 新思科技如何破解边缘AI部署难题
新思科技如何破解边缘AI部署难题

神经处理单元(NPU)是一种专为人工智能(AI)神经网络和深度学习任务设计的专用处理器,随着技术从卷积神经网络(CNN)演进至Transformer模型,再到如今的生成式人工智能(GenAI)模型,NPU也需要随之演进。GenAI(尤其是大语言模型LLM)的参数量与日俱增,对带宽的需求更是永无止境,正促使嵌入式AI硬件中所用的数据格式发生转变,包括向低精度和浮点格式发展的趋势,例如新兴的OCP微缩放(MX)数据类型。
卷积神经网络及后续演进
早在2012年,卷积神经网络(CNN)便已超越数字信号处理解决方案,成为图像特征分析、目标检测等视觉处理任务的默认标准。CNN算法的训练与推理最初采用32位浮点(FP32)数据类型,但没过多久,推理引擎就找到了优化CNN引擎功耗与面积的方法,对于面向边缘设备的应用而言尤为重要。在精度损失极小的前提下,8位整数(INT8)成为高吞吐量应用场景下CNN算法的标准格式。当时占据主导地位的AI框架TensorFlow为INT8提供了坚实可靠的支持,不过使用INT8数据类型需要进行训练后量化与校准。
2017年,Transformer神经网络问世(Google发表了《Attention Is All You Need》论文)。由于引入了注意力机制,相较于进行图像分类的CNN,Transformer对INT8量化更为敏感。16位浮点(FP16)和脑浮点(BF16)由此成为Transformer常用的替代数据类型。
Transformer开启了当前的GenAI模型时代,但GenAI模型的参数规模比CNN和许多视觉Transformer高出几个数量级。比如,典型的CNN算法可能需要2500万个参数,而ChatGPT则需要1750亿个参数。参数量的大幅增加导致NPU的计算需求与内存带宽需求之间出现失衡。正如图1所示,面向AI神经网络工作负载的GPU性能增长速度,远快于互连带宽能力的提升速度。
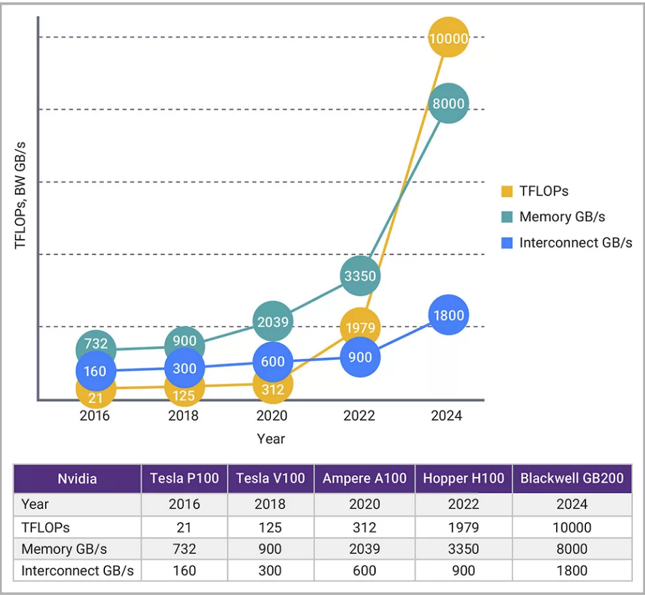
▲图1:AI性能(TOPS)的增长速度,超过了互连带宽(GB/s)的增长速度。
GPU通常用于AI训练和服务器工作负载,而NPU则是AI推理的首选AI处理器;在推理场景中,低功耗和小面积是核心诉求。随着NPU开始处理GenAI工作负载,其计算能力与接口带宽之间的不匹配问题愈发棘手。用于边缘设备的NPU通常配备LPDDR5内存接口,与服务器应用中常用的HBM接口相比,这种接口的带宽存在明显局限。
NPU可通过多种方式降低带宽需求:
NPU内置硬件与软件压缩机制,以此有效削减带宽消耗。
