 详解Python中的Pandas和Numpy库
详解Python中的Pandas和Numpy库

1、NumExpr
NumExpr 是一个对NumPy计算式进行的性能优化。NumExpr的使用及其简单,只需要将原来的numpy语句使用双引号框起来,并使用numexpr中的evaluate方法调用即可。
经验上看,数据有上万条+ 使用NumExpr才比较优效果,对于简单运算使用NumExpr可能会更慢。如下较复杂计算,速度差不多快了5倍。
importnumexprasne
importnumpyasnp
a=np.linspace(0,1000,1000)
print('#numpy十次幂计算')
%timeita**10
print('#numexpr十次幂计算')
%timeitne.evaluate('a**10')

2、Numba
Numba 使用行业标准的LLVM编译器库在运行时将 Python 函数转换为优化的机器代码。Python 中 Numba 编译的数值算法可以接近 C 或 FORTRAN 的速度。如果在你的数据处理过程涉及到了大量的数值计算,那么使用numba可以大大加快代码的运行效率(一般来说,Numba 引擎在处理大量数据点 如 1 百万+ 时表现出色)。numba使用起来也很简单,因为numba内置的函数本身是个装饰器,所以只要在自己定义好的函数前面加个@nb.方法就行,简单快捷!
#pipinstallnumba
importnumbaasnb
#用numba加速的求和函数
@nb.jit()
defnb_sum(a):
Sum=0
foriinrange(len(a)):
Sum+=a[i]
returnSum
#没用numba加速的求和函数
defpy_sum(a):
Sum=0
foriinrange(len(a)):
Sum+=a[i]
returnSum
importnumpyasnp
a=np.linspace(0,1000,1000)#创建一个长度为1000的数组
print('#python求和函数')
%timeitsum(a)
print('#没加速的for循环求和函数')
%timeitpy_sum(a)
print('#numba加速的for循环求和函数')
%timeitnb_sum(a)
print('#numpy求和函数')
%timeitnp.sum(a)

