 京东商品详情商品详情接口技术实现:从数据抓取到结构化解析全方案
京东商品详情商品详情接口技术实现:从数据抓取到结构化解析全方案

?
商品详情数据是电商分析的核心基础,包含价格、规格、库存、促销等关键信息。本文将系统讲解京东商品详情接口的技术实现,重点解决动态参数构造、多维度数据提取、反爬机制应对等核心问题,提供一套合规高效的技术方案,同时严格遵守平台规则与数据采集规范。
一、详情接口原理与合规要点
京东商品详情页通过主接口加载基础信息,配合多个辅助接口获取规格、库存、促销等细分数据,采用 JSON 格式返回。实现该接口需遵循以下合规要点:
请求频率控制:单 IP 对同一商品详情请求间隔不低于 30 秒,单日单 IP 请求不超过 300 次
数据用途限制:仅用于个人学习研究、价格比较,不得用于商业竞争或恶意爬取
反爬机制尊重:不使用破解、伪造请求头等手段,模拟正常用户浏览行为
隐私保护:自动过滤任何可能涉及用户隐私的信息,仅采集公开商品数据
商品详情获取的核心技术流程如下:
商品ID解析 → 主详情接口请求 → 辅助接口数据补充 → 多源数据融合 → 结构化存储
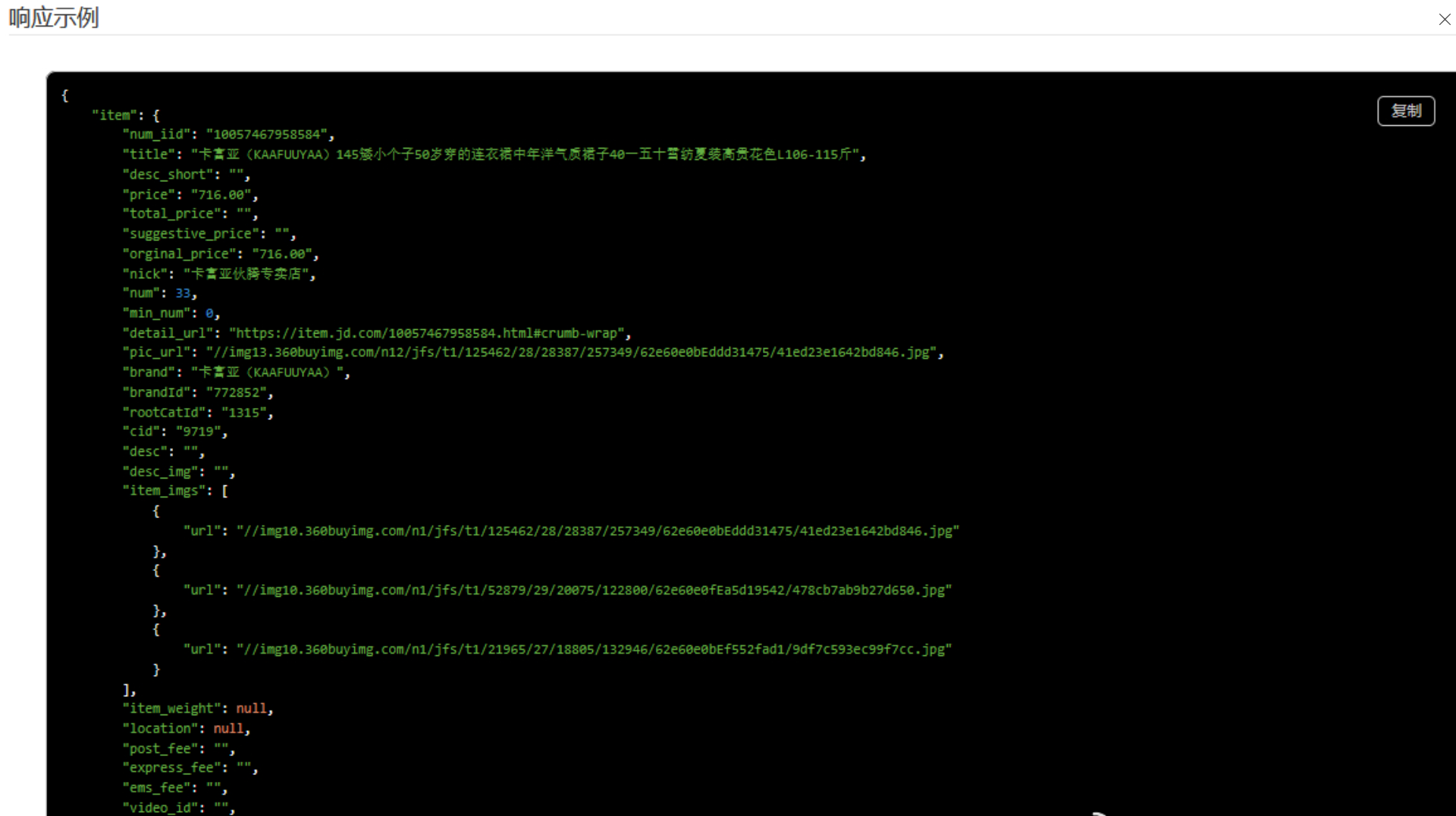
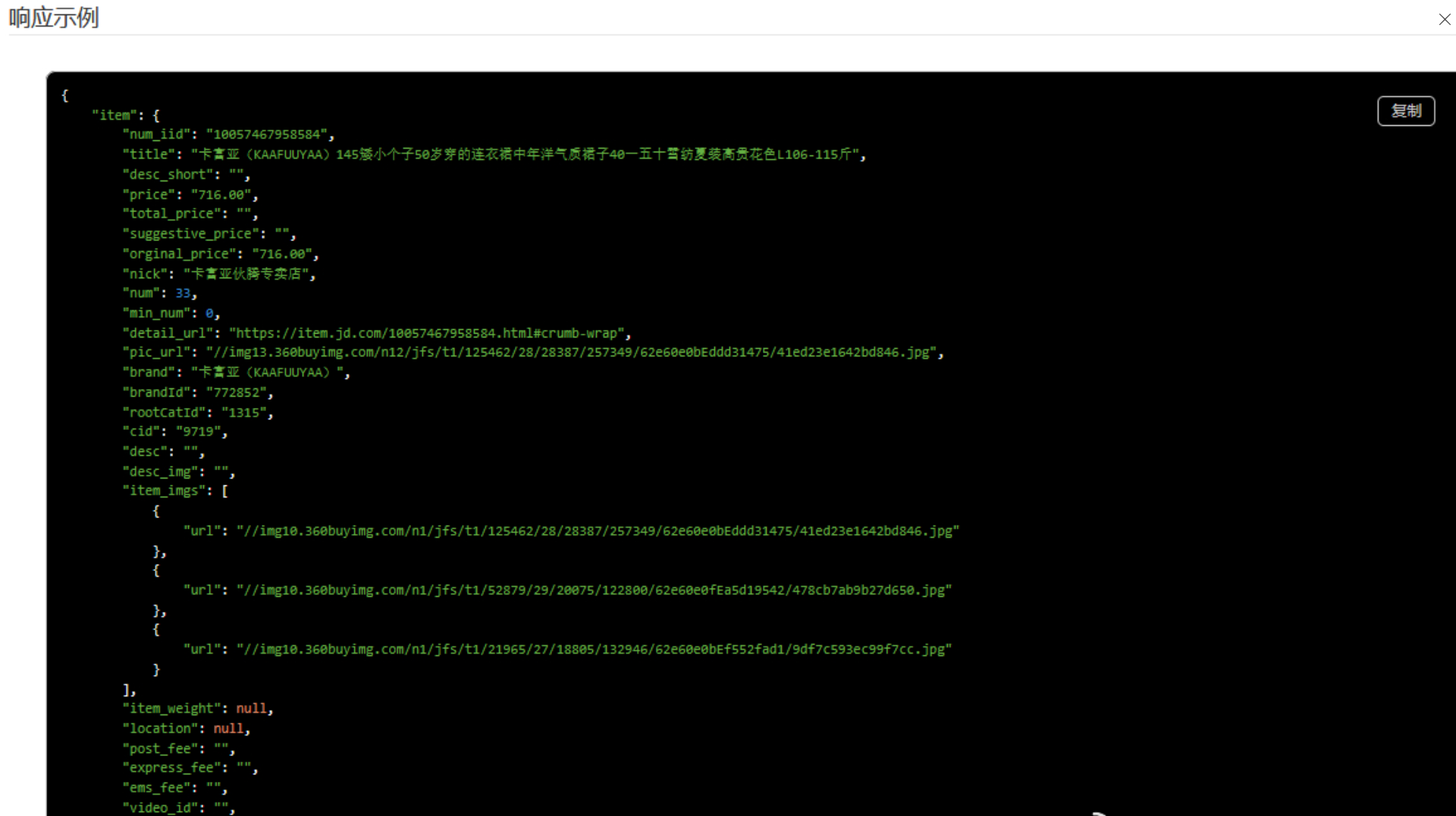
二、核心技术实现
1. 商品详情参数生成器
京东商品详情接口需要特定参数组合,包括商品 ID、动态签名等,部分参数需实时生成:
运行
import time
import random
import hashlib
import string
class JdDetailParamsGenerator:
"""京东商品详情参数生成器"""
def __init__(self):
self.app_key = "12574478" # 公共应用标识
self.platform = "h5" # 平台标识
def generate_main_params(self, sku_id):
"""生成主详情接口参数"""
t = str(int(time.time() * 1000))
nonce = self._generate_nonce(16)
params = {
"skuId": sku_id,
"cat": "", # 分类ID,留空自动获取
"area": "1_72_2799_0", # 地区编码
"shopId": "", # 店铺ID,留空自动获取
"venderId": "", # 商家ID,留空自动获取
"paramJson": '{"platform":"' + self.platform + '"}',
"t": t,
"nonce": nonce,
"appkey": self.app_key,
"callback": f"jsonp_{int(time.time() * 1000)}_{random.randint(1000, 9999)}"
}
# 生成签名
params["sign"] = self._generate_sign(params)
return params
def generate_stock_params(self, sku_id, area="1_72_2799_0"):
"""生成库存接口参数"""
return {
"skuId": sku_id,
"area": area,
"cat": "",
"extraParam": '{"originid":"1"}',
"callback": f"jQuery{random.randint(1000000, 9999999)}_{int(time.time() * 1000)}"
}
def generate_price_params(self, sku_id):
"""生成价格接口参数"""
return {
"skuIds": f"J_{sku_id}",
"type": "1",
"area": "1_72_2799_0",
"callback": f"jQuery{random.randint(1000000, 9999999)}_{int(time.time() * 1000)}"
}
def _generate_nonce(self, length=16):
"""生成随机字符串"""
return ''.join(random.choices(string.ascii_letters + string.digits, k=length))
def _generate_sign(self, params):
"""生成签名"""
# 按参数名排序并拼接
sorted_params = sorted(params.items(), key=lambda x: x[0])
sign_str = "&".join([f"{k}={v}" for k, v in sorted_params if k != "sign"])
# 加入固定密钥(示例)
sign_str += "&secret=jd_detail_demo_key"
# 计算MD5签名
return hashlib.md5(sign_str.encode()).hexdigest().upper()
2. 详情页请求管理器
管理多个接口的请求发送,处理反爬机制和会话维护:
python
运行
import time
import random
import requests
from fake_useragent import UserAgent
class JdDetailRequester:
"""京东商品详情请求管理器"""
def __init__(self, proxy_pool=None):
self.main_api = "https://h5api.m.jd.com/h5/mtop.taobao.detail.getdetail/6.0/"
self.stock_api = "https://c0.3.cn/stock"
self.price_api = "https://p.3.cn/prices/mgets"
self.proxy_pool = proxy_pool or []
self.ua = UserAgent()
self.session = requests.Session()
self.last_request_time = 0
self.min_interval = 30 # 同一商品请求最小间隔(秒)
# 初始化会话
self._init_session()
def _init_session(self):
"""初始化会话状态"""
# 访问首页获取基础Cookie
self.session.get(
"https://www.jd.com",
headers=self._get_base_headers(),
timeout=10
)
# 设置基础Cookie
self.session.cookies.set("ipLoc-djd", "1-72-2799-0", domain=".jd.com")
self.session.cookies.set("areaId", "1", domain=".jd.com")
def _get_base_headers(self):
"""基础请求头"""
return {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive"
}
def _get_headers(self, referer="https://www.jd.com/"):
"""生成详情页请求头"""
headers = self._get_base_headers()
headers["Referer"] = referer
headers["X-Requested-With"] = "XMLHttpRequest"
return headers
def _get_proxy(self):
"""获取随机代理"""
if not self.proxy_pool:
return None
return random.choice(self.proxy_pool)
def _check_interval(self):
"""控制请求间隔"""
current_time = time.time()
elapsed = current_time - self.last_request_time
if elapsed < self.min_interval:
sleep_time = self.min_interval - elapsed + random.uniform(2, 5)
print(f"请求间隔不足,休眠 {sleep_time:.1f} 秒")
time.sleep(sleep_time)
self.last_request_time = time.time()
def fetch_main_detail(self, params):
"""获取主详情数据"""
self._check_interval()
headers = self._get_headers()
proxy = self._get_proxy()
proxies = {"http": proxy, "https": proxy} if proxy else None
try:
response = self.session.get(
self.main_api,
params=params,
headers=headers,
proxies=proxies,
timeout=15
)
if response.status_code != 200:
print(f"主详情请求失败,状态码: {response.status_code}")
return None
if self._is_blocked(response.text):
print("主详情请求被拦截")
self._handle_blocked(proxy)
return None
return response.text
except Exception as e:
print(f"主详情请求异常: {str(e)}")
return None
def fetch_stock(self, params):
"""获取库存数据"""
headers = self._get_headers(f"https://item.jd.com/{params['skuId']}.html")
proxy = self._get_proxy()
proxies = {"http": proxy, "https": proxy} if proxy else None
try:
response = self.session.get(
self.stock_api,
params=params,
headers=headers,
proxies=proxies,
timeout=15
)
if response.status_code != 200:
print(f"库存请求失败,状态码: {response.status_code}")