GenAI模型正逐步演进。例如,DeepSeek和Llama 4均采用了一种名为“专家混合”(MOE)的技术。这类模型的参数规模依然庞大,但MOE技术能让任意时刻加载的参数集更为精简,从而提升带宽效率。
降低GenAI模型参数的精度是减少带宽的常用策略。大多数NPU原本针对INT8数据和系数设计,但若参数能采用更低精度的格式(如INT4或FP4),数据便可实现压缩存储,带宽由此翻倍提升。更小的数据类型还能同时减少内存占用和数据加载延迟。
针对窄精度数据类型的新标准应运而生
2023年,OCP微缩放格式(MX)规范发布,其中引入了三种浮点格式和一种整数格式(MXFP8、NXFP6、MXFP4、MXINT8),MXFP8格式源自OCP 8位浮点规范(OFP8),详见图2。
在图2中,四种符合MX规范的数据类型均采用8位指数并在由32个数字组成的块中共享,既能减少内存占用,又能提升硬件性能与效率,进而降低开销和运营成本。MX数据类型的另一优势在于,在离线编译过程中,FP32或FP16的权重与激活值可“直接转换”(压缩/量化)为MX浮点格式。
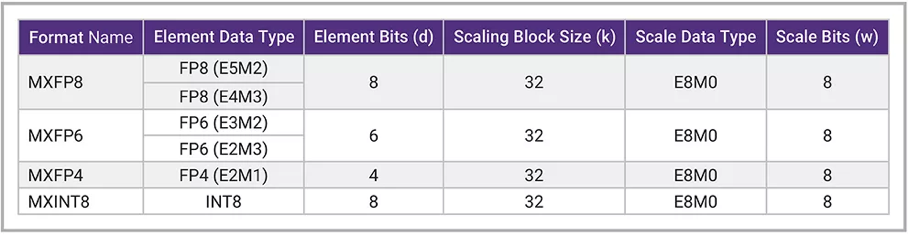
▲图2:OCP MX规范v1.0中的微缩放(MX)数据类型。
GenAI模型之所以需要更小的数据类型,源于NPU架构的需求变化。由于窄位宽数据格式有助于降低GenAI模型的计算与存储成本,NPU必须支持这些新的格式。
图3展示了新思科技面向具备AI能力的SoC所提供的处理器IP产品。NPX6 NPU IP提供高效、可扩展的AI推理引擎;VPX DSP IP是一款超长指令字(VLIW)/单指令多数据(SIMD)处理器系列,适用于广泛多样的信号处理应用,除了能对神经网络模型进行预处理和后处理外,还可处理自定义神经网络层。
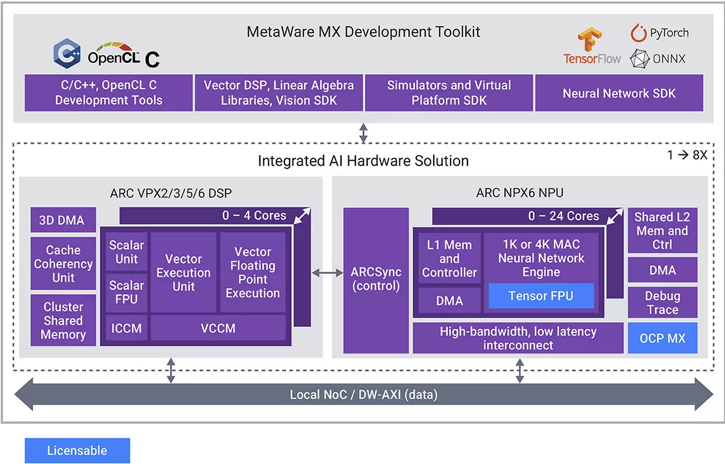
▲图3:NPX6 NPU IP和VPX DSP IP为神经网络处理、前瞻性适配及预处理/后处理提供集成解决方案。
新思科技的NPX IP和VPX IP系列现已新增AI数据压缩选项,与浮点单元(FPU)选项结合后,可为任何ARC NPX神经处理单元IP处理器或VPX数字信号处理器IP处理器增加对INT4、BF16、OCP-FP8及OCP-MX数据压缩的支持。新增的AI数据压缩选项完全符合OCP规范,包括《OCP 8位浮点规范(OFP8)》(1.0版,2023年6月20日批准)与《OCP微缩放格式(MX)规范》(1.0版,2023年9月)。
