 电子发烧友App
电子发烧友App











 创作
创作 发文章
发文章 发帖
发帖  提问
提问  发资料
发资料 发视频
发视频资料介绍
描述
该项目介绍了我们对基于称为 AdderNet 的新型深度学习模型的硬件推理加速器设计和优化的研究。通过用绝对和 (SAD) 内核替换计算密集型卷积 (CONV) 操作,可以通过具有成本效益的加法器/减法器电路消除大量乘法器,这可以提高计算吞吐量,因为硬件限制。我们在 FPGA 设备上展示了基线 ResNet-20 实现 (CNN-ResNet-20) 和两个 AdderNet 设计变体 (ADD-ResNet-20) 之间的比较研究。我们利用自动 HLS(高级综合)和手动转换将 SAD 操作映射到 Xilinx Zynq MPSoC 的 FPGA DSP 块 (DSP48E2)。尤其是,当 DSP48 模块配置为 SIMD(单指令多数据)模式时,我们可以用一个 DSP 模块和最少的 LUT 逻辑资源支持至少两个 SAD 操作。在这个研究阶段,我们选择使用一个 DSP 来支持 2 个 SAD 操作,以增加 10% 的 LUT 和 5% 的推理时间开销为代价,总共可以减少 45.43% 的 DSP 利用率。这些结果鼓励我们探索新的深度学习加速器设计策略,以利用新兴的基于 SAD 内核的 AdderNet 模型以及每个 DSP ≥4 SAD 的积极 SIMD 配置来提高推理吞吐量。