return None
return response.text
except Exception as e:
print(f"库存请求异常: {str(e)}")
return None
def fetch_price(self, params):
"""获取价格数据"""
headers = self._get_headers(f"https://item.jd.com/{params['skuIds'].split('_')[1]}.html")
proxy = self._get_proxy()
proxies = {"http": proxy, "https": proxy} if proxy else None
try:
response = self.session.get(
self.price_api,
params=params,
headers=headers,
proxies=proxies,
timeout=15
)
if response.status_code != 200:
print(f"价格请求失败,状态码: {response.status_code}")
return None
return response.text
except Exception as e:
print(f"价格请求异常: {str(e)}")
return None
def _is_blocked(self, response_text):
"""判断是否被反爬拦截"""
block_keywords = [
"验证码",
"访问过于频繁",
"安全验证",
"请稍后再试"
]
for keyword in block_keywords:
if keyword in response_text:
return True
return False
def _handle_blocked(self, proxy):
"""处理被拦截情况"""
if proxy and proxy in self.proxy_pool:
self.proxy_pool.remove(proxy)
# 重新初始化会话
self._init_session()
# 延迟一段时间
time.sleep(random.uniform(10, 20))
3. 商品详情数据解析器
解析多个接口返回的数据,提取结构化商品信息:
python
运行
import re
import json
from datetime import datetime
from lxml import etree
class JdDetailParser:
"""京东商品详情数据解析器"""
def __init__(self):
# JSONP格式解析正则
self.jsonp_pattern = re.compile(r'jsonp_d+_d+((.*?))')
self.jquery_pattern = re.compile(r'jQueryd+_d+((.*?));')
def parse_main_detail(self, jsonp_text):
"""解析主详情数据"""
# 提取JSON数据
match = self.jsonp_pattern.search(jsonp_text)
if not match:
return None
try:
json_data = json.loads(match.group(1))
except json.JSONDecodeError:
print("主详情JSON解析失败")
return None
# 检查返回状态
if json_data.get("ret", [""])[0] != "SUCCESS::调用成功":
return None
result = {}
data = json_data.get("data", {})
# 基础信息提取
base = data.get("base", {})
result["product_id"] = base.get("skuId", "")
result["name"] = base.get("name", "").strip()
result["brand"] = base.get("brand", {}).get("name", "")
result["brand_id"] = base.get("brand", {}).get("id", "")
result["shop_name"] = base.get("shopInfo", {}).get("name", "")
result["shop_id"] = base.get("shopInfo", {}).get("shopId", "")
result["is_self"] = base.get("shopInfo", {}).get("isSelf", False)
# 分类信息
category = data.get("category", [])
result["categories"] = [c.get("name", "") for c in category if c.get("name")]
# 商品图片
images = data.get("images", {})
result["main_images"] = [img.get("url", "") for img in images.get("imgList", [])]
result["video_url"] = images.get("videoInfo", {}).get("url", "")
