 介绍一种基于Transformer的大语言模型
介绍一种基于Transformer的大语言模型

译者按: 最近一段时间,ChatGPT 作为一个现象级应用迅速蹿红,也带动了对其背后的大语言模型 (LLM) 的讨论,这些讨论甚至出了 AI 技术圈,颇有些到了街谈巷议的程度。在 AI 技术圈,关于 LLM 和小模型的讨论在此之前已经持续了不短的时间,处于不同生态位置和产业环节的人都有表达自己的观点,其中不少是有冲突的。
大模型的研究者和大公司出于不同的动机站位 LLM,研究者出于对 LLM 的突现能力 (emergent ability) 的好奇和对 LLM 对 NLP 领域能力边界的拓展、而大公司可能更多出自于商业利益考量;而社区和中小公司犹犹豫豫在小模型的站位上徘徊,一方面是由于对 LLM 最终训练、推理和数据成本的望而却步,一方面也是对大模型可能加强大公司数据霸权的隐隐担忧。但讨论,尤其是公开透明的讨论,总是好事,让大家能够听到不同的声音,才有可能最终收敛至更合理的方案。
我们选译的这篇文章来自于 2021 年 10 月的 Hugging Face 博客,作者在那个时间点站位的是小模型,一年多以后的 2023 年作者的观点有没有改变我们不得而知,但开卷有益,了解作者当时考虑的那些点,把那些合理的点纳入自己的思考体系,并结合新的进展最终作出自己的判断可能才是最终目的。
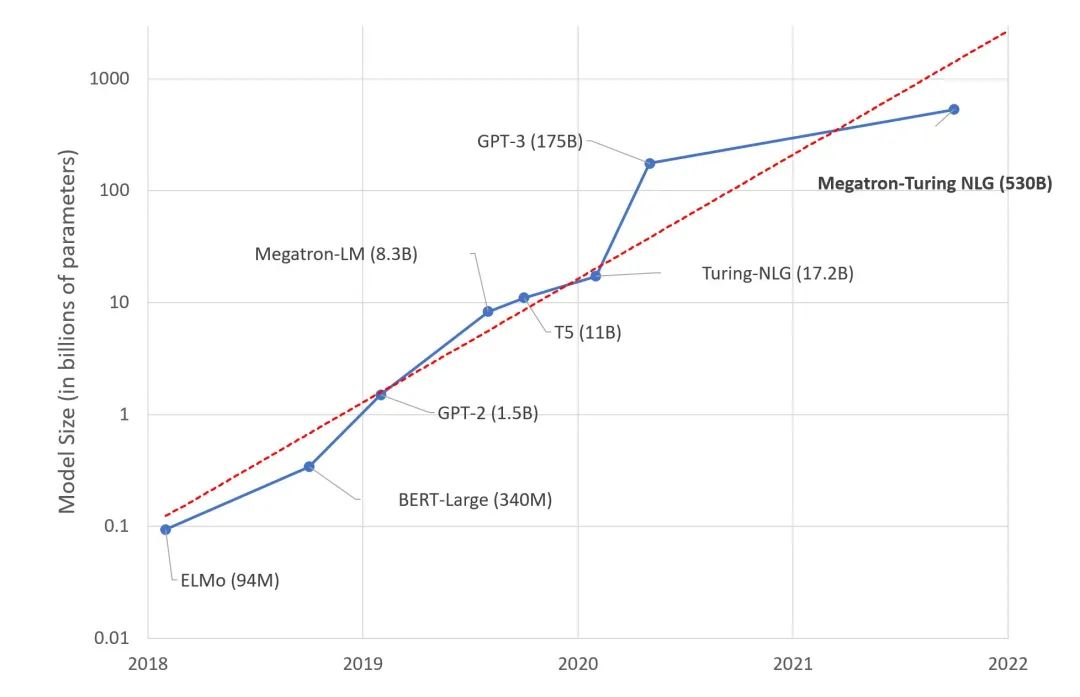
不久前,微软和 Nvidia 推出了 Megatron-Turing NLG 530B,一种基于 Transformer 的模型,被誉为是 “世界上最大且最强的生成语言模型”。
毫无疑问,此项成果对于机器学习工程来讲是一场令人印象深刻的能力展示,表明我们的工程能力已经能够训练如此巨大的模型。然而,我们应该为这种超级模型的趋势感到兴奋吗?我个人倾向于否定的回答。我将在通过本文阐述我的理由。
这是你的深度学习大脑
研究人员估计,人脑平均包含 860 亿个神经元和 100 万亿个突触。可以肯定的是,这里面并非所有的神经元和突触都用于语言。有趣的是,GPT-4 预计有大约 100 万亿个参数...... 虽然这个类比很粗略,但难道我们不应该怀疑一下构建与人脑大小相当的语言模型长期来讲是否是最佳方案?
