 小白学大模型:大模型加速的秘密 FlashAttention 1/2/3
小白学大模型:大模型加速的秘密 FlashAttention 1/2/3

本文转自:Coggle数据科学
在 Transformer 架构中,注意力机制的计算复杂度与序列长度(即文本长度)呈平方关系()。这意味着,当模型需要处理更长的文本时(比如从几千个词到几万个词),计算时间和所需的内存会急剧增加。最开始的标准注意力机制存在两个主要问题:
- 内存占用高:模型需要生成一个巨大的注意力矩阵 (N×N)。这个矩阵需要被保存在高带宽内存 (HBM)中。对于长序列,这很快就会超出 GPU 的内存容量。
- 计算效率低:标准实现会将注意力计算分解成多个独立的步骤(矩阵乘法、softmax 等)。每一步都需要将数据从速度较慢的 HBM 中读取,计算后又写回 HBM。这种频繁的数据移动(内存读写)成为了性能瓶颈,导致 GPU 的计算单元(如 Tensor Cores)利用率低下。
什么是 FlashAttention?
FlashAttention 使得处理长达数万甚至数十万个 token 的超长文本成为可能。这解锁了新的应用场景,例如分析法律文档、总结长篇小说或处理整个代码库。
FlashAttention 使得模型的训练和推理速度更快,尤其是在长序列场景下。例如,FlashAttention-2 在长序列上比标准实现快 10 倍,使得训练成本更低,用户体验更好。
最新的 FlashAttention-3 利用了新硬件(如 NVIDIA H100)的 FP8 精度,进一步提升了性能,同时通过特殊的算法保持了计算的准确性,让模型训练更加高效。
FlashAttention v1
许多研究提出了近似注意力方法,试图通过减少计算量(FLOPs)来提高效率。然而,这些方法通常忽略了GPU不同层级内存(如高速的片上SRAM和相对较慢的高带宽HBM)之间的I/O开销,导致它们在实际运行时并没有带来显著的加速。
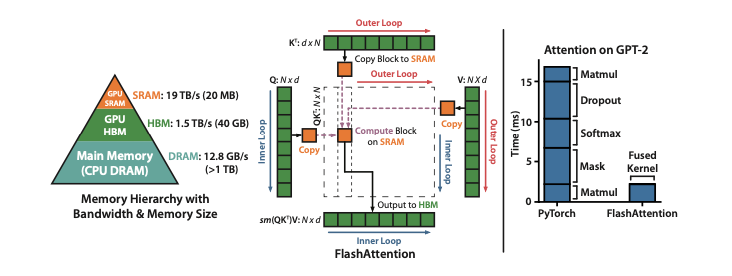
FlashAttention的核心思想是I/O感知,即在设计算法时,将数据在不同层级内存之间的读写开销考虑在内。论文指出,在现代GPU上,计算速度已经远超内存访问速度,因此大多数操作都受限于内存访问。FlashAttention通过以下两个关键技术来解决这一问题:
- Tiling (平铺):将输入数据(Q、K、V矩阵)分割成小块,并在GPU的片上SRAM中进行计算。这样可以避免将庞大的 N×N 注意力矩阵完整地写入到速度较慢的HBM中。
- 内存优化:在反向传播时,FlashAttention 不存储巨大的中间注意力矩阵,而是只保存前向传播中计算出的Softmax归一化因子。这样,反向传播时可以利用这些因子在SRAM中快速地重新计算注意力矩阵,从而避免了从HBM读取大矩阵的开销。
GPU内存层级
- HBM (高带宽内存):容量大(如A100 GPU的40-80 GB),但速度相对较慢(带宽1.5-2.0 TB/s)。
