 开源OCR 过程介绍
开源OCR 过程介绍

不久前,百度技术团队在不久前,百度技术团队在 GitHub 上正式开源了一款 OCR 神器,在发布后不久便多次冲上 GitHub Trending 榜单,引起了技术圈内开发者的热议,今天就跟大家好好介绍下这个项目。
众所周知,OCR(Optical Character Recognition,光学字符识别) 技术已被广泛应用到我们生活中的方方面面,从印刷稿的文字识别、身份证电子化信息录入,到传统邮件自动分拣、汽车牌照识别等领域,都上正式开源了一款 OCR 神器,在发布后不久便多次冲上 GitHub Trending 榜单,引起了技术圈内开发者的热议,今天就跟大家好好介绍下这个项目。
众所周知,OCR(Optical Character Recognition,光学字符识别) 技术已被广泛应用到我们生活中的方方面面,从印刷稿的文字识别、身份证电子化信息录入,到传统邮件自动分拣、汽车牌照识别等领域,都少不了 OCR 的身影。
在平时工作的时候,我也经常会使用一些 OCR 软件来扫描图片并提取文字,而要替代人工完成一系列的文本分析,图像识别操作,则必将使用到 AI 技术。
百度在 GitHub 上开源的 PaddleOCR 模型,大小仅有 8.6M,是目前圈内为数不多,能支持中英文图像、横竖排排版识别的 AI 深度学习模型之一。
先看下 PaddleOCR 自今年年中开源以来,短短几个月在 GitHub 上的表现:
7 月,8.6M 超轻量模型发布,GitHub Trending 全球日榜榜单第一!
8 月,开源 CVPR2020 顶会 SOTA 算法,再上 GitHub 趋势榜单!
9 月,GitHub Star 数量已超过 4.6K, 近期又带来哪些重磅更新?
果然,看 9 月最新更新,PaddleOCR 再次诚意满满为大家带来真干货,直接看官方介绍:
01. 官方介绍
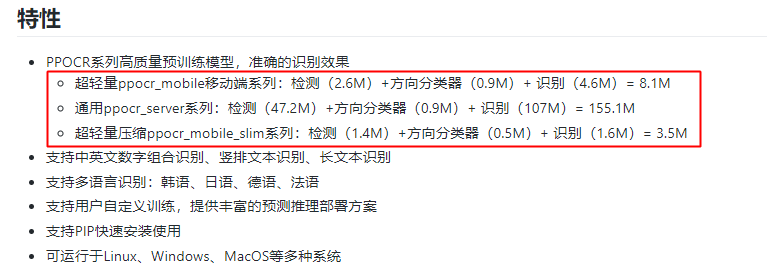
数量上,这次 PaddleOCR 一口气发布了三个系列模型,满足移动端、服务器端各种场景需求。而且,多语言也妥妥安排上了,全部训练代码和模型毫无保留开源。其中 3.5M 超轻量文字识别模型,堪称目前业界开源的最轻量 OCR 模型了。质量上,如此轻量的模型,效果有保障吗?不看广告,直接看疗效。 先看几个常见的通用场景识别效果:

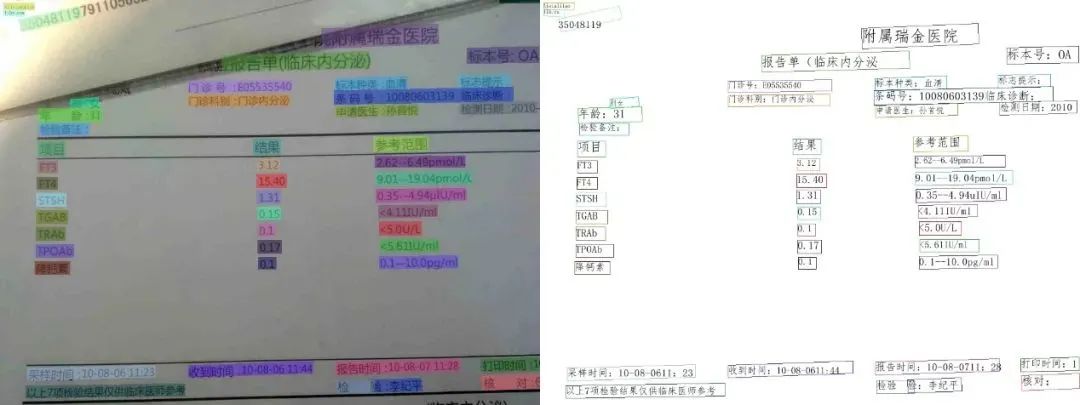

3.5M 的模型能达到这个识别精度,绝对是良心之作了!传送门 Github:https://github.com/PaddlePaddle/PaddleOCR论文下载链接:https://arxiv.org/abs/2009.09941
02. 快速体验
PaddleOCR 的 3.5M 超轻量 OCR 模型1).PC 端快速尝试:(打开网页,选一张图片,即可实时看到结果) https://www.paddlepaddle.org.cn/hub/scene/ocr
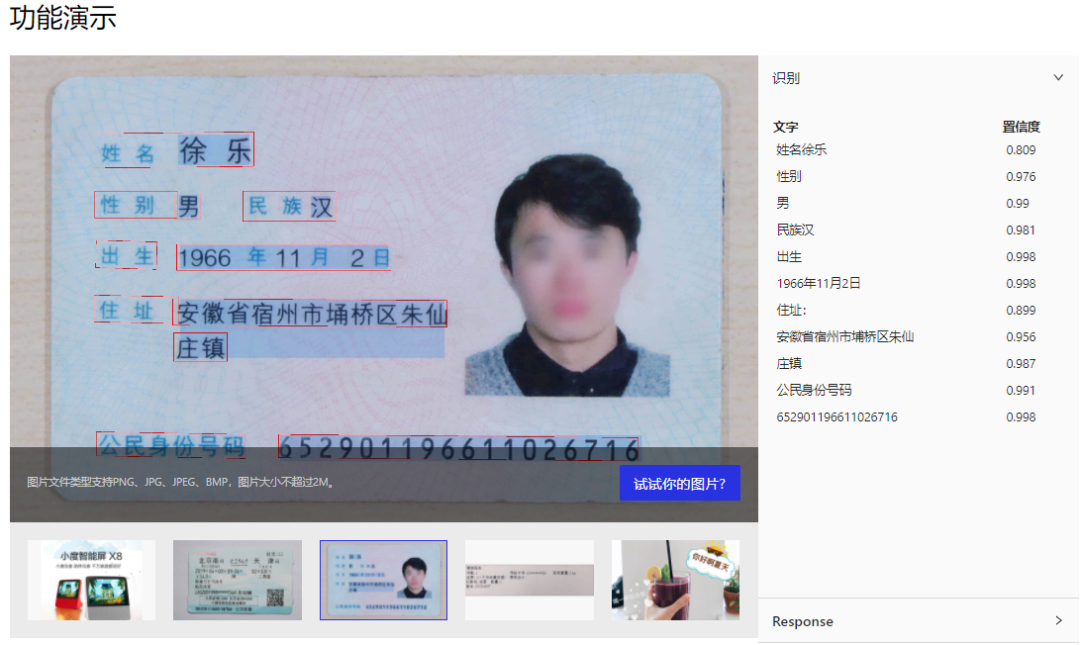
2). 手机端 App 安装体验PaddleOCR 在百度大脑 EasyEdge 上开放了文字识别 APP demo。 示例效果如下(可以在 github 首页找到下载二维码)

