 彪悍的Graphcore第二代IPU!加速落地超大规模数据中心、金融、医疗健康等领域
彪悍的Graphcore第二代IPU!加速落地超大规模数据中心、金融、医疗健康等领域

电子发烧友网报道(文/黄晶晶)一家来自于英国的AI初创公司Graphcore,成立一年多时间里,融资超过4.5亿美金,金融投资者包括红杉资本、欧洲Atomico、以色列Pitango等,战略投资者包括宝马、Bosch、戴尔、微软、三星等,受到资本的热烈追捧。
最近,Graphcore发布第二代IPU芯片以及基于第二代IPU处理器的一系列的产品,性能对标市面上的主流产品。据了解,Graphcore IPU采用大规模并行同构众核架构,其IPU Core是一个SMT多线程处理器,可以同时跑6个线程,类似多线程CPU,它与GPU的SIMD/SMIT架构不同。Graphcore IPU大量采用片上存储SRAM,没有外部DRAM。另外还采用了IPU-Fabric进行片间互联。Graphcore第二代IPU芯片在SRAM存储容量、计算吞吐量以及通信方面又有了大幅提升。
Graphcore第二代IPU三大颠覆性技术
Graphcore第二代IPU芯片Colossus Mk2 GC200采用台积电7nm工艺。在计算、数据与通信方面实现了技术突破。无论与公司第一代IPU还是目前市面上主流的GPU相比,其性能表现突出。Graphcore高级副总裁、中国区总经理卢涛进行了详细解析。
计算
Colossus Mk2 GC200处理器是目前世界上最复杂的单一处理器,基于台积电7纳米的技术,集成将近600亿个晶体管,拥有250TFlops AI-Float的算力和900MB的处理器内存储。处理器内核从上一代的1217提升到1472个独立的处理器内核,这样一个处理器有将近9000个单独的并行线程。相对于第一代产品,其系统级的性能提升了8倍以上。
同时In-Processor-Memory从上一代的300MB提升到900MB。每个IPU的Memory带宽是47.5TB/s。还包含了IPU-Exchange以及PCI Gen4跟主机交互的一个接口;另外有IPU-Links 320GB/s的芯片到芯片的互联。
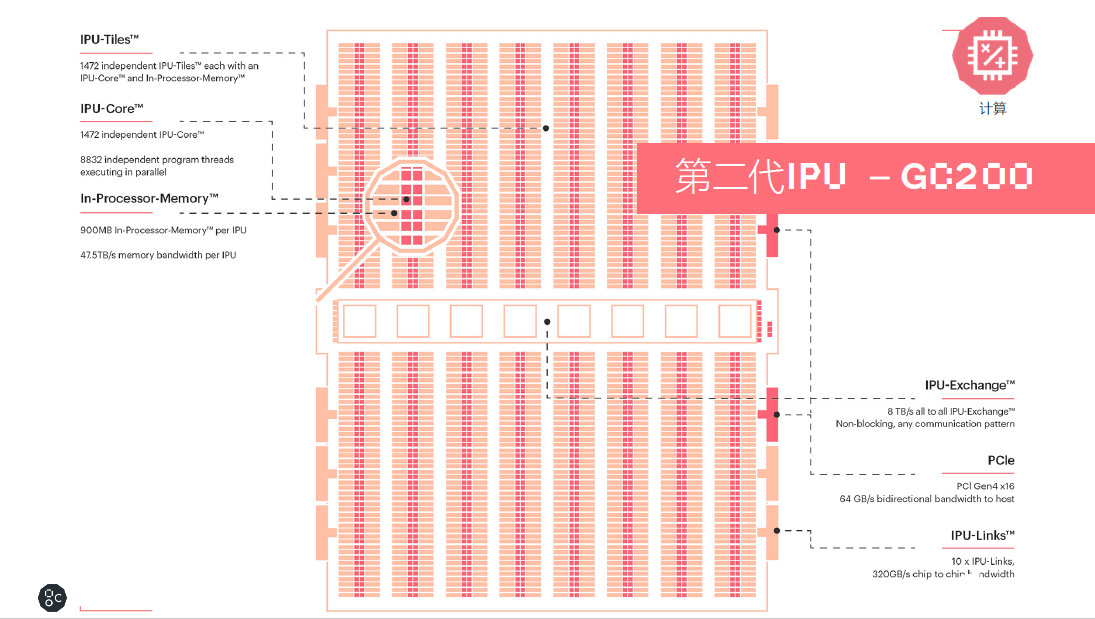
数据
IPU Exchange Memory是一个交换式存储的概念。如果跟英伟达当前使用HBM技术的产品比较,Graphcore在M2000每个IPU-Machine里面通过IPU-Exchange-Memory技术,提供了将近超过100倍的带宽以及大约10倍的容量,这对于很多复杂的AI模型算法是非常有帮助的。
通信
此次,Graphcore专门为AI横向扩展设计了一个IPU-Fabric的结构。IPU-Fabric可以做到2.8Tbps超低延时,同时最多可以支持64000个IPU之间的横向扩展。同时IPU-Fabric支持AI运算的集合通信或者all-reduce的操作,这也是Fabric的技术特性。
目前Graphcore有三种产品形态:一是IPU-Machine。二是IPU服务器,目前Graphcore已经在全球范围内完成了浪潮和戴尔IPU服务器的产品适配。三是大规模横向扩展的IPU-POD系统级产品。
IPU-MachineM2000是一个1U结构的即插即用的计算刀片,集成4个IPU Mk2GC200处理器,总共有1PFlops16.16的算力,和近6000个处理器的核心,以及超过35000个并行的线程,In-Processor Memory达到了3.6GB,Exchange Memory有450GB,以及2.8TbpsIPU-Fabric超低延时通信。非常易于部署,IPU-M2000可以满足当前最苛刻的一些机器智能的工作负载。当前建议零售价是32,450美金。
