 Google最强模型BERT出炉
Google最强模型BERT出炉

经过近几年的发展,深度学习给自然语言处理带来了很多新的变化,包括 Word2Vec、ELMO、OpenAI GPT、Glove、Fasttext 等主流模型也在这一端时间内涌现。直到最近 Google 发布的论文“ Pre-training of Deep Bidirectional Transformers for Language Understanding ”中提到的 BERT 模型又刷新了自然语言处理的 11 项记录。
在不少人看来,BERT 对自然语言处理的研究具有里程碑式的意义,至少在复旦大学计算机科学技术学院副教授邱锡鹏看来:“证明了一个非常深的模型可以显著提高 NLP 任务的准确率,而这个模型可以从无标记数据集中预训练得到。”
也正是因为如此,深度学习的不可解释性,在面对某个具体任务时进行迁移学习是十分困难的,相对而言,基于知识图谱的自然语言理解则是可解释性的,更加类似于人类思考过程的技术。BERT 的出现或将对提高知识图谱质量,并进一步提高自然语言处理的质量将非常有帮助。
于是,在以移动互联网为基础高速发展的背景之下,人们获取信息并进行传播的渠道越来越丰富、数据量也越来越巨大,如何更好地进行人机语言交互,让机器既能听懂又能学会迁移?如智能客服、对话机器人已作为主要落地方式被应用于电商、游戏、金融等场景。
今年7月,思必驰北京研发院首先提出了启发式对话系统的框架,通过话题路径规划和知识点推荐模型,实现信息传播和目标引导,可以帮助企业快速构建信息服务对话机器人,并能大幅提升关键信息的用户触达能力。
此外,自然语言处理还在搜索、推荐、翻译等文本类场景上有着更为广泛的落地,放在目前来看,如国外的 Facebook、微软必应等,国内的阿里、今日头条等不少门户类公司都有自己相对完备的搜索、推荐系统。
现在,CSDN 就为大家提供了这样一个机会,让你能够聆听以上公司在自然语言处理方面的最新技术实践,并有机会与它们的资深技术人员面对面交流。
2018 年 11 月 8-9 日,由中国 IT 社区 CSDN 与硅谷 AI 社区 AICamp 联合出品的 2018 AI 开发者大会(AI NEXTCon)将于北京召开。
本次大会设有“自然语言处理技术专场”,我们很荣幸邀请到在研究和工业界都极富盛名的一线技术专家们:思必驰北京研发院院长、公司副总裁 初敏、Facebook语音识别科学家 Baiyang Liu、字节跳动高级技术总监和杰出科学家 Xiaobing Liu、阿里巴巴智能服务事业部北京团队负责人 孙健、微软(亚洲)互联网工程院资深应用科学研发总监陈一宁。
下面重磅介绍自然语言处理技术专题的讲师团和他们的议题概要:
初敏:思必驰北京研发院院长、公司副总裁
演讲主题:启发式对话助力企业服务智能化
初敏博士毕业于中科院声学所,主要研究方向覆盖语音识别与合成、自然语言处理、机器学习和数据挖掘、大数据处理和计算等,在相关领域发表了近百篇学术论文并取得30多项国内外专利。
2000年,初敏博士加入微软亚洲研究院,从事科学研究近10年,创建并领导语音合成研究小组,研制出了第一个中英文双语语音合成系统“木兰”;2009年入职阿里云,承担过各种大数据应用项目。从2014开始,组建阿里iDST智能语音交互团队,在短短两年时间,完成语音交互全链路技术的研发和应用落地,他们的技术在淘宝客服、支付宝客服、Yun OS、手机支付宝、手机淘宝、钉钉等产品广泛应用;2017年加入思必驰,担任思必驰公司副总裁,组建思必驰北京研发院并担任院长,负责语音合成、自然语言处理等核心技术的研发,以及智能语音交互技术在企业服务智能化等新场景的产品研发和业务拓展。
Baiyang Liu:Facebook语音识别科学家
演讲议题:自然语言理解在Facebook的应用与实践