我们选择使用 1 个 DSP 支持 2 个 SAD 操作,以增加 10% 的 LUT 和 5% 的推理时间开销为代价,总共可以减少 45.43% 的 DSP 利用率。这些结果鼓励我们探索新的深度学习加速器设计策略,以利用新兴的基于 SAD 内核的 AdderNet 模型以及每个 DSP ≥4 SAD 的积极 SIMD 配置来提高推理吞吐量。我们选择使用 1 个 DSP 支持 2 个 SAD 操作,以增加 10% 的 LUT 和 5% 的推理时间开销为代价,总共可以减少 45.43% 的 DSP 利用率。这些结果鼓励我们探索新的深度学习加速器设计策略,以利用新兴的基于 SAD 内核的 AdderNet 模型以及每个 DSP ≥4 SAD 的积极 SIMD 配置来提高推理吞吐量。
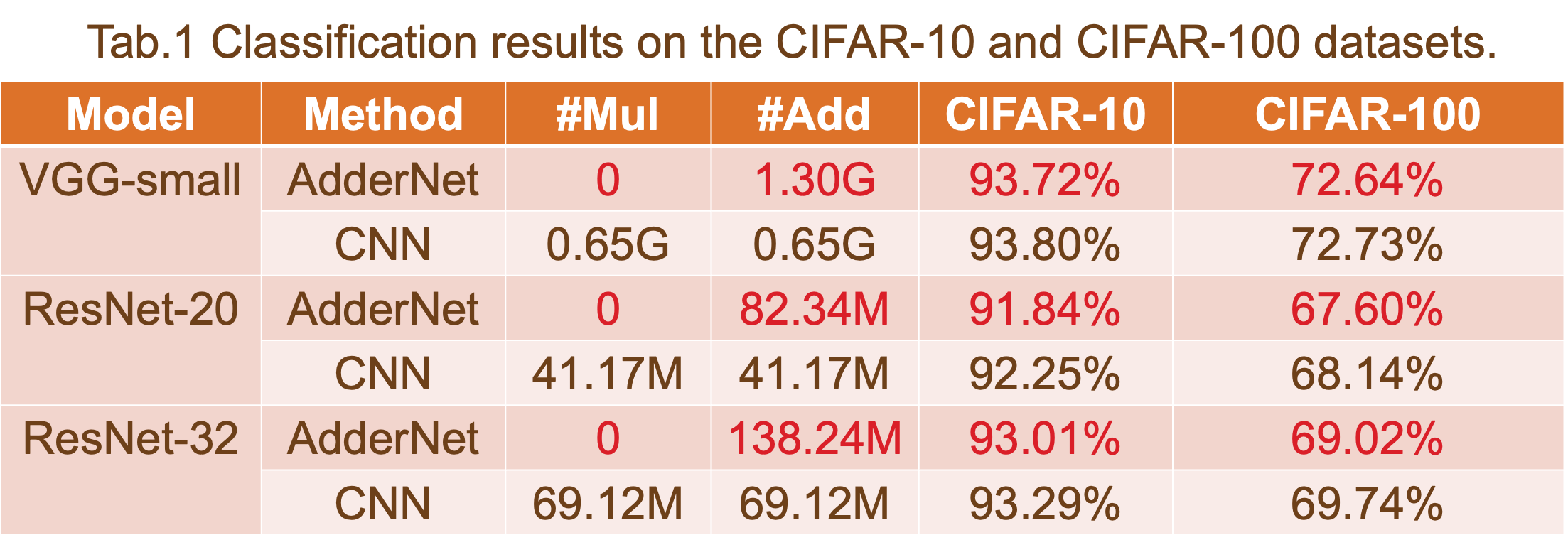
卷积神经网络(CNN)已广泛应用于计算机视觉任务领域。例如工业检测、自主视觉和机器人检测。然而,由于其大量的乘法运算和参数,很难将这些标准神经网络部署到具有效率吞吐量和功耗的嵌入式设备中。作为一种解决方案,AdderNet 在深度神经网络,尤其是卷积神经网络 (CNN) 中使用这些大规模乘法,以获得更便宜的加法以降低计算成本。
?
?
Function.1 CNN
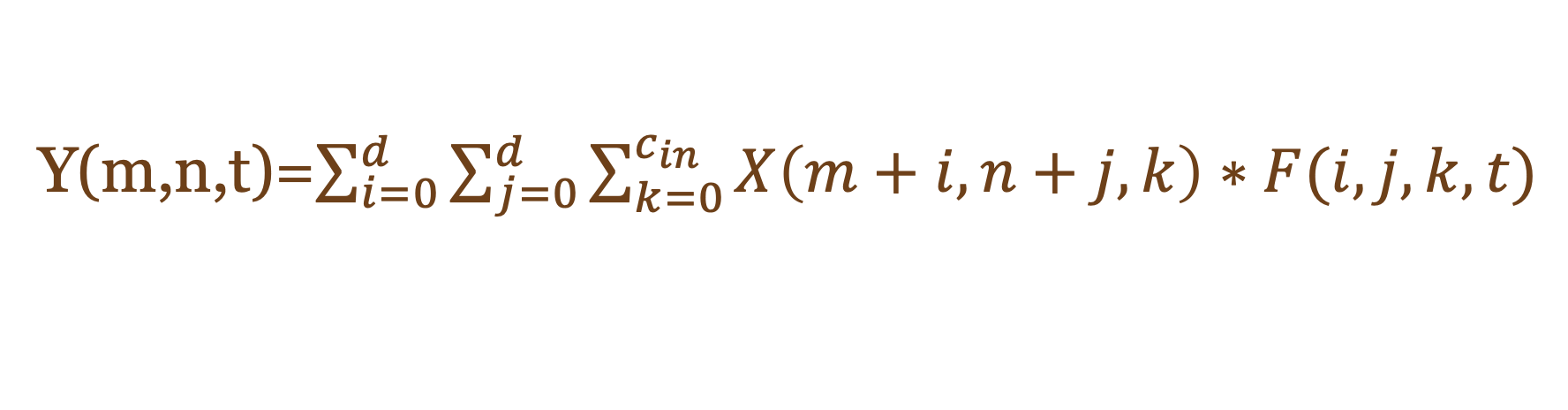
Function.2 人工神经网络
?