当然,我们的大脑是一个了不起的器官,它经过数百万年的进化而产生,而深度学习模型仅有几十年的历史。不过,我们的直觉告诉我们: 有些东西无法计算 (这是个双关语,:)) 。
深度学习,深度销金窟?
如你所料,在庞大的文本数据集上训练一个 5300 亿参数的模型需要相当多的基础设施。事实上,Microsoft 和 Nvidia 使用了数百台 DGX A100 GPU 服务器,每台 19 万 9 千美元。如果再把网络设备、托管成本等因素考虑进去的话,任何想要重现该实验的组织或个人都必须花费近 1 亿美元。来根薯条压压惊?
说真的,有哪些组织有那种值得花费 1 亿美元来构建深度学习基础设施的业务?再少点,又有哪些组织有那种可以值得花费 1000 万美元基础设施的业务?很少。既然很少,那么请问,这些模型为谁而生呢?
GPU 集群的热
尽管训练大模型需要杰出的工程能力,但在 GPU 上训练深度学习模型本身却是一种蛮力技术。根据规格表,每台 DGX 服务器可消耗高达 6.5 千瓦的功率。同时,数据中心 (或服务器机柜) 至少需要同样多的冷却能力。除非你是史塔克家族的人 (Starks) ,需要在冬天让临冬城 (Winterfell) 保持温暖,否则你必须处理散热问题。
此外,随着公众对气候和社会责任问题意识的增强,还需要考虑碳足迹问题。根据马萨诸塞大学 2019 年的一项研究,“在 GPU 上训练一次 BERT 产生的碳足迹大致与一次跨美飞行相当”。
BERT-Large 有 3.4 亿个参数。我们可以通过此推断 Megatron-Turing 的碳足迹大致如何……认识我的人都知道,我并不是一个热血环保主义者。尽管如此,这些数字也不容忽视。
所以呢?
我对 Megatron-Turing NLG 530B 和接下来可能会出现的模型巨兽感到兴奋吗?不。我认为值得增加成本、复杂性以及碳足迹去换取 (相对较小的) 测试基准上的改进吗?不。我认为构建和推广这些庞大的模型能帮助组织理解和应用机器学习吗?不。
我想知道这一切有什么意义。为了科学而科学?好的老营销策略?技术至上?可能每个都有一点。如果是这些意义的话,我就不奉陪了。
相反,我更专注于实用且可操作的技术,大家都可以使用这些技术来构建高质量的机器学习解决方案。
使用预训练模型
在绝大多数情况下,你不需要自定义模型架构。也许你会 想要 自己定制一个模型架构 (这是另一回事),但请注意此处猛兽出没,仅限资深玩家!
一个好的起点是寻找已经针对你要解决的任务预训练过的模型 (例如,英文文本摘要) 。
然后,你应该快速尝试一些模型,用它们来预测你自己的数据。如果指标效果不错,那么打完收工!如果还需要更高一点的准确率,你应该考虑对模型进行微调 (稍后会详细介绍) 。
使用较小的模型
在评估模型时,你应该从那些精度满足要求的模型中选择尺寸最小的那个。它预测得更快,并且需要更少的硬件资源来进行训练和推理。节俭需要从一开始就做起。
这其实也不算什么新招。计算机视觉从业者会记得 SqueezeNet 2017 年问世时,与 AlexNet 相比,模型尺寸减少了 50 倍,而准确率却与 AlexNet 相当甚至更高。多聪明!