- 片上SRAM (静态随机存取存储器):容量小(每个流式多处理器有192 KB),但速度极快(带宽估计达19 TB/s),比HBM快一个数量级以上。
由于GPU的计算速度增长快于内存速度,许多操作的性能瓶颈在于内存访问,而不是计算本身。因此,如何高效利用快速的SRAM变得至关重要。
运算类型
根据算术强度(每字节内存访问的算术运算次数),操作可分为两类:
- 计算密集型 (Compute-bound):运算时间由算术操作数量决定,内存访问时间相对较小。例如,大规模矩阵乘法。
- 内存密集型 (Memory-bound):运算时间由内存访问次数决定,计算时间相对较小。例如,大多数元素级操作(如激活函数、Dropout)和归约操作(如Softmax、LayerNorm)。
注意力实现改进

给定查询 Q、键 K 和值 V 矩阵,注意力的计算分三步:
- 相似度计算:
- Softmax归一化:
- 加权求和:
标准实现(如“Algorithm 0”所示)将每一步都作为一个独立的GPU核函数,并物化(materialize)中间矩阵 S 和 P 到HBM中。
这种实现方式导致了两个主要问题:
- 巨大的内存占用:中间矩阵 S 和 P 的大小为 N×N,其内存占用与序列长度 N 的平方成正比。
- 大量的HBM访问:由于每个步骤都需要读写HBM,导致I/O开销巨大。论文指出,这种方法对HBM的访问次数是 O(N2) 级别的,这在长序列(通常 N?d)时会成为主要的性能瓶颈,导致运行时间慢。
FlashAttention旨在减少对GPU高带宽内存(HBM)的读写,实现对确切注意力(exact attention)的快速、内存高效的计算。为此,它采用了两种关键技术:
- Tiling(分块):将输入的 Q,K,V 矩阵分成若干小块。然后,在计算过程中,每次只将一小块数据从慢速的HBM加载到快速的片上SRAM进行计算,而不是一次性加载整个大矩阵。
- Recomputation(重计算):为了避免在反向传播时存储 O(N2) 的中间注意力矩阵 S 和 P,FlashAttention只存储 Softmax 的归一化统计量(即 m 和 ?)。在反向传播时,它会利用这些统计量,按需在SRAM中重新计算必要的注意力矩阵块。
通过Tiling和Recomputation,FlashAttention能够将所有计算步骤(矩阵乘法、Softmax、可选的遮蔽和Dropout)融合成一个单一的CUDA核函数。这避免了在每个步骤之间反复地将数据写入HBM。
实现效果
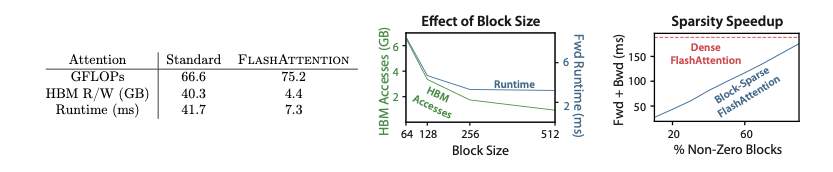
lashAttention在BERT-large模型上的训练速度超过了MLPerf 1.1的记录保持者。与Nvidia的实现相比,FlashAttention的训练时间缩短了15%,这证明了其在标准长序列任务上的卓越性能。

