 TensorRT-LLM中的分离式服务
TensorRT-LLM中的分离式服务

在之前的技术博客中,我们介绍了低延迟和高吞吐场景的优化方法。对于生产部署,用户还关心在满足特定延迟约束的情况下,每个 GPU 的吞吐表现。本文将围绕“吞吐量-延迟”性能场景,介绍 TensorRT-LLM 分离式服务的设计理念、使用方法,以及性能研究结果。
初衷
LLM 推理通常分为上下文 (prefill) 和生成 (decode) 两个阶段。在上下文阶段,模型会根据提示词计算键值 (KV) 缓存,而在生成阶段,则利用这些缓存值逐步生成每一个 Token。这两个阶段在计算特性上存在显著差异。
LLM 推理请求的服务方式有两种:
聚合式 LLM 服务(在本文中有时也称为 IFB):上下文和生成阶段通常在同一个 GPU 上运行。
分离式 LLM 服务:上下文和生成阶段通常在不同 GPU 上运行。
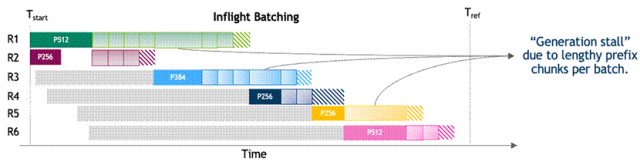
图 1. 聚合式 LLM 服务执行时间线
(该图片来源于 NVIDIA 团队论文:Beyond the Buzz:
A Pragmatic Take on Inference Disaggregation,若您有任何疑问或需要使用该图片,请联系该文作者)
在聚合式 LLM 服务中,上下文和生成阶段共享相同的 GPU 资源和并行策略。这种资源耦合会干扰上下文阶段的 Token 生成速度,并且增加 Token 间延迟 (TPOT),从而影响用户交互体验,正如图 1:聚合式 LLM 服务的执行时间线所示。聚合式 LLM 服务还强制两个阶段使用相同的 GPU 类型和并行配置,尽管它们的计算需求并不相同。在这种耦合约束下,优化某一项指标(如首 Token 生成时间 TTFT)往往会以牺牲另一项指标 (如 TPOT) 为代价。
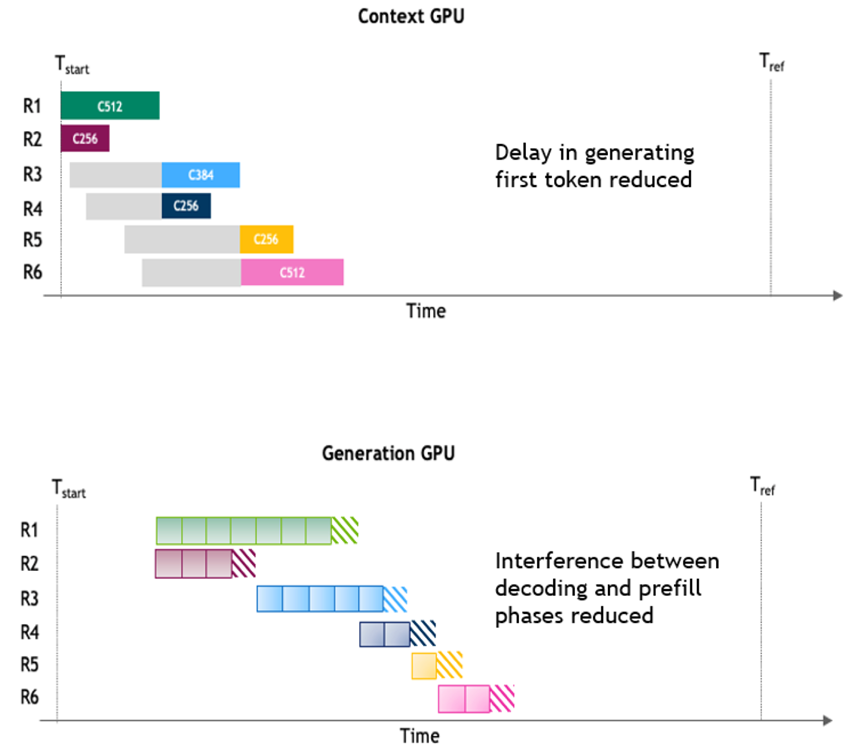
图 2. 分离式 LLM 服务执行时间线
(该图片来源于 NVIDIA 团队论文:Beyond the Buzz:
A Pragmatic Take on Inference Disaggregation,若您有任何疑问或需要使用该图片,请联系该文作者)
分离式服务通过解耦上下文阶段与生成阶段有效解决了上述问题。两个阶段可分别运行在不同的 GPU 池上,并采用各自优化的并行策略,从而避免了资源干扰。如图 2 所示,这种分离式的运行方式消除了上下文和生成阶段之间性能冲突,使得 TTFT 和 TPOT 能够分别进行针对性优化。尽管在两个阶段之间传输 KV 缓存块会带来一定开销,但在输入序列较长、输出长度适中的工作负载下,这种架构的优势依然十分显著——尤其是在此类场景中,IFB 干扰最为严重。