# 商品参数
item_desc = data.get("itemDesc", {})
result["params"] = self._parse_params(item_desc.get("keyAttributes", []))
# 详情描述
result["description"] = self._parse_description(item_desc.get("detail", ""))
return result
def parse_stock(self, jquery_text):
"""解析库存数据"""
# 提取JSON数据
match = self.jquery_pattern.search(jquery_text)
if not match:
return None
try:
json_data = json.loads(match.group(1))
except json.JSONDecodeError:
print("库存JSON解析失败")
return None
stock = {
"has_stock": json_data.get("stock", {}).get("hasStock", False),
"stock_num": json_data.get("stock", {}).get("stockNum", 0),
"limit_buy": json_data.get("stock", {}).get("limitBuy", 0),
"warehouse": json_data.get("stock", {}).get("warehouse", "")
}
return stock
def parse_price(self, jquery_text):
"""解析价格数据"""
# 提取JSON数据
match = self.jquery_pattern.search(jquery_text)
if not match:
# 尝试直接解析JSON
try:
json_data = json.loads(jquery_text)
except:
return None
else:
try:
json_data = json.loads(match.group(1))
except json.JSONDecodeError:
print("价格JSON解析失败")
return None
if not isinstance(json_data, list) or len(json_data) == 0:
return None
price_info = json_data[0]
return {
"price": float(price_info.get("p", 0)),
"original_price": float(price_info.get("m", 0)) if price_info.get("m") else 0,
"currency": "CNY",
"update_time": datetime.now()
}
def _parse_params(self, key_attributes):
"""解析商品参数"""
params = {}
for attr in key_attributes:
name = attr.get("name", "").strip()
value = attr.get("value", "").strip()
if name and value:
params[name] = value
return params
def _parse_description(self, detail_html):
"""解析商品详情描述"""
if not detail_html:
return []
# 提取图片URL
tree = etree.HTML(detail_html)
img_tags = tree.xpath('//img/@src')
# 处理相对路径
images = []
for img in img_tags:
if img.startswith(('http:', 'https:')):
images.append(img)
elif img.startswith('//'):
images.append(f"https:{img}")
elif img.startswith('/'):
images.append(f"https://item.jd.com{img}")
return images
def merge_details(self, main_detail, stock, price):
"""合并多源数据"""
if not main_detail:
return None
merged = main_detail.copy()
merged["stock"] = stock if stock else {}
merged["price"] = price if price else {}
merged["crawl_time"] = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
return merged
4. 商品规格处理器
解析商品规格参数和可选配置:
python
运行
import re
import json
class JdSkuSpecificationProcessor:
"""京东商品规格处理器"""
def __init__(self):
pass
