 Achronix联合BittWare推出了VectorPath S7t-VG6 PCIe加速卡
Achronix联合BittWare推出了VectorPath S7t-VG6 PCIe加速卡

据Semico Research预测,数据中心加速器市场预计将从2018年的28.4亿美元增长到2023年的211.9亿美元,这其中包括CPU、GPU、FPGA和ASIC,而FPGA预计将是年复合增长率最高的细分市场,因为越来越多的企业级工作负载加速应用采用FPGA方式。例如在人工智能应用中,虽然采用GPU训练样本更加有效(相对来说成本也比较高),但是人工智能应用的下半场将进入推理阶段,这一阶段的增长会超过训练阶段,而这一阶段恰好是FPGA非常擅长的,GPU也只能望其项背了。
正是看好这一市场的未来前景,Achronix联合BittWare(Molex子公司)推出了VectorPath S7t-VG6 PCIe加速卡。
接口和尺寸都是标准的,拿来即可使用
VectorPathS7t-VG6 PCIe加速卡立足于FPGA芯片
据Achronix公司市场营销副总裁Steve Mensor介绍,作为唯一能够提供高端独立FPGA芯片和嵌入式FPGA(eFPGA)硅知识产权(IP)技术的FPGA供应商,非常看好其在加速器方面的应用,因为在这一应用中,FPGA与传统CPU相比性能高出了10~100倍(因具体应用而异)。
这些应用都需要硬件加速器
FPGA方式加速在不同应用领域有所差异
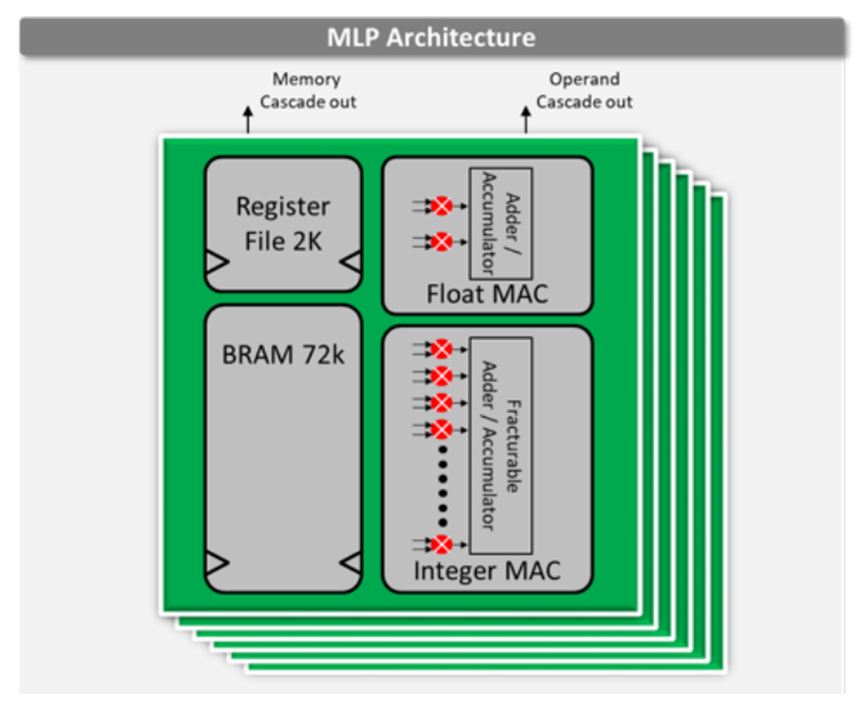
VectorPath S7t-VG6 PCIe加速卡上核心的FPGA芯片采用了Achronix公司的Speedster7t,其基于高度优化的全新架构,性能如同ASIC,但是同时拥有FPGA的灵活性和增强功能,远远优于传统FPGA解决方案。Speedster7t采用全新的二维片上网络(2D NoC),这种结构如同在FPGA可编程逻辑结构上运行的高速公路网络一样,支持接口和可编程逻辑结构中的自定义加速功能之间的高带宽通信,这样每个MLP都是一个高度可配置的计算密集型单元模块,具有多达32个乘法器/累加器(MAC),可以支持4位到24位的整数格式和各种浮点模式。Steve Mensor表示,正是有了2D NoC,使FPGA就成为了像软件一样友好的硬件,FPGA IP生态公司在完成设计之后,可以便捷地将其IP连接到AXI接口,而所有的高速接口和存储器交给Speedster7t就可以了。
2D NoC结构
更加关键的是Speedster7t器件具有满足未来人工智能和机器学习要求的超高带宽接口,包括400G以太网端口、用于数据传输的PCI Express Gen5端口以及支持低成本、高带宽存储的GDDR6控制器。
在谈到公司战略时,Steve Mensor表示,目前很多友商都在采用软件思维发展FPGA芯片,但是开发者需要考虑他们的哪些应用要放在哪里处理,而且还要考虑芯片内部的数据传输,而Achronix则走另一条路线,努力提高算力,在底层依然采用硬件思维,这样熟悉FPGA开发的工程师会很容易上手,2D NoC消除了传统FPGA使用可编程路由和逻辑查找表资源在整个FPGA中移动数据流中出现的拥塞和性能瓶颈。Steve Mensor坚信,这条传统的发展路线会走得更加顺畅。
感觉内部清爽多了吧!
更多关于Speedster7t的细节,请点击“别人聊FPGA,咱们来说说FPGA+!”
选用VectorPathS7t-VG6 PCIe加速卡,享受两家公司的服务