关于更多分离式服务的原理和设计细节,请参考这篇论文:
https://arxiv.org/pdf/2506.05508
使用 TensorRT-LLM 执行分离服务
使用 TensorRT-LLM 进行 LLM 分离式推理共有三种不同方法,每种方法在架构设计和运行特性上各具优势,适用于不同的部署场景。
trtllm-serve
trtllm-serve是一个命令行工具,用于部署与 OpenAI 兼容的 TensorRT-LLM 服务。
使用 TensorRT-LLM 进行 LLM 分离式推理的第一种方法是通过trtllm-serve为每个上下文和生成实例分别启动独立的 OpenAI 服务。同时,trtllm-serve还会启动一个称为“分离服务器”的调度器,用于接收客户端请求,并通过 OpenAI REST API 将请求分发至对应的上下文或生成服务器。图 3 展示了该方法的工作流程。当上下文实例完成提示词的 KV 缓存生成后,会将结果返回给分离式服务器,其中包含提示词 Token、首个生成Token以及与上下文相关的元数据(称为ctx_params)。这些参数随后被生成实例用于与上下文实例建立连接,并检索与请求相关的 KV 缓存块。
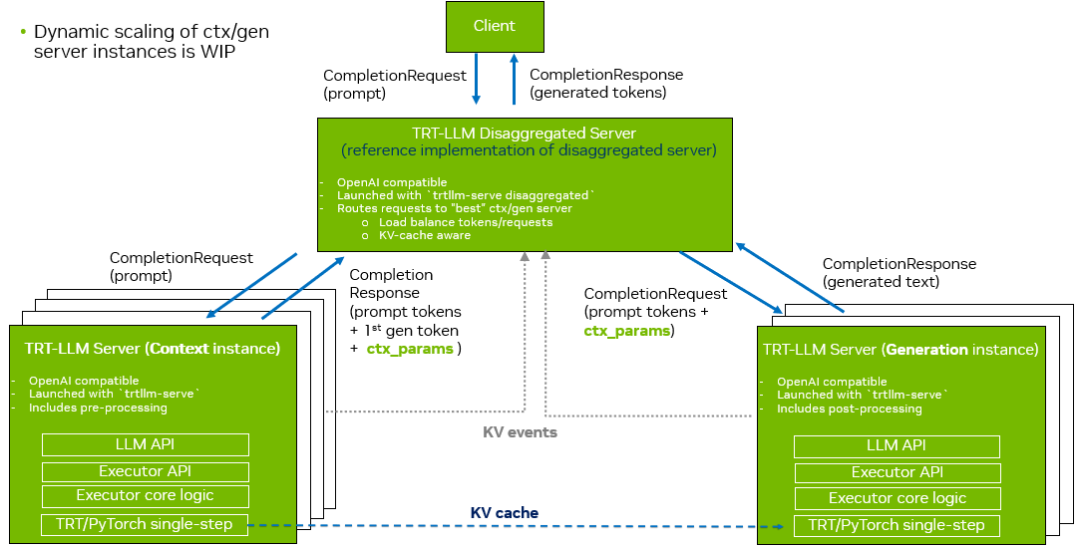
图 3. 使用 trtllm-serve 进行分离式服务
在以下示例中,上下文阶段的服务分别运行在端口 8001 和 8002 上,生成阶段的服务则分别在端口 8003 和 8004 上。分离式服务器监听端口 8000,用于接收客户端请求,并在上下文与生成阶段之间进行调度。
# Launching context servers trtllm-serve TinyLlama/TinyLlama-1.1B-Chat-v1.0--host localhost --port8001--kv_cache_free_gpu_memory_fraction0.15&> output_ctx0 & trtllm-serve TinyLlama/TinyLlama-1.1B-Chat-v1.0--host localhost --port8002--kv_cache_free_gpu_memory_fraction0.15&> output_ctx1 & # Launching generation servers trtllm-serve TinyLlama/TinyLlama-1.1B-Chat-v1.0--host