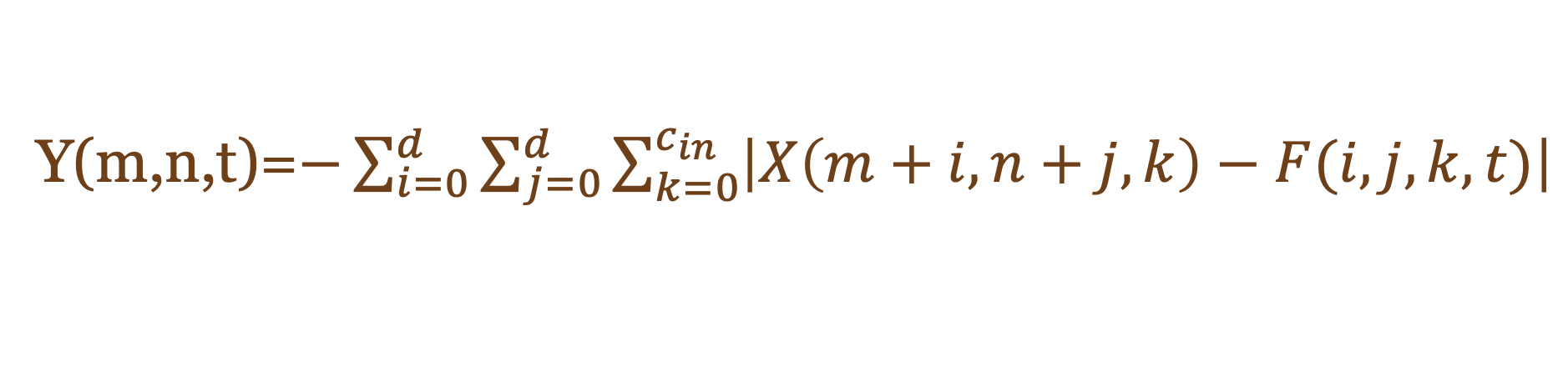
?
作为案例研究,我们选择 ResNet-20-CIFAR10 作为基线设计。ResNet-20-CIFAR10的处理引擎如图1所示。据我们所知,CNN 加速器有两种通用方法:单个 PE 和多个 PE。在这项工作中,我们在应用程序中使用了多个 PE 以获得更好的吞吐量。
?
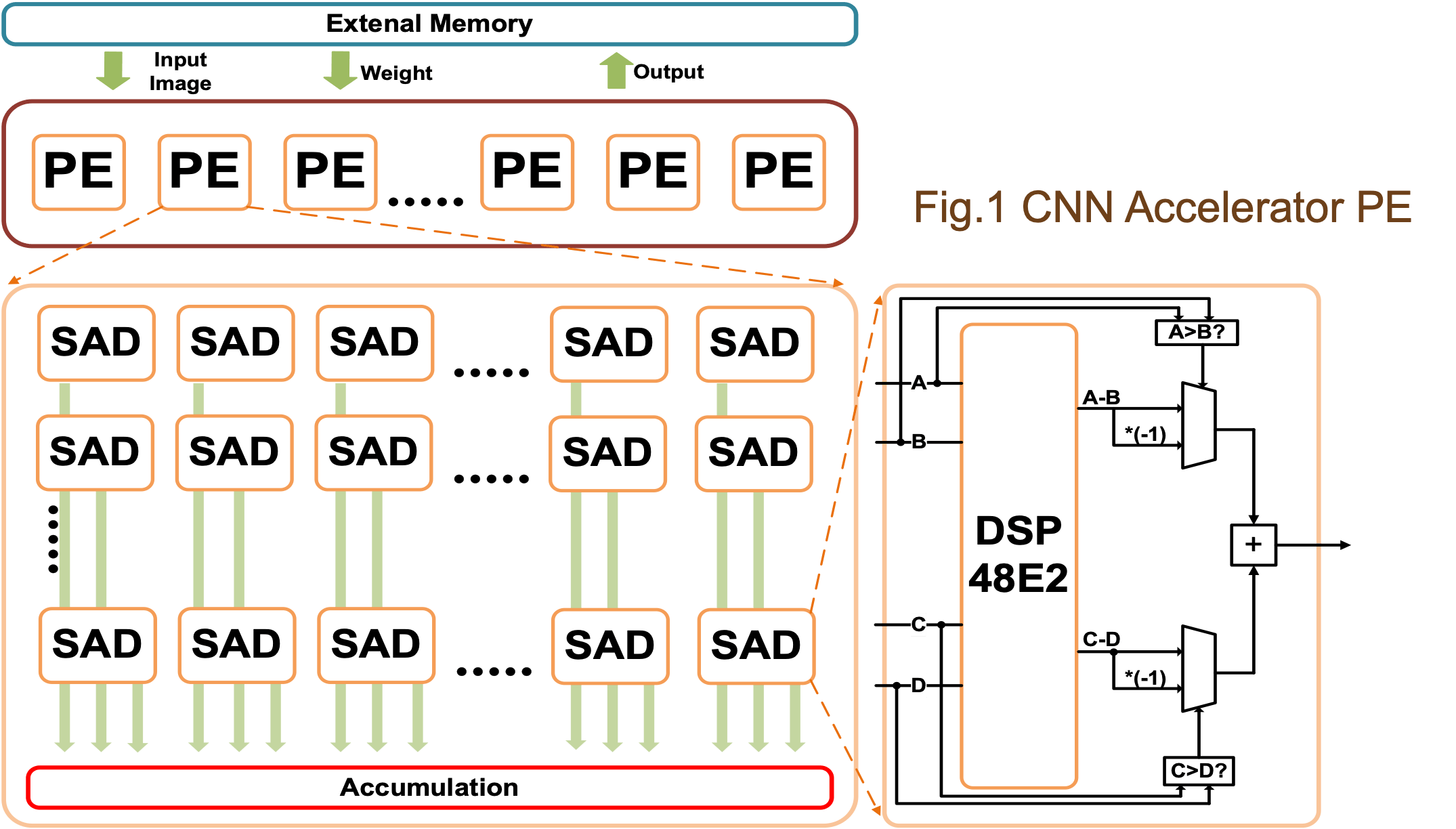
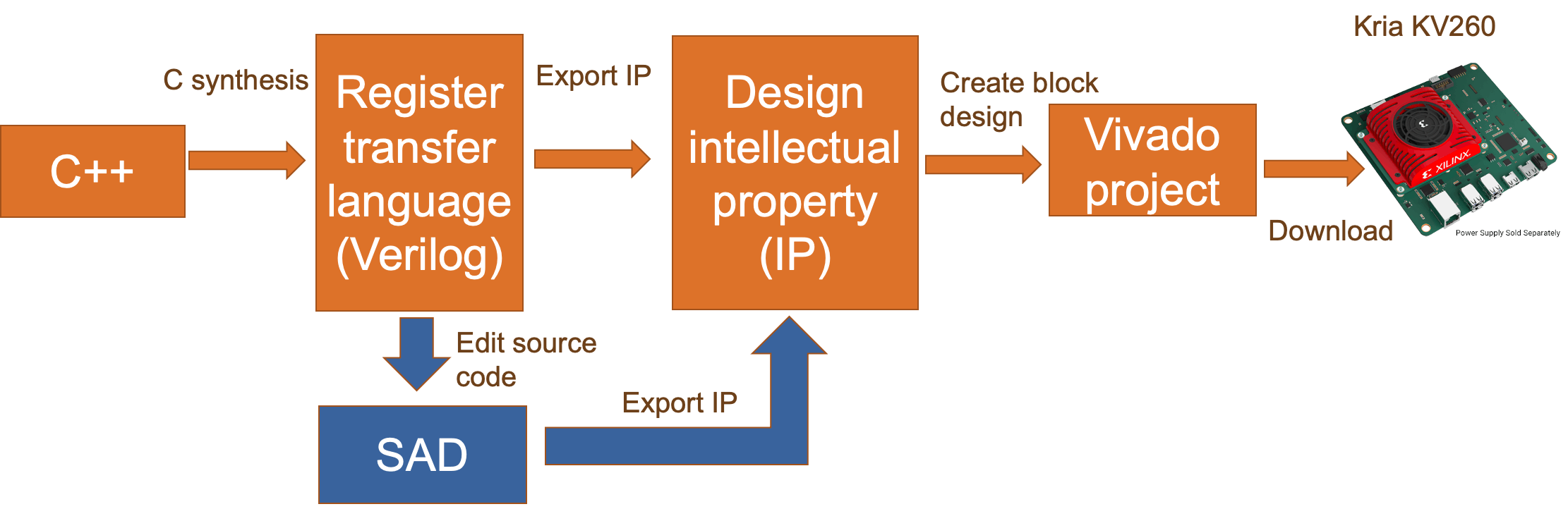
自动 HLS 和手动转换
Xilinx Vitis HLS 上的自动综合:
Xilinx Vitis HLS 可以从 C++ 代码自动生成 FPGA 项目。