Baiyang Liu是Facebook语音识别研究科学家。自2015年初以来,他一直致力于建立众多支持Facebook AI产品的话语理解和对话系统。在此之前,Baiyang是亚马逊语音识别系统的早期机器学习工程师之一。他获得计算机科学博士学位,主攻计算机视觉领域。
Xiaobing Liu:字节跳动高级技术总监和杰出科学家
演讲议题:大规模深度学习和序列模型的研究及应用
Xiaobing Liu,自2014年起担任Google Brain Staff软件工程师和机器学习研究员。工作中,他专注于TensorFlow以及一些可以应用深度学习来改进Google产品的关键应用,如Google Ads、Google Play推荐、Google翻译、医学大脑等。他的研究兴趣从系统到应用机器学习如ASR、机器翻译、医学HER建模、推荐建模。他的研究成果已成功应用于雅虎、腾讯、Google的各类商业产品。他曾担任2017年ACL计划委员会和2017年AAAI会议主席,负责包括一些顶级会议的部分出版物。
孙 健:阿里巴巴智能服务事业部北京团队负责人
演讲议题:关于人机对话交互的反思、实践和未来展望
孙健,阿里巴巴智能服务事业部北京团队负责人。他主导的自然语言处理基础平台有力支撑和服务了淘宝搜索、阿里妈妈广告等核心业务,主导了阿里巴巴自然交互平台(Natural User Interface, NUI)的设计开发,NUI平台广泛应用于天猫魔盒、互联网汽车等各种设备中。目前他正带领团队打造面向全行业的企业智能服务对话机器人(云小蜜),从而让每一家企业/组织能够及时响应用户的需求,与用户进行7*24的自然交互。
陈一宁:微软(亚洲)互联网工程院资深应用科学研发总监
演讲议题:搜索中的自然语言先验知识
陈一宁是清华大学博士,主要研发方向涵盖语音识别与合成、自然语言处理、人工智能、大数据等方向,并在相关领域发表多篇论文并取得多项专利。2004年,陈一宁博士加入微软亚洲研究院,从事语音合成方面的研究。2009年加入阿里巴巴,负责多项算法工作,是神马搜索的共同创始人,并曾负责iDST智能语音方向的商业化。2017年加入微软互联网工程院,从事自然语言处理相关的研发工作。
除了语音技术专题之外,我们还为大家准备了“语音技术”、“机器学习工具”、“数据分析”、“机器学习”、“计算机视觉”、“知识图谱”等技术专题,以及“智慧金融”、“智能驾驶”、“智慧医疗”等行业峰会。大会完整日程以及嘉宾议题请查看下方海报。
-
Google
+关注
关注
5文章
1791浏览量
59248 -
AI
+关注
关注
88文章
35733浏览量
282335 -
深度学习
+关注
关注
73文章
5569浏览量
123078
发布评论请先 登录
Google Fast Pair服务简介
2025 Google I/O大会演讲亮点回顾
Gemini API集成Google图像生成模型Imagen 3
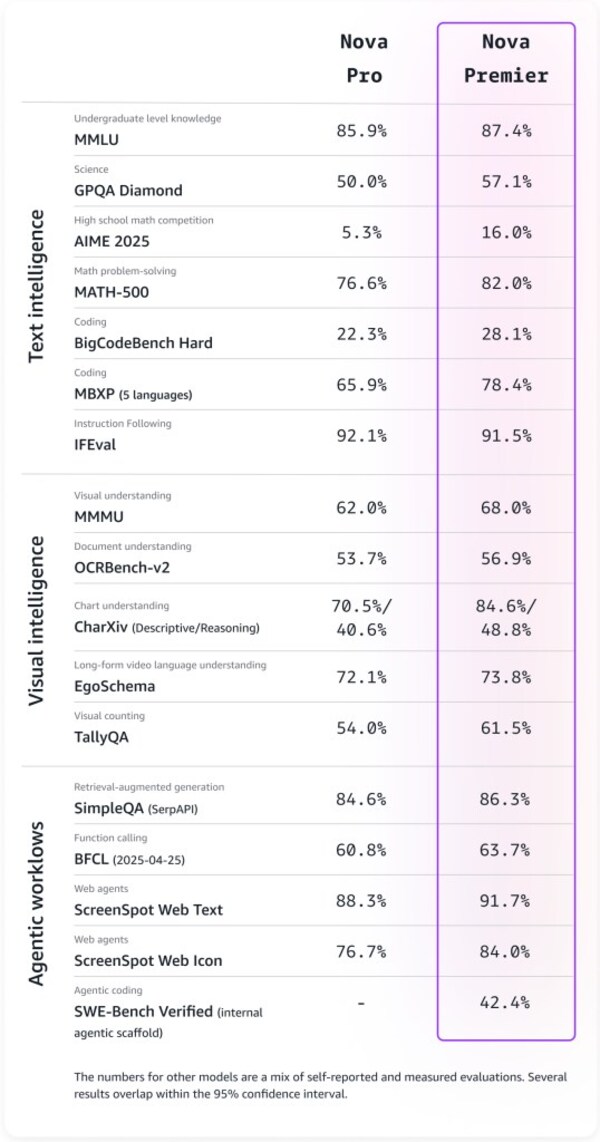
亚马逊功能最强模型Amazon Nova Premier现已正式可用
Google Gemma 3开发者指南
低至?2.27/h!就能使用全球最强开元模型——千问 QwQ-32B

Google发布最新AI模型Gemma 3
?VLM(视觉语言模型)?详细解析

如何开发一款Google Find My Tag?
中科驭数DPU助力大模型训练和推理

Google Play如何帮助您的应用变现

Google两款先进生成式AI模型登陆Vertex AI平台
【「大模型启示录」阅读体验】如何在客服领域应用大模型
Google Cloud如何守护大模型安全

Google AI Edge Torch的特性详解






 工商网监
工商网监
评论