localhost --port8003--kv_cache_free_gpu_memory_fraction0.15&> output_gen0 & trtllm-serve TinyLlama/TinyLlama-1.1B-Chat-v1.0--host localhost --port8004--kv_cache_free_gpu_memory_fraction0.15&> output_gen1 & # Launching disaggregated server trtllm-serve disaggregated -c disagg_config.yaml
# disagg_config.yaml hostname: localhost port: 8000 context_servers: num_instances: 2 router: type: round_robin urls: -"localhost:8001" -"localhost:8002" generation_servers: num_instances: 2 urls: -"localhost:8003" -"localhost:8004"
分离式服务支持多种负载均衡策略,包括轮询 (round-robin) 及基于 KV 缓存的路由。此外,该架构已支持动态扩缩容,能够灵活应对不同规模的推理负载。
了解更多信息,请参见示例:
https://github.com/NVIDIA/TensorRT-LLM/tree/main/examples/disaggregated#trt-llm-disaggregated-serving
Dynamo
第二种方法是使用Dynamo—— 一个专为 LLM 工作负载设计的数据中心级推理服务器。Dynamo 提供了许多高级功能,包括预处理与后处理线程的解耦,特别适用于高并发场景。其工作流程如图 4 所示。
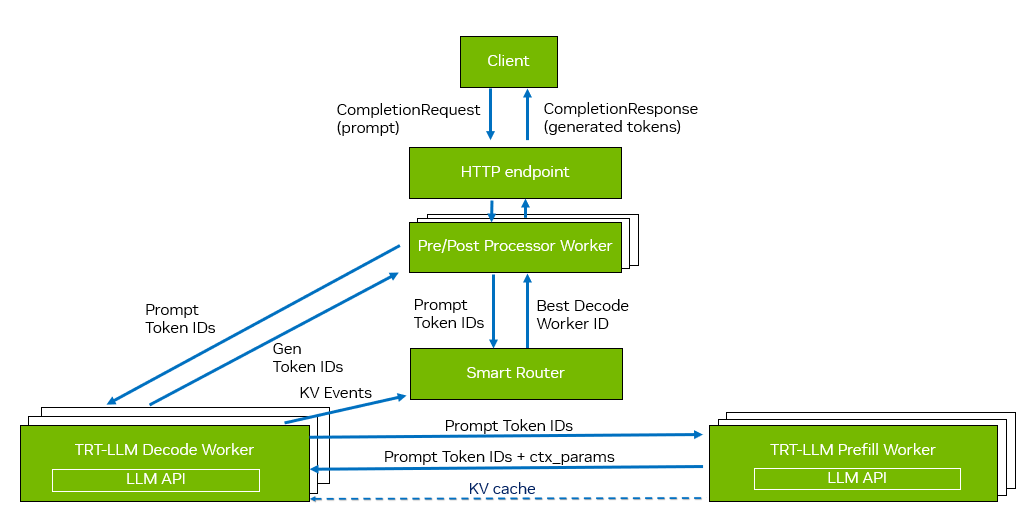
图 4. 使用 Dynamo 进行分离服务
在 Dynamo 的工作流程中,首先由预处理和后处理工作线程处理请求,随后它们会查询智能路由器,以确定将请求路由到哪个最优的生成器。根据 KV 缓存块的可用性,生成器可能跳过上下文阶段,或将请求转发至上下文工作线程。一旦上下文阶段完成提示词的处理,KV 缓存块即可通过上图所示的 ctx_params 元数据发送至生成阶段,用于后续的 Token 生成。
Dynamo 还内置了对 Kubernetes 部署、监测和指标采集的支持。我们正在积极推进动态实例扩展,进一步提高其在生产环境中的适用性与弹性。