对于 CNN-ResNet-20,综合报告显示该项目的硬件符合我们的目的。
对于 ADD-ResNet-20,合成报告并没有遵循我们之前的目的,因为 Vitis HLS 中的 C 合成不支持将 DSP48 配置为 SIMD 模式。
我们的解决方案:
将 SAD 操作设计为 C++ 中的独立函数。
替换 Xilinx Vitis HLS 生成的 Verilog 源文件中的 SAD 代码。
在 Xilinx Vivado 中重新综合该项目。
此外,通过编辑 SAD 代码,我们可以为 DSP48E2 配置更多选项。
?
Batch Normalization 融合可以减少计算量,并为模型量化提供更简洁的结构。
如 Function.3 和 4 所示,将细化权重应用于卷积层作为原始推理。但是考虑左边显示的加法器层的功能,作为卷积添加到函数中的细化权重不能用作卷积层。
由于乘法和加法的开销,这个函数不能提供 AdderNet 的硬件优势。
为了避免这种开销,我们使用额外的 for 循环来处理乘法和加法的开销,这将花费更多的时钟周期和硬件。
?
?

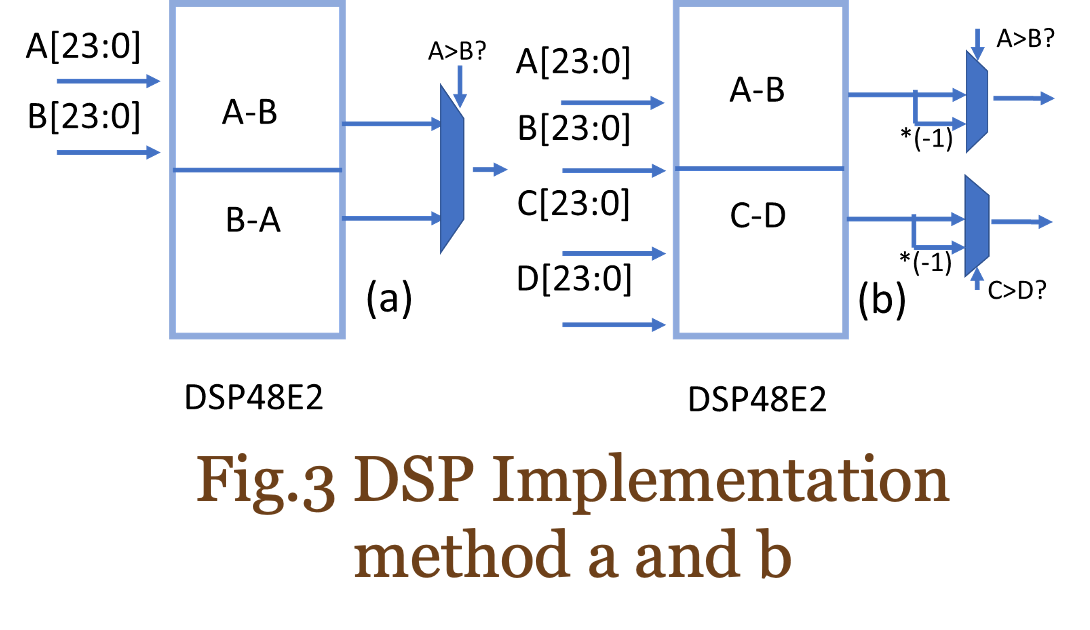
DSP配置方法
在本节中,将介绍两种 DSP48E2 配置方法:
方法 a:利用与 CONV 相同数量的 DSP,但与方法 b 相比,LUT 更少。
方法 b:利用一半的 DSP 作为 CONV,但与方法 a 相比,LUT 更多。
?