def parse_specifications(self, html_content):
"""从HTML中解析规格信息"""
try:
# 查找规格数据
pattern = re.compile(r'var specData = (.*?);')
match = pattern.search(html_content)
if not match:
return None
spec_data = json.loads(match.group(1))
return self._process_spec_data(spec_data)
except Exception as e:
print(f"规格解析失败: {str(e)}")
return None
def _process_spec_data(self, spec_data):
"""处理规格数据"""
result = {
"spec_groups": [], # 规格组
"sku_mapping": {} # SKU映射关系
}
# 处理规格组
for group in spec_data.get("specList", []):
spec_group = {
"name": group.get("name", ""),
"items": []
}
# 处理规格项
for item in group.get("specItemList", []):
spec_group["items"].append({
"name": item.get("name", ""),
"img_url": item.get("imgUrl", ""),
"selected": item.get("isSelected", False),
"disabled": item.get("disabled", False)
})
if spec_group["items"]:
result["spec_groups"].append(spec_group)
# 处理SKU映射
for sku in spec_data.get("skuList", []):
sku_id = sku.get("skuId", "")
if not sku_id:
continue
# 规格路径
spec_path = []
for path in sku.get("specPath", "").split(";"):
if ":" in path:
_, value = path.split(":", 1)
spec_path.append(value)
result["sku_mapping"][sku_id] = {
"spec_path": spec_path,
"price": sku.get("price", ""),
"stock": sku.get("stock", 0),
"img_url": sku.get("imgUrl", "")
}
return result
def get_sku_by_spec(self, sku_mapping, spec_combination):
"""根据规格组合获取SKU"""
if not sku_mapping or not spec_combination:
return None
# 遍历SKU映射查找匹配项
for sku_id, sku_info in sku_mapping.items():
if self._match_spec(sku_info["spec_path"], spec_combination):
return {
"sku_id": sku_id,
"price": sku_info["price"],
"stock": sku_info["stock"],
"img_url": sku_info["img_url"]
}
return None
def _match_spec(self, sku_specs, target_specs):
"""匹配规格组合"""
if len(sku_specs) != len(target_specs):
return False
# 检查所有规格是否匹配
for s1, s2 in zip(sku_specs, target_specs):
if s1 != s2:
return False
return True
三、完整商品详情服务封装
整合上述组件,实现完整的商品详情获取服务:
python
运行
class JdProductDetailService:
"""京东商品详情服务"""
def __init__(self, proxy_pool=None):
self.sku_parser = JdSkuIdParser() # 复用之前实现的SKU解析器
self.params_generator = JdDetailParamsGenerator()
self.requester = JdDetailRequester(proxy_pool=proxy_pool)
self.parser = JdDetailParser()
self.spec_processor = JdSkuSpecificationProcessor()
def get_product_detail(self, product_url):
"""
获取商品完整详情
:param product_url: 商品详情页URL
:return: 完整的商品详情字典
"""
# 1. 获取商品SKU ID
print("解析商品SKU ID...")