FlashAttention在训练GPT-2模型时,相比于流行的HuggingFace和Megatron-LM实现,实现了显著的端到端加速。
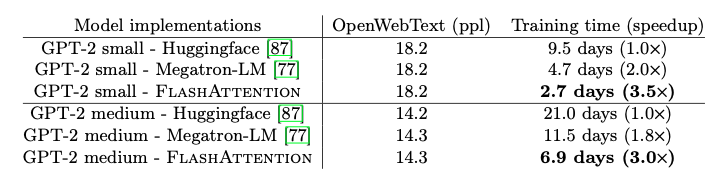
- 与Huggingface相比,速度提升高达3倍。
- 与Megatron-LM相比,速度提升高达1.7倍。
- 重要的是,FlashAttention在不改变模型定义的情况下,实现了与基线模型相同的困惑度(perplexity),证明了其数值稳定性。
在Long-Range Arena基准测试中,FlashAttention相比于标准的Transformer实现,实现了2.4倍的加速。此外,块稀疏FlashAttention的表现甚至优于所有已测试的近似注意力方法,证明了其在处理超长序列时的优越性。
lashAttention的内存占用与序列长度呈线性关系,而标准实现是平方关系。这使得FlashAttention的内存效率比标准方法高出20倍。
FlashAttention v2
第一代FlashAttention通过利用 GPU 内存层次结构的特性,显著降低了内存占用(从二次方降为线性)并实现了 2-4 倍的加速,且没有引入任何近似。
然而,FlashAttention 的效率仍然不如优化的矩阵乘法(GEMM)操作,其浮点运算性能(FLOPs/s)仅能达到理论峰值的 25-40%。这主要是因为 FlashAttention 存在不优化的工作划分(work partitioning),导致 GPU 线程块(thread blocks)和线程束(warps)之间的并行度不足、占用率低或产生不必要的共享内存读写。
为了解决这些问题,论文提出了FlashAttention-2,通过以下改进实现了更好的工作划分:
- 减少非矩阵乘法(non-matmul)的浮点运算:虽然这类操作占总 FLOPs 的比例小,但执行起来很慢。
- 在序列长度维度上并行化:即使对于单个注意力头,也将其计算任务分配给不同的线程块,以提高 GPU 的占用率。
- 优化线程块内部的工作分配:在每个线程块内,重新分配线程束之间的工作,以减少通过共享内存进行的通信。
前向传播改进
FlashAttention-2对在线 Softmax 技巧进行了两处微调:
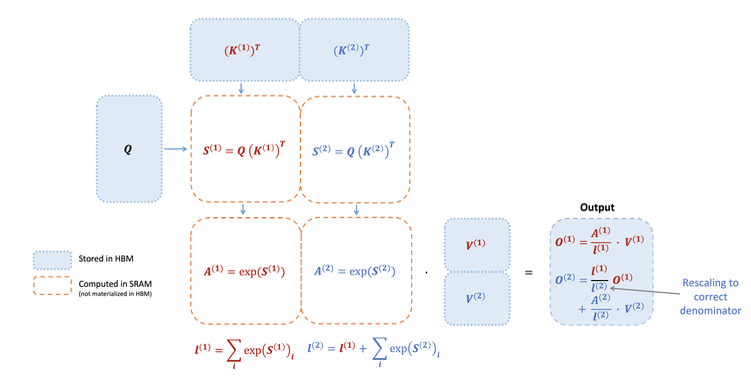
- 延迟归一化:在每个循环迭代中,不立即对输出进行归一化。相反,它维护一个“未缩放”的中间结果,并在整个循环结束时仅进行一次最终的归一化。这减少了每个块的缩放操作,从而减少了非 matmul 的 FLOPs。
- 简化统计量:为反向传播存储数据时,只保存logsumexp统计量 L(j)=m(j)+log(?(j)),而不是同时存储最大值 m(j) 和指数和 ?(j)。
并行化改进
第一代 FlashAttention 仅在批处理大小和注意力头数量上进行并行化。当序列长度很长时,批处理大小通常很小,导致 GPU 资源的利用率(occupancy)不高。FlashAttention-2 通过在序列长度维度上增加并行化来解决这个问题。