IPU-M2000拥有多种配置形态,M2000是我们在构建超大规模的、弹性的AI计算集群中间的一个基本单元,可以从1个到4个、8个,到64个,最多可以到64000个,自由组合计算规模。
用于超算规模的IPU-POD,IPU-POD64是IPU-POD的一个基本组件,IPU-POD64总共支持了16个IPU-M2000,可以根据不同的工作负载进行不同的配置。另外,目前支持的2D-Torus拓扑,最大化IPU-Link的带宽,全缩减(all-reduce)的效率比网状拓扑的要快两倍,这样一个架构可以扩展到64000个GC200的IPU。
由于把AI的计算跟逻辑的控制进行了解耦,因此非常易于部署,网络延时非常低,能够支持大型的算法模型,以及安全的多用户使用,
按64000个IPU集群计算,总共能提供16个EFlops FP16的算力,卢涛表示,日本前一阵发布的超算实现0.5 EFlops算力。而我们基于64000个IPU总共可以组建16个EFlops算力,这个是非常惊人的算力。
性能PK
IPU Mk2与Mk1进行对比,计算达到了两倍以上的吞吐量峰值能力;数据方面,六倍以上的处理器内的有效存储,超过了446GB的 IPU-Machine流存储;通信方面,加入了基于大规模横向扩展的IPU-Fabric的技术。
处理器内存储从300MB到900MB,看起来是三倍的提升,但是片内存储分为两部分,程序占用的存储空间以及供模型的激活、权重的存储空间。因为对于程序代码空间的占用情况在Mk1和Mk2是同样的,这样供算法模型可用的权重和激活容量有6倍以上的有效存储。

Mk2与Mk1系统级的对比中,配备有IPU-Link的8个C2 PCIe的IPU服务器和Mk2配备有IPU-Fabric的8个IPU-M2000比较,在三个比较典型的应用场景,在BERT-Large训练,MK2有9.3倍性能的提升。BERT三层推理,实现8. 5倍的性能提升。EfficientNet-B3这类计算机视觉应用模型,有7.4 倍的性能提升。
8个M2000与基于英伟达DGX-A100的整机(8个A100)对比中,后者FP32的计算能力是156TFlops,而8个M2000做到了2PFlops的算力,大约12倍的FP32性能的提升。对于AI计算,在GPU的平台上是2.5PFlops,在M2000的平台上是8PFlops,大约有三倍的提升。针对AI存储部分,相对后者320GB,前面有3.6TB的存储,将近10倍的提升。另外,从系统架构来说,花199K美金买到最新的GPU的算力和存储空间,对于Graphcore的平台,可能会花259k美金就能买到12倍的运算能力和10倍的存储空间。
软件与平台生态
对于AI的落地应用,软件生态可能比硬件更重要。Graphcore在提供高性能IPU芯片的同时,也在加速软件和平台生态的建设。
Graphcore 中国区技术应用总负责人罗旭介绍了Poplar软件的最新版本特性。Poplar包括PopART和PopLibs,PopLibs相当于SDK,PopART相当于run time,通过PopART和PopLibs,连接到Poplar的compute graph,再通过graph compiler,相当于在整个处理器软件跟硬件结合最紧密的地方转成一个计算图,然后把这个计算图加载到对应的硬件,也就是IPU-Machine。