更多有关如何将 Dynamo 与 TensorRT-LLM 集成的信息,请参见此文档:
https://docs.nvidia.com/dynamo/latest/examples/trtllm.html
Triton 推理服务
第三种方法是使用 Triton 推理服务器,通过 Triton 的 ensemble 模型实现分离式推理。该模型由预处理器、调度器(基于 Python BLS 后端)和后处理器组成。如图 5 所示,调度器负责将客户端请求路由至上下文和生成实例,管理提示 Token 的流转,并处理生成 Token 的返回结果。该方法依赖于 Triton 的 TensorRT-LLM 后端及其 Executor API,目前仅支持 TensorRT 后端。如需了解更多信息,请参阅此文档:
https://github.com/NVIDIA/TensorRT-LLM/tree/main/triton_backend/all_models/disaggregated_serving#running-disaggregated-serving-with-triton-tensorrt-llm-backend
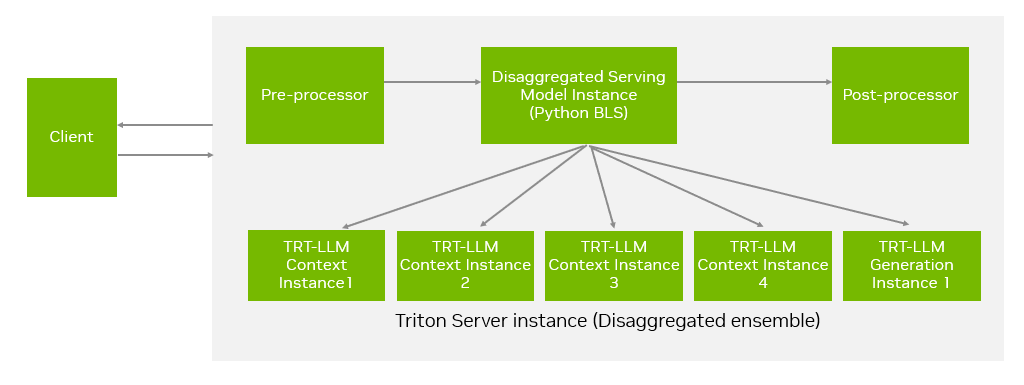
图 5. 使用 Triton 进行分离服务
KV 缓存传输
多后端支持
如图 6 所示,在 TensorRT-LLM 中,KV 缓存交换模块、KV 缓存管理器及底层通信库采用模块化解耦设计。KV 缓存交换模块负责高效传输缓存、及时释放缓存空间,并在交换过程中按需转换缓存布局。目前,TensorRT-LLM 支持主流通信协议,包括 MPI、UCX 和 NIXL,其底层通信协议采用 RDMA / NVLink。我们推荐使用 UCX 和 NIXL 后端,因为它们支持动态扩缩容功能,使用户能够根据流量需求调整负载,或在上下文和生成角色之间进行动态切换。
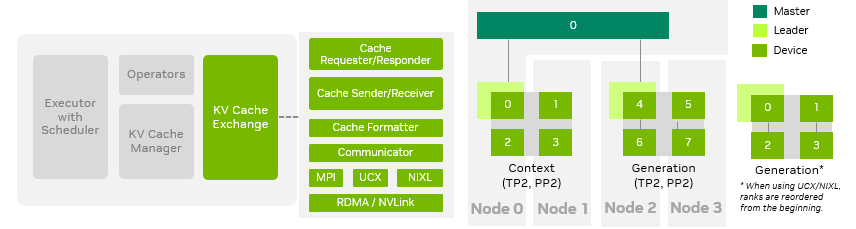
图 6. KV 缓存交换架构
并行优化
为了提高分离式服务的整体性能,TensorRT-LLM 将 KV 缓存传输与请求计算过程重叠。如图 7 所示,当一个请求正在发送或接收其 KV 缓存块时,其他请求可以继续进行计算。此外,如果上下文或生成阶段使用了多个 GPU,不同 GPU 之间的 KV 缓存传输也可以并行进行。
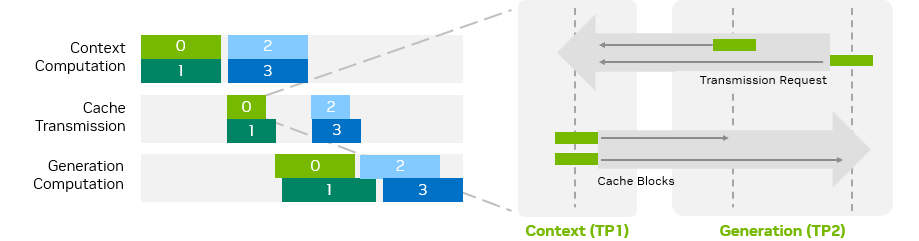
图 7. KV 缓存交换时序图
缓存布局转换