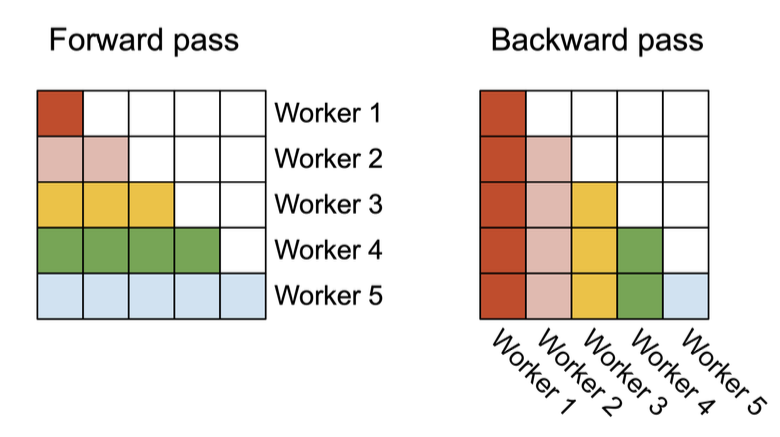
- 前向传播:FlashAttention-2 将注意力矩阵的行块任务分配给不同的线程块,这些线程块之间无需通信。通过在行维度上并行,当批次大小和注意力头数较小时,GPU 的 SM(流式多处理器)能够被更充分地利用,从而提高整体吞吐量。
- 后向传播:类似地,后向传播则在注意力矩阵的列块上进行并行。由于反向传播中的某些更新需要跨线程块通信,作者使用了原子加法(atomic adds)来更新共享的梯度 dK 和 dV,确保了线程安全。
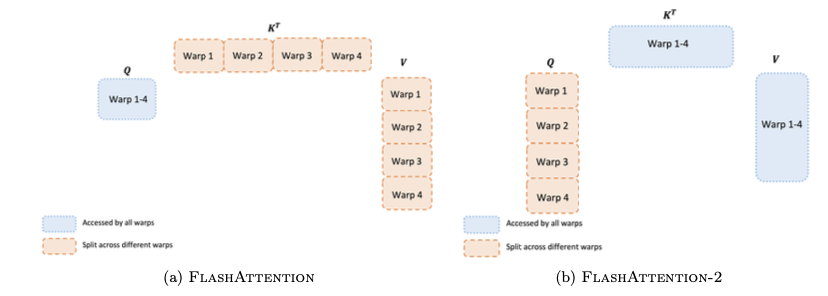
除了线程块级别的并行,FlashAttention-2 还优化了线程块内部线程束之间的工作分配,以减少共享内存的读写。
- 前向传播:
- FlashAttention:采用“split-K”方案,将 K 和 V 矩阵的计算任务分配给不同的线程束。这要求所有线程束将中间结果写入共享内存,再进行同步和求和,导致不必要的共享内存访问。
- FlashAttention-2:改为将 Q 矩阵的计算任务分配给不同的线程束。每个线程束负责计算 Q 的一个分片与完整的 K 的乘积。这样,每个线程束可以独立地完成其部分输出,而无需与其他线程束进行共享内存通信,从而显著提高了效率。
- 后向传播:后向传播的依赖关系更复杂,但 FlashAttention-2 仍然通过避免“split-K”方案来减少共享内存的读写,实现了性能提升。
实现效果
FlashAttention-2 比第一代 FlashAttention 快1.7-3.0 倍,比 Triton 实现的 FlashAttention 快1.3-2.5 倍。
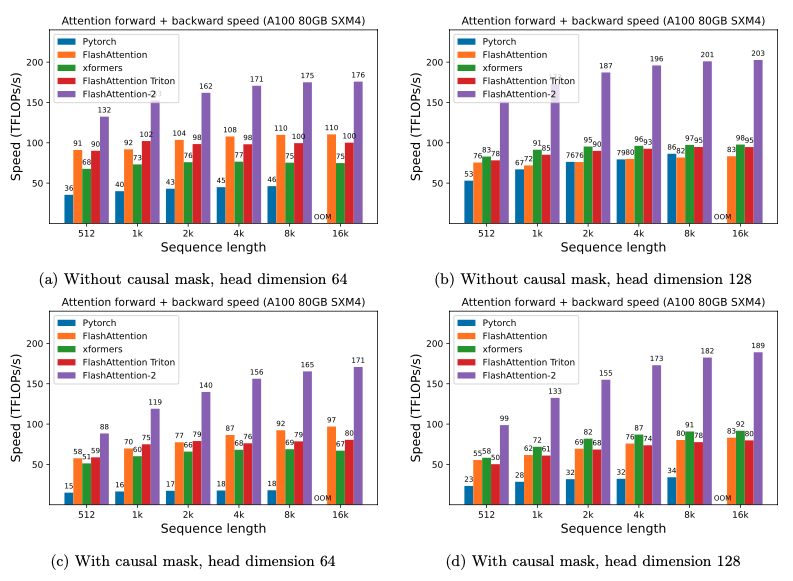
在 A100 GPU 上,FlashAttention-2 在前向传播中达到了230 TFLOPs/s的峰值,相当于理论最大吞吐量的73%。在后向传播中,它达到了理论最大吞吐量的 63%。
FlashAttention v3
虽然之前的 FlashAttention 通过减少内存读写来加速计算,但它未能充分利用现代硬件(如 Hopper GPU)的新特性。例如,FlashAttention-2 在 H100 GPU 上的利用率仅为 35%。
与 FlashAttention-2 类似,FlashAttention-3 也将任务并行化到不同的线程块(CTA),但其创新之处在于在单个线程块内部,将线程束(warps)划分为不同的角色。
- 生产者(Producer):负责将数据从 HBM(全局内存)异步加载到 SMEM(共享内存)。
- 消费者(Consumer):在数据加载完成后,从 SMEM 读取数据并执行计算。