?
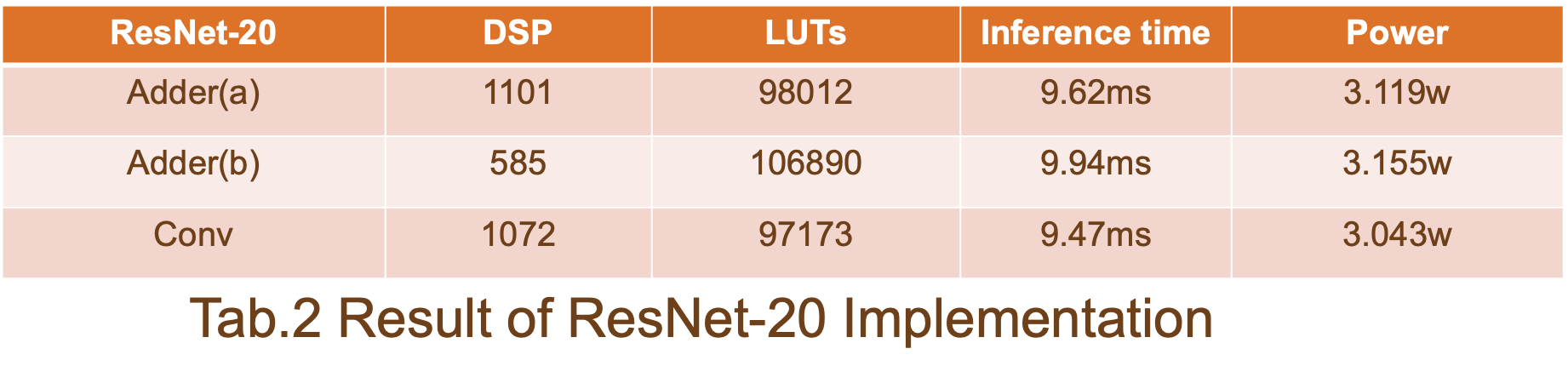
该报告显示,通过比较解决方案 a、解决方案 b 和 ResNet-20 基线的结果,我们的方法可以以增加 10% 的 LUT 和 5% 的推理时间开销为代价,减少大约 45% 的 DSP 利用率。
?
?