sku_id = self.sku_parser.get_sku_id(product_url)
if not sku_id:
print("无法获取商品SKU ID")
return None
print(f"商品SKU ID: {sku_id}")
# 2. 获取主详情数据
print("获取主详情数据...")
main_params = self.params_generator.generate_main_params(sku_id)
main_response = self.requester.fetch_main_detail(main_params)
if not main_response:
print("主详情数据获取失败")
return None
main_detail = self.parser.parse_main_detail(main_response)
if not main_detail:
print("主详情数据解析失败")
return None
# 3. 获取库存数据
print("获取库存数据...")
stock_params = self.params_generator.generate_stock_params(sku_id)
stock_response = self.requester.fetch_stock(stock_params)
stock = self.parser.parse_stock(stock_response) if stock_response else None
# 4. 获取价格数据
print("获取价格数据...")
price_params = self.params_generator.generate_price_params(sku_id)
price_response = self.requester.fetch_price(price_params)
price = self.parser.parse_price(price_response) if price_response else None
# 5. 获取规格数据
print("获取规格数据...")
# 先获取商品详情页HTML
html_response = self.requester.session.get(
product_url,
headers=self.requester._get_headers(),
timeout=15
)
specifications = self.spec_processor.parse_specifications(html_response.text)
# 6. 合并所有数据
full_detail = self.parser.merge_details(main_detail, stock, price)
if full_detail and specifications:
full_detail["specifications"] = specifications
print("商品详情获取完成")
return full_detail
四、使用示例与数据存储
1. 基本使用示例
python
运行
def main():
# 代理池(实际使用时替换为有效代理)
proxy_pool = [
# "http://123.123.123.123:8080",
# "http://111.111.111.111:8888"
]
# 初始化商品详情服务
detail_service = JdProductDetailService(proxy_pool=proxy_pool)
# 商品详情页URL
product_url = "https://item.jd.com/100012345678.html" # 替换为实际商品URL
# 获取商品详情
product_detail = detail_service.get_product_detail(product_url)
# 处理结果
if product_detail:
print(f"n商品名称: {product_detail['name']}")
print(f"价格: {product_detail['price'].get('price', 0)}元")
print(f"是否有货: {'有货' if product_detail['stock'].get('has_stock', False) else '无货'}")
print(f"店铺: {product_detail['shop_name']} {'(自营)' if product_detail['is_self'] else ''}")
print(f"品牌: {product_detail['brand']}")
# 打印部分规格信息
if "specifications" in product_detail and product_detail["specifications"]["spec_groups"]:
print("n商品规格:")
for group in product_detail["specifications"]["spec_groups"][:2]: # 只显示前2个规格组
print(f"- {group['name']}: {', '.join([item['name'] for item in group['items'][:5]])}")
# 打印主要参数
if product_detail["params"]:
print("n主要参数:")
for i, (key, value) in enumerate(list(product_detail["params"].items())[:5]):
print(f"- {key}: {value}")
else:
print("商品详情获取失败")
if __name__ == "__main__":
main()
2. 详情数据存储工具
python
运行
import json
import csv
import pandas as pd
from pathlib import Path
from datetime import datetime
class JdDetailStorage:
"""京东商品详情存储工具"""
def __init__(self, storage_dir="./jd_product_details"):
self.storage_dir = Path(storage_dir)
self.storage_dir.mkdir(exist_ok=True, parents=True)
