 Arm KleidiAI与XNNPack集成实现AI性能提升
Arm KleidiAI与XNNPack集成实现AI性能提升

作者:Arm 工程部首席软件工程师 Gian Marco Iodice
自 Arm KleidiAI 首次集成到 XNNPack 已过去整整一年。KleidiAI 是一款高度优化的软件库,旨在加速 Arm CPU 上的人工智能 (AI) 推理。在过去一年中,从推出 INT4 矩阵乘法 (matmul) 优化以增强 Google Gemma 2 模型性能开始,到后续完成多项底层技术增强,Arm 在 XNNPack 上实现了显著的性能提升。
而更值得注意的是,开发者对此无需做任何改动。所有这些提升均实现了完全透明化,既不用修改代码,也无需额外的依赖项。只需像往常一样基于 XNNPack 构建并运行应用,就能自动享受到 Arm 通过 KleidiAI 引入的最新底层优化。
本文就将为你详细介绍最新的增强功能。
XNNPack 中的最新 KleidiAI 优化
面向 SDOT 和 i8mm 的 F32 x INT8 矩阵乘法
在先前 INT4 优化基础上,此次优化聚焦于通过动态量化加速 INT8 矩阵乘法,拓宽性能提升的覆盖范围,以支持各类 AI 模型。从卷积神经网络到前沿的生成式 AI 模型(例如 2025 年 5 月发布的 Stable Audio Open Small),这项优化带来了切实可见的性能提升。例如,该优化使扩散模块 (diffusion module) 的性能提升了 30% 以上。
与此前的 INT4 增强功能一样,INT8 优化借助 SDOT 指令和 i8mm 指令,在各类 CPU 上提升了动态量化性能。
面向 F32、F16 和 INT8 矩阵乘法的 SME2 优化
近期最令人振奋的进展之一,是 Armv9 架构上对可伸缩矩阵扩展 (SME2)的支持。这为 F32 (Float32)、F16 (Float16) 和 INT8 矩阵乘法带来了显著的性能跃升,为新的高性能应用铺平道路。因此,无论是对于当前还是未来的 AI 工作负载,都能从一开始实现无缝加速,且无需任何额外投入。
什么是 SME2?
SME2 是 Armv9-A CPU 架构中引入的一项全新 Arm 技术。SME2 基于可伸缩向量扩展 (SVE2) 技术构建,并通过可惠及 AI、计算机视觉、线性代数等多个领域的特性拓展了其应用范围。
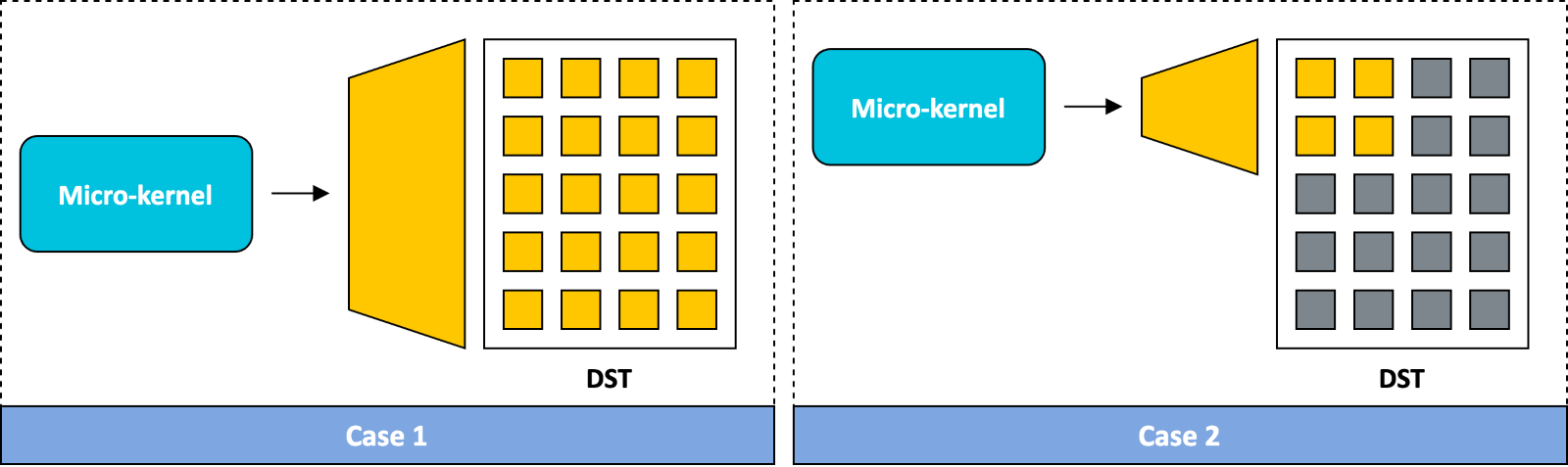
SME2 的一项突出特性是矩阵外积累加 (Matrix Outer Product Accumulate, MOPA) 指令,该指令能够实现高效的外积运算。如下图所示,外积与点积的区别在于,点积的运算结果是一个标量,而外积则由两个输入向量生成一个矩阵。
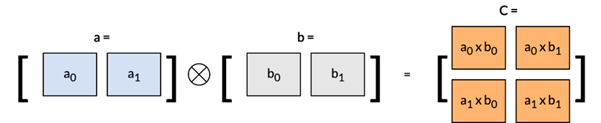
通过以下矩阵乘法示例来直观理解这一区别:
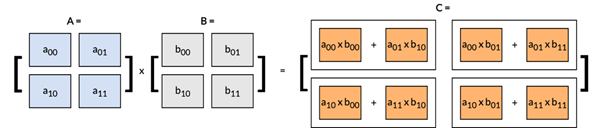
该矩阵乘法可分解为一系列外积运算,如下图所示:
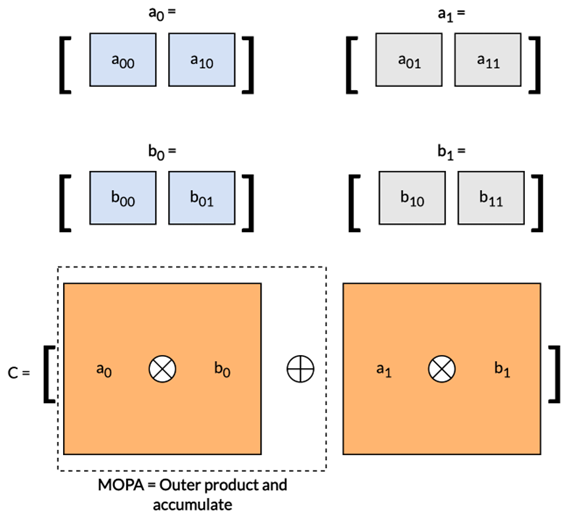
明确这一概念后,再来深入探讨构成优化的矩阵乘法例程核心的 SME2 汇编指令:
FMOPA za0.s, p0/m, p1/m, z1.s, z3.s
各操作数的含义如下:
FMOPA:浮点矩阵外积累加指令。
ZA0.s:用于存储和累积外积结果的 ZA 寄存器块。
p0/m 和 p1/m:用于定义有效计算通道(掩码操作)的 Predicate 寄存器。
z1.s 和 z3.s:参与外积运算的输入向量。
该指令支持多种数据类型,涵盖浮点格式(如 F32 和 F16)及整数类型(如 INT8)。得益于 SVE 技术的应用,它具备向量长度无关性,这意味着其能随硬件向量尺寸自动适配扩展,无需修改任何代码。
为展现 SME2 的性能潜力,不妨看看它在 Google Gemma 3 模型中通过 INT8 外积指令加速 INT4 矩阵乘法的效果。相比同一设备未启用 SME2 的情况,当 Gemma 3 模型部署在支持 SME2 的硬件上时,聊天机器人用例的 AI 响应速度最高可提升六倍。
此外,借助单 CPU 核心上的 SME2 加速,Gemma 3 能在一秒内开始对一篇四段文字的文本内容生成摘要,充分印证了该架构在响应速度与运行效率上的提升。
优化所带来的实际意义
通过这些更新,XNNPack 成为首个支持 SME2 的 AI 推理库,能够在 Arm CPU 上进一步实现前所未有的性能表现。
无论是专注于生成式 AI 还是基于 CNN 神经网络的开发者,都能在无需修改任何代码的情况下,在其应用上实现显著的性能提升。
展望 Arm KleidiAI 的未来
过去一年的实践证明,透明化加速不仅切实可行,更已具备实际应用价值。随着 KleidiAI 不断突破 XNNPack 上的性能表现,开发者可专注于打造出色的 AI 体验,而运行时性能也将持续提升。
-
ARM
+关注
关注
134文章
9382浏览量
379330 -
cpu
+关注
关注
68文章
11107浏览量
218085 -
AI
+关注
关注
88文章
35612浏览量
281871
原文标题:集成一周年,Arm KleidiAI 与 XNNPack 实现无缝且透明性 AI 性能
文章出处:【微信号:Arm社区,微信公众号:Arm社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录

Arm KleidiAI助力提升PyTorch上LLM推理性能
Arm+AWS实现AI定义汽车 基于Arm KleidiAI优化并由AWS提供支持
《电子发烧友电子设计周报》聚焦硬科技领域核心价值 第23期:2025.08.04--2025.08.08
Firefly支持AI引擎Tengine,性能提升,轻松搭建AI计算框架
英伟达提升绘图处理器AI性能 携手ARM加速深度学习推论计划

ARM发布全新架构CPU、GPU及AI内核 性能全面提升
重大性能更新:Wasm 后端将利用 SIMD指令和 XNNPACK多线程
ARM发布旗舰手机芯片:性能提升、AI性能增强、节能减耗
Arm KleidiAI软件库的功能解析
Arm成功将Arm KleidiAI软件库集成到腾讯自研的Angel 机器学习框架
利用Arm Kleidi技术实现PyTorch优化

Arm 与微软合作,为基于 Arm 架构的 PC 和移动设备应用提供超强 AI 体验

Arm率先适配腾讯混元开源模型,助力端侧AI创新开发





 工商网监
工商网监
评论