为了最大限度地降低 KV 缓存传输延迟,TensorRT-LLM 采用在设备显存间直接传输缓存的方式。KV 缓存传输支持在上下文和生成阶段采用不同的并行策略,此时需谨慎地映射两个阶段间的对 KV 缓存块布局。图 8 通过一个示例进行了说明:上下文阶段采用 TP2 并行策略,而生成阶段采用 PP2 并行策略。在这种异构并行配置下,缓存块的正确布局映射至关重要。
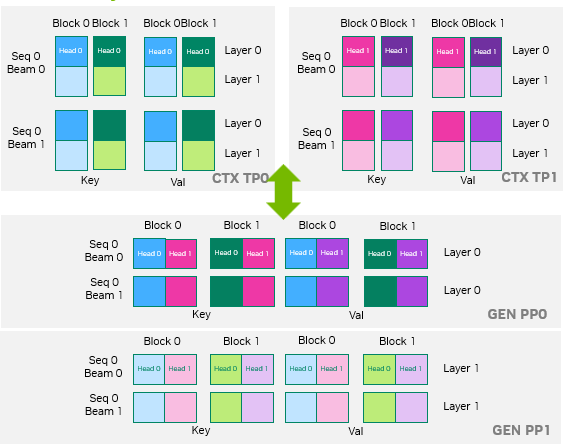
图 8. KV 缓存布局转换
KV 缓存传输所需的优化策略会因具体部署环境而异,例如单节点多 GPU、多节点多 GPU 或 不同 GPU 种类。为此,TensorRT-LLM 提供了一组环境变量,供用户根据实际运行环境灵活选择和配置,以实现最佳性能。详情请参见此文档:
https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/advanced/disaggregated-service.md
性能分析
测量方案
如果要生成 LLM 分离服务的性能曲线,需全面覆盖并行化策略的组合,比如 TP(张量并行)、EP(专家并行)、DP(数据并行)、PP(流水线并行),以及其他优化方法,如投机采样(例如 MTP)。这些组合必须分别在上下文阶段和生成阶段进行评估。随着上下文 (CTX) 和生成 (GEN) 服务器数量的增加,可能的配置数量呈指数级增长,评估复杂度也随之提升。
为了确定最佳配置,我们将测量过程分为两步:
速率匹配
测量上下文服务器的请求吞吐量(以请求数 / 秒 / GPU 为单位),针对满足 TTFT 约束的不同 TP / EP / DP / PP 映射,选择最优配置。
针对不同的 TP / EP / DP / PP 映射、并发级别,以及投机采样开关的情况,测量生成服务器的总吞吐量(以Token/ 秒为单位)和延迟(以Token/ 秒 /用户为单位)。
确定上下文服务器与生成服务器的比例,使得在给定工作负载的输入序列长度 (ISL) 和输出序列长度 (OSL) 下,上下文服务器的总吞吐量与生成服务器的总吞吐量相匹配。
使用以下公式计算每个 GPU 的吞吐量:

一旦计算出上下文与生成服务器的最佳比例,即可构建“速率匹配”帕累托曲线 (Pareto curve),以便在不同延迟(Token / 秒 / 用户)下识别最佳配置。
端到端性能测量
在考虑可用 GPU 总数量的实际限制的前提下,对最具优势的配置进行trtllm-serve分离式部署的基准测试。
DeepSeek R1
我们在 ISL 和 OSL 不同的数据集上对 DeepSeek R1 进行了性能测试。以下所有实验均在 NVIDIA GPU 上进行。