多个开源 repo 测试对比
简单对比一下目前主流 OCR 方向开源 repo 的核心能力:
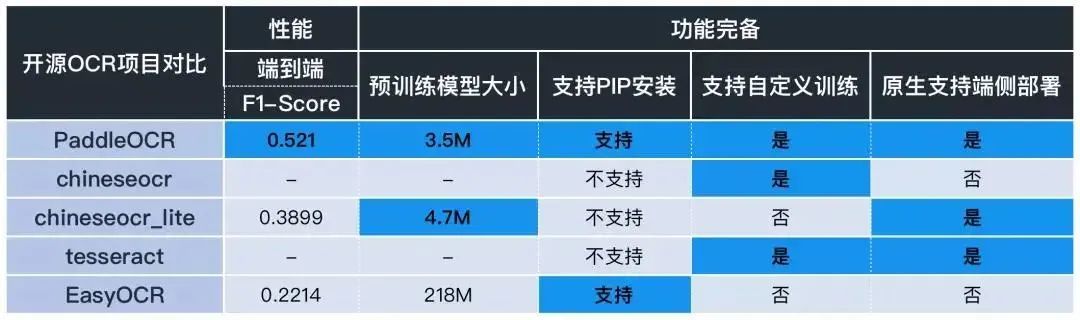
3). 从性能指标来看:
针对 OCR 实际应用场景,包括合同,车牌,铭牌,火车票,化验单,表格,证书,街景文字,名片,数码显示屏等,收集的 300 张图像,每张图平均有 17 个文本框,PaddleOCR 的 F1-Score 超过 0.5,这个性能已经很不错了。
4). 从功能完备来看:
预训练模型大小:easyOCR 目前暂无超轻量模型,chineseocr_lite 最新的模型是 4.7M 左右,而 PaddleOCR 提供的 3.5M 无疑是目前业界已知最轻量的。
PIP 安装:目前仅 PaddleOCR 和 easyOCR 支持。
自定义训练:实际业务场景中,预训练模型往往不能满足需求,对于自定义训练和模型 Finetuning,目前只有 PaddleOCR 支持。
部署方面:easyOCR 模型较大不适合端侧部署,Chineseocr_lite 和 PaddleOCR 都具备端侧部署能力。
开发者可以根据自己的实际需求,选择适合自己的开源方案。 对于 PaddleOCR3.5MB 的超轻量模型,是如何做到的,repo 中也给出了解释。

3.5M 超轻量模型应用了一套超轻量 OCR 系统 PP-OCR,主要由 DB 文本检测、检测框矫正和 CRNN 文本识别三部分组成。该系统从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化 8 个方面,采用 19 个有效策略,对各个模块的模型进行效果调优和瘦身。 其中,飞桨模型压缩库 PaddleSlim 为 PaddleOCR 超轻量化模型的实现提供了核心的技术支撑。从超轻量模型 8.1M 的压缩到 3.5M,模型大小降低了 56.79%,其中检测模型速度提升 21%,而且整体模型精度还有提升。

除了 3.5M 超轻量 OCR 模型,PaddleOCR 提供了多语言预训练模型(英、德、法、韩、日),支持自定义训练和丰富的部署方式。
责任编辑:PSY
原文标题:Github标星4.6K+!这个OCR开源项目,火了!
文章出处:【微信公众号:人工智能与大数据技术】欢迎添加关注!文章转载请注明出处。
-
开源
+关注
关注
3文章
3793浏览量
44167 -
OCR
+关注
关注
0文章
163浏览量
16860 -
GitHub
+关注
关注
3文章
483浏览量
17925
原文标题:Github标星4.6K+!这个OCR开源项目,火了!
文章出处:【微信号:TheBigData1024,微信公众号:人工智能与大数据技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
如何利用OCR技术实现高效集装箱箱号识别?

端侧OCR文字识别实现 -- Core Vision Kit ##HarmonyOS SDK AI##
明治案例 | 150个/分钟!电阻【OCR识别】+【尺寸测量】一步到位

OCR识别训练完成后给的是空压缩包,为什么?

大模型预标注和自动化标注在OCR标注场景的应用
如何在C#中部署飞桨PP-OCRv4模型

讯维KVM坐席管理协作系统:OCR功能及优势介绍
如何在播放视频过程中插入音频
使用ADS1211U的过程中,采样值输出一直为0XFFFFFF,为什么?
ElfBoard开源项目|车牌识别项目技术文档

开源ISP(Infinite-ISP)介绍

光学识别的过程包含哪些
?介绍一款Java开发的开源MES系统





 工商网监
工商网监
评论