬件的新形式,占领长上下文推理领域的“无人区”。在视频、代码生成等用到巨量Token的领域,未来Rubin CPX可能会占据极为有利的生态位,继续筑牢英伟达在AI基建市场的护城河。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
gpu
+关注
关注
28文章
5008浏览量
132663 -
英伟达
+关注
关注
22文章
3994浏览量
95227
发布评论请先 登录
相关推荐
热点推荐
揭晓英伟达最强芯片!Blackwell Ultra、Rubin芯片亮相,新机器人压轴
电子发烧友网报道(文/莫婷婷)北京时间3月19日晚间,NVIDIA 创始人兼首席执行官黄仁勋在2025年GTC开发者大会上发表了主题演讲,介绍了英伟达在AI、机器人、加速计算等领域的最新进展,包括

英伟达黄仁勋:我们要做巨型芯片!最强显卡RTX 5090发布,汽车芯片Thor算力翻20倍
50 系列、AI大模型、AI机器人、超小型AI超级计算机,以及英伟达的终极目标:名为Grace Blackwell NVLink72的巨型芯片等。 ? 下面提炼一些关键信息: ? 关


英伟达GTC25亮点:NVIDIA Blackwell Ultra 开启 AI 推理新时代
英伟达GTC25亮点:NVIDIA Blackwell Ultra 开启 AI 推理新时代
英伟达市值一夜蒸发近2万亿 英伟达股价下跌超8%
财年第四财季和全财年业绩数据上看,2025财年第四财季及全年的营收和利润都实现了大幅增长,大家特别关注的数据中心业务也是业绩增长的核心动力,展现出英伟达在AI领域的强大实力。而且英伟
英伟达发布DeepSeek R1于NIM平台
网站上发布。 据悉,DeepSeek R1 NIM微服务是英伟达在人工智能领域的一项重要创新,旨在为用户提供高效、精准的推理服务。在单个英伟

软银携手英伟达打造日本最强AI超算
软银集团近日宣布,将率先采用英伟达最新的Blackwell平台,打造日本最强的AI超级计算机。此举旨在满足日本在人工智能领域快速发展的迫切需求,推动国内AI技术的创新与应用。
英伟达加速Rubin平台AI芯片推出,SK海力士提前交付HBM4存储器
日,英伟达(NVIDIA)的主要高带宽存储器(HBM)供应商南韩SK集团会长崔泰源透露,英伟达执行长黄仁勋已要求SK海力士提前六个月交付用于英伟
英伟达地表最强AI芯片GB200 NVL72服务器遭抢购
10月28日,最新媒体报道显示,配备有英伟达被誉为“地表最强AI芯片”的GB200的AI服务器已开始交付,微软、Meta等行业巨头正积极扩大采购更高端的NVL72型号服务器。
英伟达RTX 50系列显卡价格揭晓:高端版高价引发热议
近期,备受瞩目的科技消息渠道Moore’s Law is Dead在其最新视频披露了英伟达即将面世的GeForce RTX 50系列显卡的预期售价细节。据该渠道透露,英伟
英伟达Blackwell芯片量产加速,Q4预计出货达45万片
摩根士丹利最新发布的报告揭示了英伟达在AI芯片领域的重大进展,其最新力作Blackwell芯片已成功步入量产阶段,预示着





 工商网监
工商网监
评论