- Rapanda流加速器-实时流式FPGA加速器解决方案
- 《医用电子直线加速器》pdf 0次下载
- 基于FPGA的SIMD卷积神经网络加速器 24次下载
- 神经网络加速器简述 13次下载
- 基于深度学习的矩阵乘法加速器设计方案 3次下载
- 3小时学习神经网络与深度学习课件下载 0次下载
- 深度模型中的优化与学习课件下载 3次下载
- 一种基于机器学习的流簇大小推理模型 34次下载
- 深度学习是什么?了解深度学习难吗?让你快速了解深度学习的视频讲解 16次下载
- 工具包和Eval板帮助加速加速器应用 13次下载
- Green网络加速器 24次下载
- 加速器控制技术
- 兰州重离子加速器冷却储存环高频加速系统
- 实时频谱分析仪(RSA)在加速器中的应用
- 基于Profibus和Ethernet的加速器高频控制系统设
- FPGA和ASIC在大模型推理加速中的应用 605次阅读
- Pytorch深度学习训练的方法 238次阅读
- 什么是神经网络加速器?它有哪些特点? 545次阅读
- 如何处理cache miss问题以提高加速器效率呢? 1534次阅读
- 一个微型的粒子加速器 836次阅读
- 硬件加速器提升下一代SHARC处理器的性能 1336次阅读
- OpenCV+CUDA编译实现YOLOv5能加速 2626次阅读
- 充分利用数字信号处理器上的片内FIR和IIR硬件加速器 1806次阅读
- 多智体深度强化学习研究中首次将概率递归推理引入AI的学习过程 4925次阅读
- FPGA的深度学习加速器有怎样的挑战和机遇 6377次阅读
- 有多快?华为云刷新深度学习加速纪录 5241次阅读
- 一种基于FPGA的高性能DNN加速器自动生成方案 5569次阅读
- 斯坦福机器学习硬件加速器的课程学芯片技术机会来了 6163次阅读
- Veloce仿真环境下的SoC端到端硬件加速器功能验证 3691次阅读
- 优化基于FPGA的深度卷积神经网络的加速器设计 8093次阅读

 上传资料赚积分
上传资料赚积分下载排行
本周
- 1DD3118电路图纸资料
- 0.08 MB | 1次下载 | 免费
- 2AD库封装库安装教程
- 0.49 MB | 1次下载 | 免费
- 3PC6206 300mA低功耗低压差线性稳压器中文资料
- 1.12 MB | 1次下载 | 免费
- 4网络安全从业者入门指南
- 2.91 MB | 1次下载 | 免费
- 5DS-CS3A P00-CN-V3
- 618.05 KB | 1次下载 | 免费
- 6海川SM5701规格书
- 1.48 MB | 次下载 | 免费
- 7H20PR5电磁炉IGBT功率管规格书
- 1.68 MB | 次下载 | 1 积分
- 8IP防护等级说明
- 0.08 MB | 次下载 | 免费
本月
- 1贴片三极管上的印字与真实名称的对照表详细说明
- 0.50 MB | 103次下载 | 1 积分
- 2涂鸦各WiFi模块原理图加PCB封装
- 11.75 MB | 89次下载 | 1 积分
- 3锦锐科技CA51F2 SDK开发包
- 24.06 MB | 43次下载 | 1 积分
- 4锦锐CA51F005 SDK开发包
- 19.47 MB | 19次下载 | 1 积分
- 5PCB的EMC设计指南
- 2.47 MB | 16次下载 | 1 积分
- 6HC05蓝牙原理图加PCB
- 15.76 MB | 13次下载 | 1 积分
- 7802.11_Wireless_Networks
- 4.17 MB | 12次下载 | 免费
- 8苹果iphone 11电路原理图
- 4.98 MB | 6次下载 | 2 积分
总榜
- 1matlab软件下载入口
- 未知 | 935127次下载 | 10 积分
- 2开源硬件-PMP21529.1-4 开关降压/升压双向直流/直流转换器 PCB layout 设计
- 1.48MB | 420064次下载 | 10 积分
- 3Altium DXP2002下载入口
- 未知 | 233089次下载 | 10 积分
- 4电路仿真软件multisim 10.0免费下载
- 340992 | 191390次下载 | 10 积分
- 5十天学会AVR单片机与C语言视频教程 下载
- 158M | 183342次下载 | 10 积分
- 6labview8.5下载
- 未知 | 81588次下载 | 10 积分
- 7Keil工具MDK-Arm免费下载
- 0.02 MB | 73815次下载 | 10 积分
- 8LabVIEW 8.6下载
- 未知 | 65989次下载 | 10 积分





 工商网监
工商网监
评论