fromnumbaimportcuda
cuda.select_device(1)
@cuda.jit
defCudaSquare(x):
i,j=cuda.grid(2)
x[i][j]*=x[i][j]
#numba的矢量化加速
frommathimportsin
@nb.vectorize()
defnb_vec_sin(a):
returnsin(a)
3、CuPy
CuPy 是一个借助 CUDA GPU 库在英伟达 GPU 上实现 Numpy 数组的库。基于 Numpy 数组的实现,GPU 自身具有的多个 CUDA 核心可以促成更好的并行加速。
#pipinstallcupy
importnumpyasnp
importcupyascp
importtime
###numpy
s=time.time()
x_cpu=np.ones((1000,1000,1000))
e=time.time()
print(e-s)
###CuPy
s=time.time()
x_gpu=cp.ones((1000,1000,1000))
e=time.time()
print(e-s)
上述代码,Numpy 创建(1000, 1000, 1000)的数组用了 1.68 秒,而 CuPy 仅用了 0.16 秒,实现了 10.5 倍的加速。随着数据量的猛增,CuPy的性能提升会更为明显。4、pandas使用技巧
更多pandas性能提升技巧请戳官方文档:https://pandas.pydata.org/pandas-docs/stable/user_guide/enhancingperf.html4.1 按行迭代优化
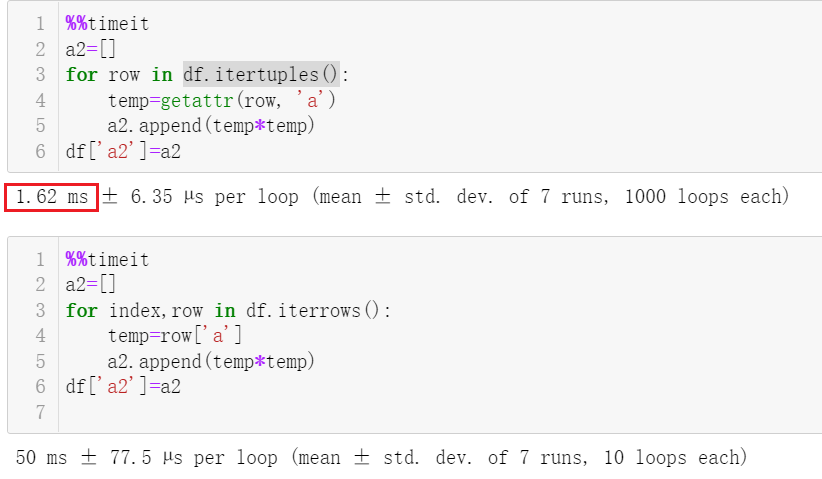
我们按行对dataframe进行迭代,一般我们会用iterrows这个函数。在新版的pandas中,提供了一个更快的itertuples函数,如下可以看到速度快了几十倍。
importpandasaspd
importnumpyasnp
importtime
df=pd.DataFrame({'a':np.random.randn(100000),
'b':np.random.randn(100000),
'N':np.random.randint(100,1000,(100000)),
'x':np.random.randint(1,10,(100000))})
%%timeit
a2=[]
forrowindf.itertuples():
temp=getattr(row,'a')
a2.append(temp*temp)
df['a2']=a2
%%timeit
a2=[]
forindex,rowindf.iterrows():
temp=row['a']
a2.append(temp*temp)
df['a2']=a2
4.2 apply、applymap优化
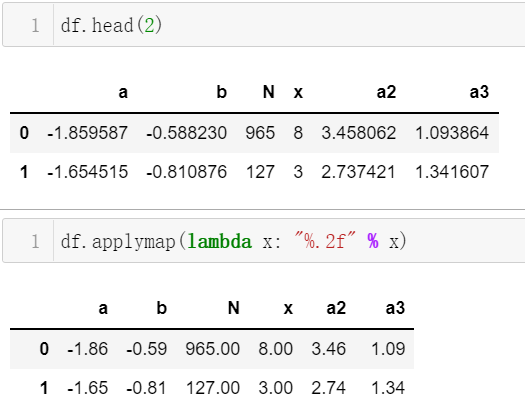
当对于每行执行类似的操作时,用循环逐行处理效率很低。这时可以用apply或applymap搭配函数操作,其中apply是可用于逐行计算,而applymap可以做更细粒度的逐个元素的计算。
#列a、列b逐行进行某一函数计算
df['a3']=df.apply(lambdarow:row['a']*row['b'],axis=1)
#逐个元素保留两位小数
df.applymap(lambdax:"%.2f"%x)
4.3 聚合函数agg优化
对于某列将进行聚合后,使用内置的函数比自定义函数效率更高,如下示例速度加速3倍
%timeitdf.groupby("x")['a'].agg(lambdax:x.sum())
%timeitdf.groupby("x")['a'].agg(sum)
%timeitdf.groupby("x")['a'].agg(np.sum)
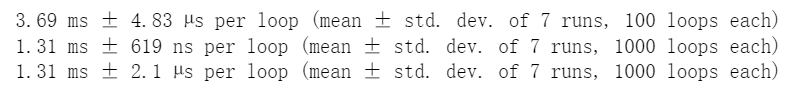
4.4 文件操作
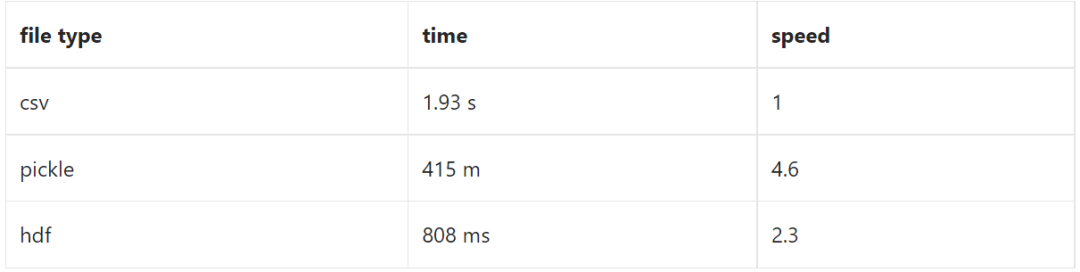
pandas读取文件,pkl格式的数据的读取速度最快,其次是hdf格式的数据,再者是读取csv格式数据,而xlsx的读取是比较慢的。但是存取csv有个好处是,这个数据格式通用性更好,占用内存硬盘资源也比较少。此外,对于大文件,csv还可以对文件分块、选定某几列、指定数据类型做读取。
4.5 pandas.eval
pandas.eval 是基于第一节提到的numexpr,pandas也是基于numpy开发的,numexpr同样可以被用来对pandas加速)。使用eval表达式的一个经验是数据超过 10,000 行的情况下使用会有明显优化效果。
importpandasaspd
nrows,ncols=20000,100
df1,df2,df3,df4=[pd.DataFrame(np.random.randn(nrows,ncols))for_inrange(4)]
print('pd')
%timeitdf1+df2+df3+df4
print('pd.eval')
%timeitpd.eval("df1+df2+df3+df4")

