 ALINX VD100低功耗端侧大模型部署方案,运行3B模型功耗仅5W?!
ALINX VD100低功耗端侧大模型部署方案,运行3B模型功耗仅5W?!

大模型能运行≠用户体验好。
IDC 预测,到 2026 年,全球超过 50% 的企业 AI 工作负载将部署在边缘设备上。在 AI 部署逐渐从云端转向边缘端的趋势下,越来越多智能终端开始尝试在本地运行完整模型,以降低延迟、保护隐私并节省通信成本。但真正落地时却发现:功耗吃紧、模型裁剪严重、开发流程繁琐,使得“能运行”远远达不到“用得好”。
基于 ALINX VD100 开发平台,客户打造出一套面向 AI 终端的大模型部署方案,实测可支持 8B 模型运行、运行 3B 模型功耗仅 5W,推理速度达 12 tokens/s,远优于市面同类产品。

本方案基于 AMD Versal ACAP 架构,通过硬件架构、推理框架、模型压缩等多个层级的全栈优化,显著提升大模型端侧部署的能耗比。
可重构数据流硬件架构
可重构数据流+VLIW处理器阵列+可编程逻辑,提升并行度与灵活性
无缓存设计+分布式片上存储,实现低延迟、确定性响应
NoC 优化与指令调度提升计算利用率与带宽利用率至96%
原生支持矩阵-向量乘、注意力融合、激活函数融合等AI 关键算子,支持混合数据模型和嵌套量化
→在同等功耗下,平台可以支持更多模型层级与更大参数规模。
自研开发工具链
自研高层次离散事件仿真器,较 RTL 级仿真器仿真速度优化300 倍,支持全部功能模拟与自动设计空间搜索
自研Kernel 和 Buffer 布局优化工具,减少 50% 访存冲突,大幅缩短部署时间
→ 快速搭建模型、开发体验友好。
优化推理运行
优化硬件调用开销,管理异步算子调用。
设计连续地址内存池,规避伙伴系统分配物理内存页碎片问题,减少 50% 内存占用。
→让模型跑得稳,持续运行不掉链子。
敏捷开发推理框架
融合采样计算,推理速度提升 100 倍
融合 MLP、MoE 等算子,通过流水线优化重叠不同算子计算时间
软件层兼容Huggingface 生态,仅需 Transformers 模型代码+safetensors 权重文件,即可一键运行主流 Transformer 模型
→优化大模型推理流程,实现敏捷开发,迁移更快,体验更流畅。
模型压缩
端侧推理对存储与计算资源要求极高,方案采用精细化压缩策略:
支持 BF16、NF4 混合精度压缩,在保持精度基础上显著降低计算压力
PCA 聚类压缩 LM-Head,减少 90% 的访存与计算负担,同时保持推理准确性
→模型轻巧运行稳,真正适配边缘与终端AI场景。
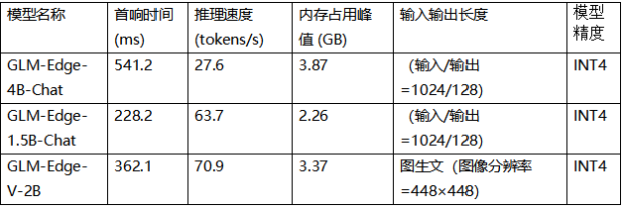
实测效果
5W 功耗实现行业领先推理性能
基于 ALINX VD100 平台实测,模型运行结果如下:

完整实测报告和对比报告,联系 ALINX 获取。
应用场景
AI 终端的可能性不止于你想象
这套端侧大模型部署方案已在多种高要求场景中落地:
新型移动智能终端:包括 AI 可穿戴设备、AI 玩具、人形机器人等,离线运行大模型,保护用户隐私
工业机器人/无人系统:保障实时安全
太空/油田等极端场景:低功耗运行,降低散热负担,保障系统稳定性
如果你也在评估“端侧+大模型”,
欢迎和我们聊聊
如果您正在:
寻找低功耗、高效能的大模型端侧运行平台
希望快速验证模型部署可行性
评估 FPGA 在 AI 产品中的可落地性
欢迎访问ALINX官网,联系我们,获取完整技术白皮书、项目评估与对接服务。
审核编辑 黄宇
-
FPGA
+关注
关注
1648文章
22146浏览量
623001 -
大模型
+关注
关注
2文章
3282浏览量
4377
发布评论请先 登录
米尔RK3576部署端侧多模态多轮对话,6TOPS算力驱动30亿参数LLM
基于米尔瑞芯微RK3576开发板的Qwen2-VL-3B模型NPU多模态部署评测
端侧大模型迎来“轻”革命!移远通信 × RWKV 打造“轻量AI大脑”

后摩智能发布全新端边大模型AI芯片
【VisionFive 2单板计算机试用体验】3、开源大语言模型部署
德赛西威与面壁智能发布端侧大模型语音交互方案
首创开源架构,天玑AI开发套件让端侧AI模型接入得心应手
AI大模型端侧部署正当时:移远端侧AI大模型解决方案,激活场景智能新范式

AI大模型端侧部署正当时:移远端侧AI大模型解决方案,激活场景智能新范式
4台树莓派5跑动大模型!DeepSeek R1分布式实战!

添越智创基于 RK3588 开发板部署测试 DeepSeek 模型全攻略
基于AX650N的M.2智能推理卡解决方案
AI模型部署边缘设备的奇妙之旅:目标检测模型
智谱推出四个全新端侧模型 携英特尔按下AI普及加速键





 工商网监
工商网监
评论