ISL 4400 - OSL 1200(机器翻译数据集)
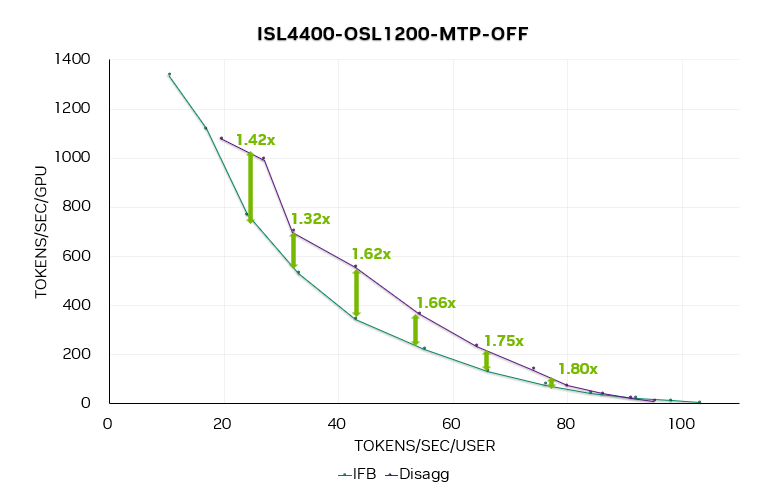
图 9. 关闭 MTP 时的 DeepSeek R1“速率匹配”帕累托曲线
图 9 是 DeepSeek R1 在关闭 MTP 时的速率匹配帕累托曲线。该曲线考虑了 ADP 和 ATP 配置,每个实例使用 4、8、16 或 32 个 GPU。分离式实现的加速比为1.4 至 1.8 倍,尤其在低并发水平下效果更为显著。
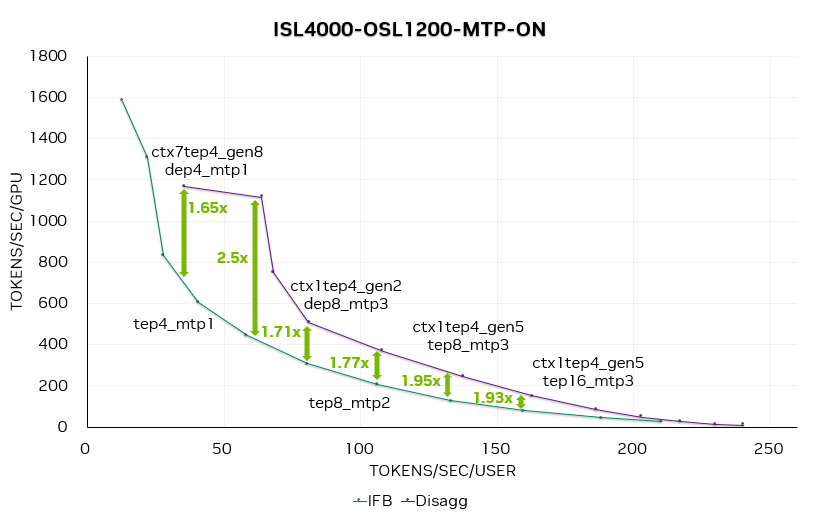
图 10. 启用 MTP 时的 DeepSeek R1 帕累托曲线
我们在性能曲线中选取一些数据点标注了上下文 / 生成实例的数量和并行策略。例如,CTX=1xTEP-4|GEN=2xDEP-8表示由 1 个 TEP4 上下文实例和 2 个 DEP8 生成实例组成一个完整的 LLM 处理实例。
如图 10 所示,启用 MTP 后,分离式服务相较于聚合式服务的加速比进一步提升,平均比关闭 MTP 时高出 20% 至 30%。
ISL 8192 - OSL 256(合成数据集)
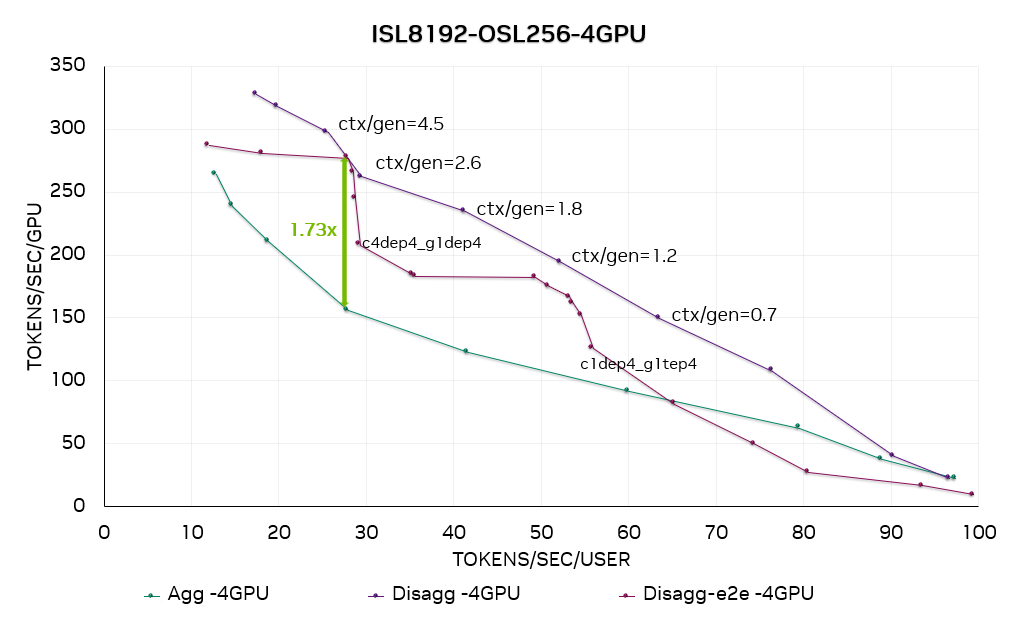
图 11. DeepSeek R1 4-GPU 帕累托曲线。ctx/gen=4.5 表示上下文与生成阶段的 SOL 速率匹配,该配置仅用于 SOL 性能收集。c4dep4_g1dep4 表示 4 个 DEP4 上下文实例加上 1 个 DEP4 生成实例组成一个完整的 LLM 服务实例。
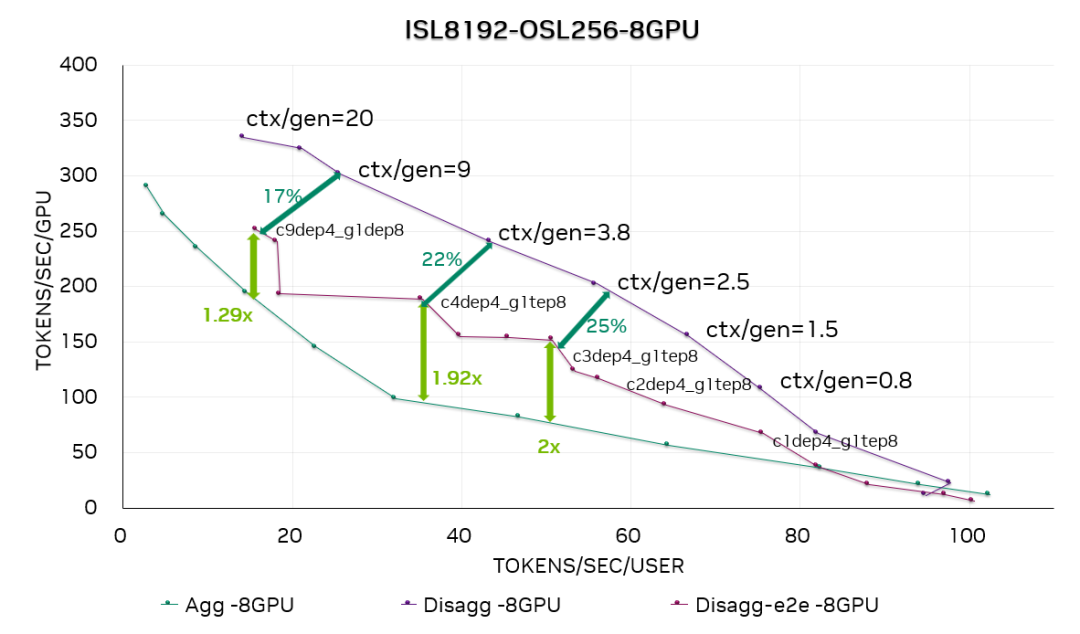
图 12. DeepSeek R1 8-GPU 帕累托曲线
图 11 和图 12 分别是在每个生成实例使用 4 个 GPU (GEN4) 和 8 个GPU (GEN8) 的情况下,在 DeepSeek R1 上运行 ISL8192-OSL256 数据集的性能曲线。我们同时绘制了分离式服务的“速率匹配”结果(基于上下文与生成阶段之间的理想速率匹配)和端到端结果(用户可在生产部署环境中直接复现该结果)。
结果显示,在此 ISL / OSL 设置下,分离服务的性能明显优于合并服务——在 GEN4 配置下加速比最高可达1.73 倍,GEN8 配置下最高可达2 倍。
通过将分离式服务的端到端结果与“速率匹配”曲线进行比较,我们观察到性能差距在 0%–25% 之间。这种差异是符合预期的,因为 SOL 性能依赖于理想化假设,例如 ctx:gen 比例极小、KV 缓存传输不产生开销等。