生产者和消费者通过一个循环缓冲区(circular buffer)进行同步。生产者将数据放入缓冲区,消费者从中取出。当缓冲区中的一个“阶段”被消费后,生产者就可以继续向其中加载新数据。
线程内部的 GEMM 和 Softmax 重叠
在标准 FlashAttention 中,GEMM 和 Softmax 存在顺序依赖:Softmax 必须在第一个 GEMM 计算完成后才能开始,而第二个 GEMM 必须等待 Softmax 的结果。
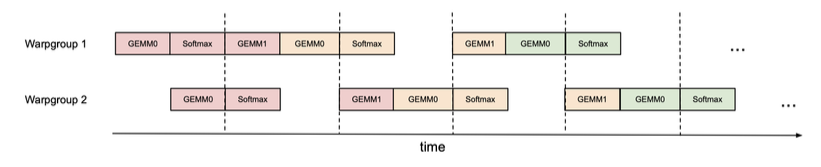
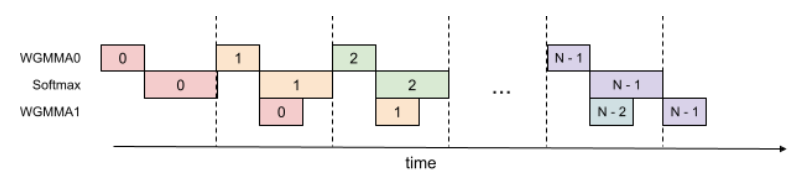
FlashAttention-3 通过在寄存器中使用额外的缓冲区,打破了这种依赖关系。在每次循环中,它异步启动下一个 GEMM 的计算,而同时执行当前 GEMM 结果的 Softmax 和更新操作。这样,GEMM 和 Softmax 的执行就可以重叠,提高了效率。
FP8 低精度计算
FP8 的 WGMMA(Warp Group Matrix-Multiply-Accumulate)指令要求输入矩阵具有特定的k-major 布局,而输入张量通常是mn-major 布局。

FlashAttention-3 选择在 GPU 内核中(in-kernel)进行转置。它利用 LDSM/STSM 指令,这些指令能够高效地在 SMEM 和 RMEM(寄存器)之间进行数据传输,并在传输过程中完成布局转置,避免了代价高昂的 HBM 读写。
同于传统的逐张量(per-tensor)量化,FlashAttention-3 对每个块进行单独量化。这使得每个块可以有自己的缩放因子,从而更有效地处理离群值,减少量化误差。
实现效果
FlashAttention-3 的前向传播速度比 FlashAttention-2 快1.5-2.0 倍,后向传播快1.5-1.75 倍。FP16 版本的 FlashAttention-3 达到了740 TFLOPs/s的峰值,相当于 H100 GPU 理论最大吞吐量的 **75%**。
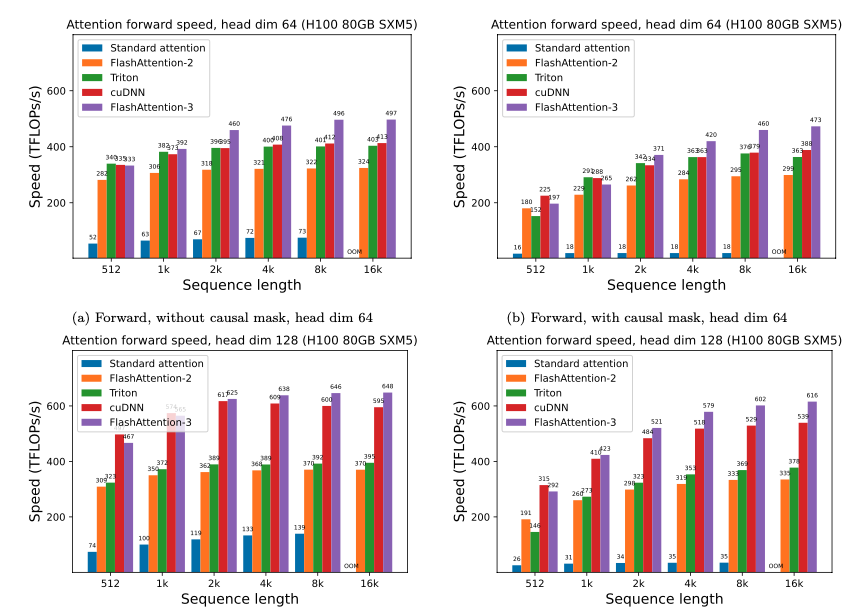
在处理中长序列(1k 及以上)时,FlashAttention-3 的性能甚至超过了 NVIDIA 自家闭源、针对 H100 优化的cuDNN库。
-
内存
+关注
关注
8文章
3143浏览量
75588 -
人工智能
+关注
关注
1811文章
49355浏览量
253597 -
大模型
+关注
关注
2文章
3289浏览量
4385
发布评论请先 登录
压缩模型会加速推理吗?
3D模型基础
小白开始学RTOS 1

如何改进和加速扩散模型采样的方法1
自动驾驶车辆控制(车辆运动学模型)
写给小白的大模型入门科普

小白学大模型:训练大语言模型的深度指南
小白学大模型:从零实现 LLM语言模型
小白学大模型:国外主流大模型汇总





 工商网监
工商网监
评论