5、Cython优化
Cython是一个基于C语言的Python 编译器,在一些计算量大的程序中,可以Cython来实现相当大的加速。考虑大部分人可能都不太了解复杂的cython语句,下面介绍下Cython的简易版使用技巧。
通过在Ipython加入 Cython 魔术函数%load_ext Cython,如下示例就可以加速了一倍。进一步再借助更高级的cython语句,还是可以比Python快个几十上百倍。
%%cython
deff_plain(x):
returnx*(x-1)
defintegrate_f_plain(a,b,N):
s=0
dx=(b-a)/N
foriinrange(N):
s+=f_plain(a+i*dx)
returns*dx

6、swifter
swifter是pandas的插件,可以直接在pandas的数据上操作。Swifter的优化方法检验计算是否可以矢量化或者并行化处理,以提高性能。如常见的apply就可以通过swifter并行处理。
importpandasaspd
importswifter
df.swifter.apply(lambdax:x.sum()-x.min())
7、Modin
Modin后端使用dask或者ray(dask是类似pandas库的功能,可以实现并行读取运行),是个支持分布式运行的类pandas库,简单通过更改一行代码import modin.pandas as pd就可以优化 pandas,常用的内置的read_csv、concat、apply都有不错的加速。注:并行处理的开销会使小数据集的处理速度变慢。

!pipinstallmodin
importpandas
importmodin.pandasaspd
importtime
##pandas
pandas_df=pandas.DataFrame({'a':np.random.randn(10000000),
'b':np.random.randn(10000000),
'N':np.random.randint(100,10000,(10000000)),
'x':np.random.randint(1,1000,(10000000))})
start=time.time()
big_pandas_df=pandas.concat([pandas_dffor_inrange(25)])
end=time.time()
pandas_duration=end-start
print("Timetoconcatwithpandas:{}seconds".format(round(pandas_duration,3)))
####modin.pandas
modin_df=pd.DataFrame({'a':np.random.randn(10000000),
'b':np.random.randn(10000000),
'N':np.random.randint(100,10000,(10000000)),
'x':np.random.randint(1,1000,(10000000))})
start=time.time()
big_modin_df=pd.concat([modin_dffor_inrange(25)])
end=time.time()
modin_duration=end-start
print("TimetoconcatwithModin:{}seconds".format(round(modin_duration,3)))
print("Modinis{}xfasterthanpandasat`concat`!".format(round(pandas_duration/modin_duration,2)))

原文标题:Pandas、Numpy 性能优化秘籍
文章出处:【微信公众号:数据分析与开发】欢迎添加关注!文章转载请注明出处。
-
数据处理
+关注
关注
0文章
628浏览量
29360 -
python
+关注
关注
56文章
4831浏览量
87486 -
性能优化
+关注
关注
0文章
18浏览量
7540
原文标题:Pandas、Numpy 性能优化秘籍
文章出处:【微信号:DBDevs,微信公众号:数据分析与开发】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
linux虚拟环境中调用Linux 版matlab编译的python库时出错

python入门圣经-高清电子书(建议下载)
Python在嵌入式系统中的应用场景
深度学习入门:简单神经网络的构建与实现
使用Python实现xgboost教程
适用于MySQL和MariaDB的Python连接器:可靠的MySQL数据连接器和数据库
适用于Oracle的Python连接器:可访问托管以及非托管的数据库
数据库事件触发的设置和应用
使用Python进行串口通信的案例
RAPIDS cuDF将pandas提速近150倍

如何使用Python构建LSTM神经网络模型
Python库解析:通过库实现代理请求与数据抓取
Python中多线程和多进程的区别





 工商网监
工商网监
评论