自然语言处理社区也在致力于使用迁移学习技术缩减模型尺寸,如使用知识蒸馏技术。DistilBERT 也许是其中最广为人知的工作。与原始 BERT 模型相比,它保留了 97% 的语言理解能力,同时尺寸缩小了 40%,速度提高了 60%。你可以 Hugging Face 尝试一下 DistilBERT。同样的方法也已经应用于其他模型,例如 Facebook 的 BART,你可以在 Hugging Face 尝试 DistilBART。
Big Science 项目的最新模型也令人印象深刻。下面这张来自于论文的图表明,他们的 T0 模型在许多任务上都优于 GPT-3,同时尺寸小 16 倍。你可以 Hugging Face 尝试 T0。
微调模型
如果你需要特化一个模型,你不应该从头开始训练它。相反,你应该对其进行微调,也就是说,仅针对你自己的数据训练几个回合。如果你缺少数据,也许这些数据集中的某个可以帮助你入门。
猜对了,这是进行迁移学习的另一种方式,它会帮助你节省一切!
收集、存储、清理和标注的数据更少,
更快的实验和迭代,
生产过程所需的资源更少。
换句话说: 节省时间,节省金钱,节省硬件资源,拯救世界!
如果你需要教程,Hugging Face 课程可以帮助你立即入门。
使用云基础设施
不管你是否喜欢它们,事实是云公司懂得如何构建高效的基础设施。可持续性研究表明,基于云的基础设施比其他替代方案更节能减排: 请参阅 AWS、Azure 和 Google。Earth.org 宣称虽然云基础设施并不完美,“[它] 比替代方案更节能,并促进了环境友好的服务及经济增长。"
在易用性、灵活性和随用随付方面,云肯定有很多优势。它也比你想象的更环保。如果你的 GPU 不够用,为什么不尝试在 AWS 的机器学习托管服务 Amazon SageMaker 上微调你的 Hugging Face 模型?我们为你准备了大量示例。
优化你的模型
从编译器到虚拟机,软件工程师长期以来一直在使用能够针对任何运行硬件自动优化代码的工具。
然而,机器学习社区仍在这个课题上苦苦挣扎,这是有充分理由的。优化模型的尺寸和速度是一项极其复杂的任务,其中涉及以下技术:
专用硬件加速: 如训练加速硬件 (Graphcore、Habana) 、推理加速硬件 (Google TPU,AWS Inferentia)。
剪枝: 删除对预测结果影响很小或没有影响的模型参数。
融合: 合并模型层 (例如,卷积和激活) 。
量化: 以较小的位深存储模型参数 (例如,使用 8 位而不是 32 位)
幸运的是,自动化工具开始出现,例如 Optimum 开源库和 Infinity,Infinity 是一个最低能以 1 毫秒的延迟提供 Transformers 推理能力的容器化解决方案。
结论
在过去的几年里,大语言模型的尺寸平均每年增长 10 倍。这开始看起来像另一个摩尔定律。
这条路似曾相识,我们应该知道这条路迟早会遇到收益递减、成本增加、复杂性等问题以及新的风险。指数的结局往往不是会很好。还记得 Meltdown and Spectre 吗?我们想知道人工智能的 Meltdown and Spectre 会是什么吗?
审核编辑:刘清
-
gpu
+关注
关注
28文章
4969浏览量
131776 -
机器学习
+关注
关注
66文章
8510浏览量
134917 -
nlp
+关注
关注
1文章
490浏览量
22663 -
ChatGPT
+关注
关注
29文章
1590浏览量
9187
原文标题:大语言模型: 新的摩尔定律?
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
大语言模型背后的Transformer,与CNN和RNN有何不同

【大语言模型:原理与工程实践】大语言模型的基础技术
大语言模型:原理与工程时间+小白初识大语言模型
【《大语言模型应用指南》阅读体验】+ 基础知识学习
如何更改ABBYY PDF Transformer+界面语言
ABBYY PDF Transformer+改善转换结果之识别语言
你了解在单GPU上就可以运行的Transformer模型吗
一种新的动态微观语言竞争社会仿真模型
超大Transformer语言模型的分布式训练框架

探究超大Transformer语言模型的分布式训练框架
一种基于乱序语言模型的预训练模型-PERT
基于Transformer的大型语言模型(LLM)的内部机制






 工商网监
工商网监
评论