ISL 4096 - OSL 1024(机器翻译数据集)
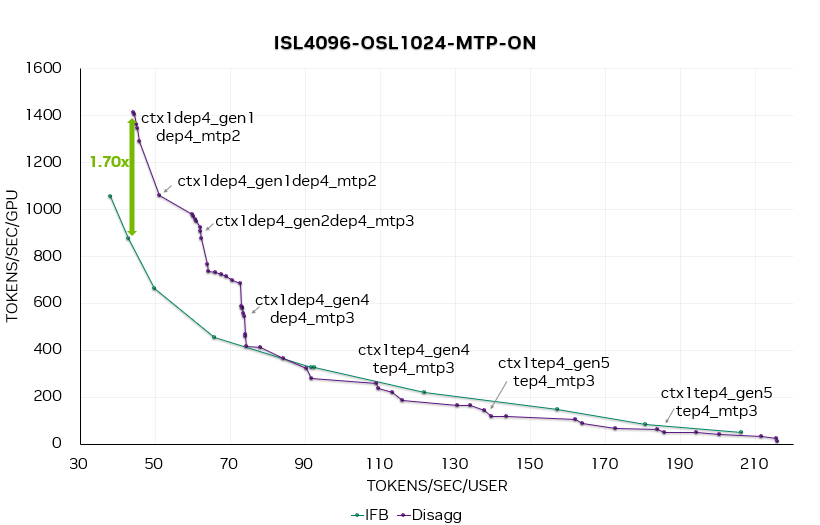
图 13. DeepSeek R1 端到端帕累托曲线,MTP = 1、2、3。在此图中,ctx1dep4-gen2dep4-mtp3 表示 1 个 DEP4 上下文实例加 2 个 DEP4 生成实例,且 MTP = 3。
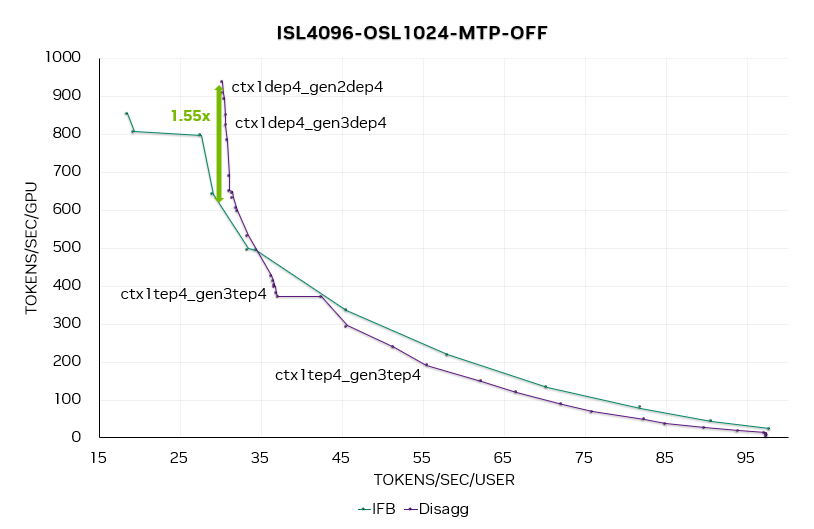
图 14. 关闭 MTP 时的 DeepSeek R1 端到端帕累托曲线
图 13 和 14 分别为合并服务和分离服务在开关 MTP 时的端到端帕累托曲线。
在 MTP = 1、2、3 的帕累托曲线上,可以观察到,在 50 Token / 秒 / 用户(20 毫秒延迟)时,分离服务的性能提升达1.7 倍。随着并发度的提高,启用 MTP 能够带来更大的性能收益。
Qwen 3
ISL 8192 - OSL 1024(机器翻译数据集)
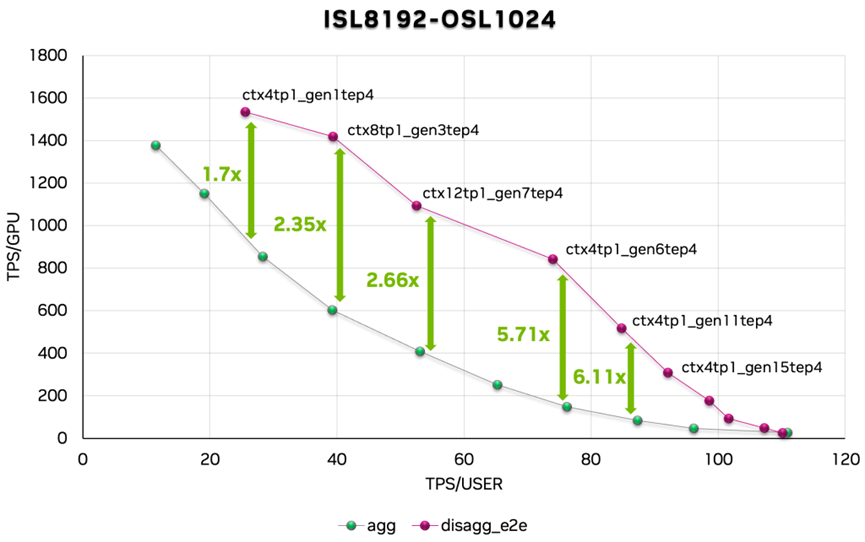
图 15. Qwen 3 帕累托曲线
我们还对 Qwen 3 进行了性能评估。数据显示,分离服务实现的加速比在 1.7 至 6.11 倍之间。
性能复现
我们提供了一组脚本用于复现本论文中展示的性能数据。请参见此文档中的使用说明:
https://github.com/NVIDIA/TensorRT-LLM/tree/main/examples/disaggregated/slurm
工作展望
我们已经通过使用 TensorRT-LLM 进行 LLM 分离式推理获得了性能优势,我们还将会进一步提高性能和易用性,所需的工作包括:
提供详细的步骤和脚本,以自动化生成用于比较聚合式与分离服务的吞吐量-延迟性能曲线。
继续提升大规模部署场景下的性能(如大规模 EP)。
支持根据流量负载动态调整上下文和生成实例。
支持按层计算传输KV 缓存。
致谢
在 TensorRT-LLM 中增加分离式服务支持是一个典型的跨团队协作项目,需要在内核级优化、运行时增强以及系统化性能分析与调优等方面紧密配合。我们为这支敬业乐群的工程师团队感到骄傲,正是他们深厚的专业知识大幅提升了 TensorRT-LLM 的整体性能。除本文作者外,我们诚挚感谢 Iman Tabrizian、张顺康、段政和网络团队等同事为项目所作的代码贡献。通过此次协作,团队在进一步提升大语言模型推理的 GPU 利用率方面积累了宝贵经验。我们希望本文能够为开发者社区提供有益参考,助力大家在关键 LLM 推理应用中更充分地释放 NVIDIA GPU 的潜力。
