 探究超大Transformer语言模型的分布式训练框架
探究超大Transformer语言模型的分布式训练框架

NVIDIA Megatron 是一个基于 PyTorch 的框架,用于训练基于 Transformer 架构的巨型语言模型。本系列文章将详细介绍Megatron的设计和实践,探索这一框架如何助力大模型的预训练计算。 上篇主要介绍了大模型训练的发展趋势、NVIDIA Megatron的模型并行设计,本篇将承接上篇的内容,解析Megatron 在NVIDIA DGX SuperPOD 上的实践。
优化的分布式集群架构:NVIDIA DGX SuperPOD
有了高效的分布式训练框架,自然也需要优化的分布式训练集群。
NVIDIA DGX SuperPOD 便是 NVIDIA 推出的一个分布式集群的参考架构,最新一代是基于NVIDIA DGX A100 和NVIDIA HDR 200Gb/s ConnectX-6 HCAs组建,旨在帮助AI 研究人员快速搭建一套强大、灵活、高效的系统,以满足工业界日益复杂、多变的模型对计算资源不同程度的需求。尤其对于超大语言模型预训练这一复杂场景,DGX SuperPOD 架构尤为重要。
DGX SuperPOD 采用模块化的设计,支持不同规模大小的设计。一个标准的SuperPOD 由140 台DGX A100和三层Infiniband 交换机通过胖树结构全互联起来。每台DGX A100 配有8个200Gb/s 的高速计算网,并配有2个200Gb/s的高速存储网,采用计算和存储网络分离的方案。
多个POD之间可以通过核心层交换机直连起来,可以支持多达560 台DGX A100的互联规模。
更多关于NVIDIA DGX SuperPOD 架构的详细设计,请参阅下列连接中的白皮书:https://images.nvidia.com/aem-dam/Solutions/Data-Center/gated-resources/nvidia-dgx-superpod-a100.pdf
NVIDIA Megatron 在 DGX SuperPOD 上的实践
基于DGX SuperPOD 的Megatron实践在不同大小的模型上,都表现出了很好的计算效率。
模型从1.7B 到1T ,训练规模从32 卡到3072 卡。
基于GPT-3 175B 模型的训练,采用如下的配置:
128 台 DGX A100,总共 1024张 A100
Tensor 并行度:8;Pipeline 并行度:16; 数据并行度:8
全局Batch size : 1536;Micro-batch size: 1
在如此大的训练规模下,GPU 仍可达到44% 左右的计算效率,在规模和效率上,都远远超过已有的公开结果。
详细内容请参考以下链接:
Megatron repro: https://github.com/nvidia/megatron-lm
GPT3-175B training scripts: https://github.com/NVIDIA/Megatron-LM/blob/main/examples/pretrain_gpt3_175B.sh
总结
1. 大模型是大势所趋。
2. 大规模分布式训练是训练大模型的必须。
3. NVIDIA Megatron 是开源的、软硬协同设计的训练框架,专为Transformer-based的超大语言模型设计。
4. NVIDIA DGX SuperPOD 是开放的集群参考设计架构,专为大规模分布式训练而准备。
5. Megatron 优化的Tensor模型并行:用于intra-transformer 层,可以高效地执行在HGX based的系统上。
6. Megatron优化的 Pipeline 模型并行:用于inter-transformer 层,可以有效地利用集群中多网卡的设计。
7. 数据并行的加持,可以扩展到更大规模、训练更快。
8. GPT-3 175B 的大模型,在1024 张 A100上可达到44%左右的计算效率。
9. NVIDIA Megatron 的设计和实践,已广泛用于学术界和工业界。
编辑:jq
-
数据
+关注
关注
8文章
7261浏览量
92229 -
NVIDIA
+关注
关注
14文章
5324浏览量
106638 -
交换机
+关注
关注
22文章
2759浏览量
102074 -
分布式
+关注
关注
1文章
1005浏览量
75507
原文标题:NVIDIA Megatron:超大Transformer语言模型的分布式训练框架 (二)
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
双电机分布式驱动汽车高速稳定性机电耦合控制
润和软件StackRUNS异构分布式推理框架的应用案例

润和软件发布StackRUNS异构分布式推理框架

AI原生架构升级:RAKsmart服务器在超大规模模型训练中的算力突破
浅谈工商企业用电管理的分布式储能设计
小白学大模型:训练大语言模型的深度指南

腾讯公布大语言模型训练新专利
分布式云化数据库有哪些类型
大模型训练框架(五)之Accelerate
HarmonyOS Next 应用元服务开发-分布式数据对象迁移数据权限与基础数据
分布式通信的原理和实现高效分布式通信背后的技术NVLink的演进

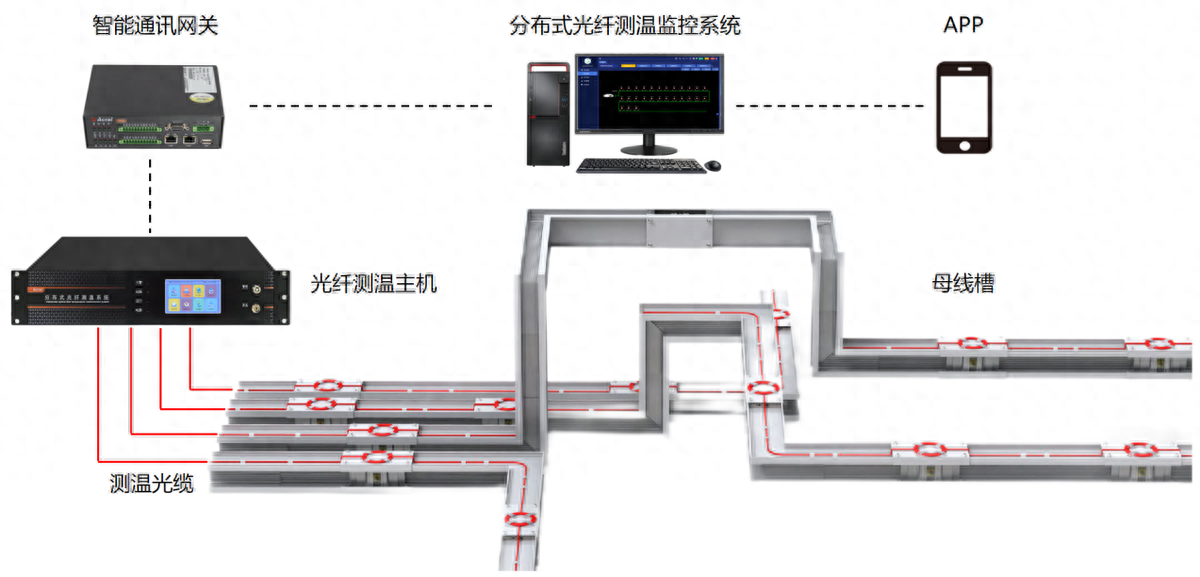
分布式光纤测温是什么?应用领域是?





 工商网监
工商网监
评论