def save_to_json(self, product_detail):
"""保存为JSON格式(完整数据)"""
sku_id = product_detail.get("product_id", "unknown")
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"jd_detail_{sku_id}_{timestamp}.json"
file_path = self.storage_dir / filename
with open(file_path, "w", encoding="utf-8") as f:
json.dump(product_detail, f, ensure_ascii=False, indent=2, default=str)
print(f"完整详情已保存至JSON: {file_path}")
return file_path
def save_to_csv(self, product_detail):
"""保存为CSV格式(基础数据)"""
sku_id = product_detail.get("product_id", "unknown")
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"jd_detail_basic_{sku_id}_{timestamp}.csv"
file_path = self.storage_dir / filename
# 提取基础信息
basic_info = {
"product_id": product_detail.get("product_id", ""),
"name": product_detail.get("name", ""),
"brand": product_detail.get("brand", ""),
"price": product_detail.get("price", {}).get("price", 0),
"original_price": product_detail.get("price", {}).get("original_price", 0),
"shop_name": product_detail.get("shop_name", ""),
"shop_id": product_detail.get("shop_id", ""),
"is_self": product_detail.get("is_self", False),
"has_stock": product_detail.get("stock", {}).get("has_stock", False),
"stock_num": product_detail.get("stock", {}).get("stock_num", 0),
"categories": "/".join(product_detail.get("categories", [])),
"crawl_time": product_detail.get("crawl_time", "")
}
# 转换为DataFrame
df = pd.DataFrame([basic_info])
df.to_csv(file_path, index=False, encoding="utf-8-sig")
print(f"基础信息已保存至CSV: {file_path}")
return file_path
def save_specifications(self, product_detail):
"""单独保存规格数据"""
if "specifications" not in product_detail:
print("无规格数据可保存")
return None
sku_id = product_detail.get("product_id", "unknown")
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"jd_specs_{sku_id}_{timestamp}.json"
file_path = self.storage_dir / filename
with open(file_path, "w", encoding="utf-8") as f:
json.dump(product_detail["specifications"], f, ensure_ascii=False, indent=2)
print(f"规格数据已保存: {file_path}")
return file_path
五、合规优化与风险提示
1. 系统优化策略
多级缓存机制:实现内存缓存 + 文件缓存的多级缓存策略
python
运行
def get_cached_detail(self, sku_id, max_age=3600):
"""从缓存获取商品详情"""
# 先检查内存缓存
# 再检查文件缓存
# 缓存过期策略实现
return None
智能请求调度:根据商品重要程度和更新频率,动态调整抓取频率
异常重试机制:实现指数退避重试策略,提高成功率
2. 合规与风险提示
商业应用前必须获得京东平台书面授权,遵守《电子商务法》相关规定
不得将采集的商品数据用于生成与京东竞争的产品或服务
严格控制请求频率,避免对平台服务器造成负担
当检测到反爬机制加强时,应立即降低请求频率或暂停服务
尊重商品信息版权,不滥用采集的数据
通过本文提供的技术方案,可构建一套功能完善的京东商品详情接口系统。该方案实现了从多接口数据采集、解析到融合的全流程处理,支持商品基础信息、价格、库存和规格等多维度数据的获取,为电商数据分析、比价系统等场景提供技术支持。在实际应用中,需根据平台规则动态调整策略,确保系统的稳定性和合法性。
?审核编辑 黄宇
-
API
+关注
关注
2文章
1807浏览量
64851 -
京东
+关注
关注
2文章
1041浏览量
49487
发布评论请先 登录
京东:利用商品管理API自动调整商品上下架状态,优化搜索排名

淘宝/天猫:通过商品详情API实现多店铺商品信息批量同步,确保价格、库存实时更新
eBay 商品详情 API 深度解析:从基础信息到变体数据获取全方案
借助京东 API,京东店铺商品质量反馈快速收集
揭秘京东 API,让京东店铺商品推荐更懂用户
用淘宝 API 实现天猫店铺商品详情页智能优化
淘宝 API 接口:海量商品数据挖掘的宝藏钥匙
电商 API 接口:开启全平台商品信息同步新时代
产品详情查询API接口





 工商网监
工商网监
评论