关于作者
Patrice Castonguay
NVIDIA TensorRT-LLM 的首席软件工程师,拥有计算流体力学 (CFD) 背景。他长期领导开发面向稀疏线性代数、语音识别、语音合成及大型语言模型的 GPU 加速库。并拥有斯坦福大学航空航天学博士学位。
陈晓明
NVIDIATensorRT-LLM 性能团队的首席架构师和高级经理,对深度学习模型的算法软硬件协同设计感兴趣,最近在做大语言模型推理的性能建模、分析和优化。
石晓伟
NVIDIA 软件工程师,目前主要参与 TensorRT-LLM 框架开发及性能优化。
朱闯
NVIDIA 软件工程师,目前主要从事 TensorRT-LLM 大语言模型的推理优化。
乔显杰
NVIDIA Compute Arch 部门高级架构师, 主要负责 LLM 推理的性能评估和优化。加入 NVIDIA 之前,他曾从事推荐系统的 GPU 加速研发工作。
Jatin Gangani
NVIDIA 深度学习计算团队的高级计算架构师,专注于提升数据中心中 AI 推理的软硬件性能。他近期的工作重点是优化 TensorRT-LLM 软件的性能表现。拥有北卡罗来纳州立大学计算机工程硕士学位。
-
NVIDIA
+关注
关注
14文章
5370浏览量
106949 -
gpu
+关注
关注
28文章
4990浏览量
132275 -
模型
+关注
关注
1文章
3560浏览量
50821 -
LLM
+关注
关注
1文章
331浏览量
960
原文标题:TensorRT-LLM 中的分离式服务
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践

如何在魔搭社区使用TensorRT-LLM加速优化Qwen3系列模型推理部署
分离式液位传感器代替浮球传感器的优势
分离式热管换热器的综合利用

简述机电分离式水表中的磁阻芯片使用注意事项
可直接访问的分离式内存DirectCXL应用案例
现已公开发布!欢迎使用 NVIDIA TensorRT-LLM 优化大语言模型推理

NVIDIA加速微软最新的Phi-3 Mini开源语言模型
魔搭社区借助NVIDIA TensorRT-LLM提升LLM推理效率
TensorRT-LLM低精度推理优化

NVIDIA TensorRT-LLM Roadmap现已在GitHub上公开发布

解锁NVIDIA TensorRT-LLM的卓越性能
在NVIDIA TensorRT-LLM中启用ReDrafter的一些变化






 工商网监
工商网监
评论