VectorPath S7t-VG6 PCIe加速卡是Achronix和BittWare两家公司深度合作的产品,这款加速卡包括一整套Achronix的ACE开发工具以及BittWare的基板管理控制器和开发工具包,其中包括API、PCIe驱动程序、诊断自测和应用示例设计,为工程师提供开箱即用的体验。VectorPath S7t-VG6 PCIe加速卡可以提供以下硬件功能:400GbEQSFP-DD和100GbE QSFP56接口,8组GDDR6存储器可提供4 Tbps的总带宽,1组带有错误检查和纠正功能的、运行频率为2666 MHz的DDR4存储器,符合PCI认证要求Speedster7tFPGA集成了带宽为20 Tbps的二维片上网络,692K的6输入查找表(LUT),40K Int8MAC提供高于80 TOps的算力,用于连接扩展卡的4通道PCIe Gen4连接器OCuLink。
Speedster7t是唯一可以支持GDDR6的FPGA芯片
BittWare公司副总裁Sam Bichara介绍,像微软、Facebook这类位于tier1的大公司早在3年前已经将FPGA应用到其数据中心的加速应用中,但是那些处于tier2或者更小的公司没有财力和人力将FPGA融合到自己应用中的工作,但是又急需FPGA硬件加速卡,所以BittWare和Achronix深度合作定制了这款加速器来满足这类客户的需求,客户拿来即可用。
根据客户需求的不同,这款加速器可以有不同的合作模式,比如如果客户的需求在100片以上时,BittWare可以根据客户功能要求重新设计和打造加速卡;当客户批量达到上万单品时,BittWare可以支持客户利用自己优选的、获得了授权的合约制造商来制造和测试S7t-VG6加速卡,客户在获得授权之后,甚至可以创建其自有的S7t-VG6加速卡品种。
使用VectorPath S7t-VG6 PCIe开发过程中遇到的任何问题,Achronix和BittWare均可以提供售后支持和服务。BittWare现在已经可以接受订单,2020年第二季度发货。
有了VectorPath S7t-VG6 PCIe加速卡,中小企业数据中心的CPU也不用“硬抗”了,交给VectorPath S7t-VG6 PCIe中的FPGA处理就OK了。
-
控制器
+关注
关注
114文章
17284浏览量
185666 -
以太网
+关注
关注
41文章
5777浏览量
176953 -
机器学习
+关注
关注
66文章
8517浏览量
135157
原文标题:有了这个基于FPGA的加速卡,中小企业做AI也不是事了!
文章出处:【微信号:mcuworld,微信公众号:嵌入式资讯精选】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
智算加速卡是什么东西?它真能在AI战场上干掉GPU和TPU!


边缘AI运算革新 DeepX DX-M1 AI加速卡结合Rockchip RK3588多路物体检测解决方案

寒武纪基于思元370芯片的MLU370-X8 智能加速卡产品手册详解

基于Xilinx XCKU115的半高PCIe x8 硬件加速卡

S7t-VG6 VectorPath加速卡的特性和功能
PCIe加速卡在数据中心的应用
AMD 以全球极快的纤薄尺寸电子交易加速卡扩展 Alveo 产品组合,助力广泛且具性价比的服务器部署

AMD 以全球极快的纤薄尺寸电子交易加速卡扩展 Alveo 产品组合,助力广泛且具性价比的服务器部署
AMD推出新款纤薄尺寸电子交易加速卡
比科奇助力推出首款全国产5G无线云网络加速卡
基于Achronix Speedster7t FPGA器件的AI基准测试
大模型向边端侧部署,AI加速卡朝高算力、小体积发展
EPSON差分晶振SG3225VEN频点312.5mhz应用于AI加速卡
基于菲数科技FA728Q加速卡实现低时延LLT应用





 工商网监
工商网监
评论