Poplar支持的算法框架包括PyTorch、TensorFlow、ONNX,mxnet,以及前段时间百度发布的PaddlePaddle。同一套软件可以实现推理和训练。

最新发布的SDK 1.2主要特性在于,与比较先进的机器学习框架做更好的集成;进一步开放低级别的API,上层的算法提供一个低层次的API接口,针对网络的性能做一些特定的调优;增加框架支持,包括对PyTorch和Keras的支持。另外卷积库和稀疏库。PopART方面,可以做到多机的数据并行训练。
罗旭还谈到,我们把Exchange Memory也做了一些开放,包括API以及它的管理功能的开放。应用开发者可以基于Exchange Memory对模型的性能做极大程度的调优。
针对数据中心目前主流的操作系统ubuntu、RedHat、CentOS,现在Poplar SDK、drivers、工具链等也是完全支持的。
7月6号,PopLibs在GitHub上开源。用户可以直接在GitHub上去搜索Graphcore下载对应链接。
Graphcore 在中国的首款IPU 开发者云部署在金山云之上,这里面使用了三种IPU产品,IPU-POD64,浪潮的IPU服务器NF5568M5,以及戴尔的IPU服务器DSS8440,目前这个是面向商业用户进行评测以及面向高校研究机构,甚至个人开发者能够提供免费的试用。
对于商业用户来说,通常为三周或者按需适度延长,可以通用IPU极大优化现有模型,产品较竞争对手更早实现产品化和市场化。对大学、研究机构和个人研究者,可以提供6个月的免费访问,直至完成研究项目并发表结果。
IPU与GPU不是竞争关系
卢涛认为,IPU是面向未来的另一大计算平台,它与CPU、GPU不是竞争的关系,有交叉有不同。当前AI主流计算平台仍是CPU和GPU,甚至一些算法也是基于GPU发展而来。Graphcore的愿景是画第三个圆,我们认为CPU与GPU并没有从根本意义上解决AI的问题。AI是一个面向计算图的计算任务,跟CPU的标量计算以及GPU的矢量计算都不同。
从此,CPU、GPU、IPU有重叠相交的部分,必然会在某些领域进行竞争。例如,目前在NLP、CV这两个领域的竞争会有一段胶着时期。但是未来会有更多IPU独挡一面的应用,有待我们进行挖掘。
本文由电子发烧友网原创,未经授权禁止转载。如需转载,请添加微信号elecfans999。
-
数据中心
+关注
关注
16文章
5287浏览量
73722 -
IPU
+关注
关注
0文章
35浏览量
15829 -
AI芯片
+关注
关注
17文章
1994浏览量
36050
发布评论请先 登录
伟创力高效电源模块在超大规模数据中心的应用
AMD第二代Versal AI Edge和Versal Prime系列加速量产 为嵌入式系统实现单芯片智能
纳微半导体推出12kW超大规模AI数据中心电源
恩智浦推出第二代OrangeBox车规级开发平台
BDx成功融资助力香港超大规模数据中心扩建
第二代AMD Versal Premium系列SoC满足各种CXL应用需求
适用于数据中心和AI时代的800G网络
伟创力如何应对超大规模数据中心建设挑战
第二代AMD Versal Premium系列器件的主要应用
第二代AMD Versal Premium系列产品亮点
借助第二代 AMD VERSAL 实现先进医疗成像
拓展AI数据中心内存,第二代AMD Versal Premium系列自适应SoC,首发支持CXL 3.1、 PCIe Gen6






 工商网监
工商网监
评论