AI数据压缩选项可在DMA中快速执行数据格式转换:从系统内存移入内部存储器时对数据解压缩,从内部存储器移至系统内存时对数据压缩。以NPX6为例,MXFP6格式会转换为FP16格式以用于内部处理。内部计算采用FP16并不会限制整体性能,因为在NPX6 NPU IP上运行的LLM不受计算能力制约,瓶颈在于带宽。下方图4展示了增强型NPX6 NPU IP和VPX DSP IP所支持的数据类型,其中多项数据类型在DMA中得到支持。表格中还列出了每种数据类型所对应的内部数据路径。
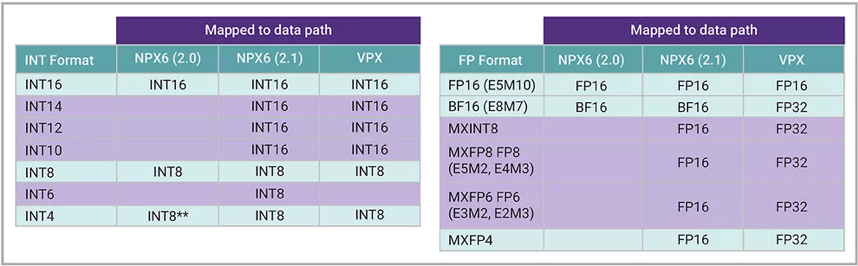
▲图4:增强型新思科技ARC NPX6 NPU IP和新思科技ARC VPX DSP IP系列所支持的数据类型。
由于VPX与NPX支持相同的数据类型,采用这些新格式在处理器之间传输参数或激活值时,操作简便易行。将这些数据类型集成到DMA中,有助于减少带宽占用和内存开销。在DMA中支持多种数据类型的另一优势在于,处理器IP能够直接与转换器连接。例如,10位模数转换器可连接至NPX或VPX,硬件会自动将其映射为内部数据类型,省去了软件转换的步骤。
结语
GenAI模型在不断演进的过程中,所遵循的发展轨迹很可能与CNN模型类似。在达到令人满意的精度与效率水平之前,模型的参数规模会持续激增;而后,研究重心将转向优化环节,使模型更适配边缘设备应用。目前,增强型新思科技ARC NPX6 NPU IP和新思科技ARC VPX DSP IP已正式推出,可供关注AI(包括GenAI)能力的SoC开发者选用。
-
神经网络
+关注
关注
42文章
4815浏览量
104575 -
AI
+关注
关注
88文章
35902浏览量
282958 -
新思科技
+关注
关注
5文章
883浏览量
51838
原文标题:4bit破解边缘AI部署难题!新思科技赋能“大模型”跑进“小设备”
文章出处:【微信号:Synopsys_CN,微信公众号:新思科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
边缘AI应用越来越普遍,AI模型在边缘端如何部署?

英特尔发布全新边缘计算平台,解决AI边缘落地难题

边缘AI实现的核心环节:硬件选择和模型部署
Deepseek海思SD3403边缘计算AI产品系统
EdgeBoard FZ5 边缘AI计算盒及计算卡
嵌入式边缘AI应用开发指南
新思科技发布业界首款全栈式AI驱动型EDA解决方案Synopsys.ai
如何通过Astraea一键化部署边缘AI服务?
新思科技宣布与SiMa.ai开展合作
边缘计算前景很美,安全难题如何破解?

中兴通讯AiCube:破解AI模型部署难题
边缘AI实现的核心环节:硬件选择和模型部署






 工商网监
工商网监
评论