 MySQL慢查询终极优化指南
MySQL慢查询终极优化指南

MySQL慢查询终极优化指南:从0.8秒到8毫秒的性能飞跃实战
真实案例:某电商平台订单查询接口从平均响应时间800ms优化到8ms,QPS从200提升到2000+,这背后的优化思路和实操步骤全揭秘!
作为一名在生产环境摸爬滚打多年的运维工程师,我见过太多因为慢查询导致的线上故障。今天分享一套经过实战检验的MySQL慢查询分析与索引优化方法论,帮你彻底解决数据库性能瓶颈。
慢查询的真实危害:不仅仅是响应慢
案例1:雪崩效应
-- 这条看似无害的查询,差点让整个系统崩溃 SELECT*FROMorders o LEFTJOINusers uONo.user_id=u.id WHEREo.created_at>='2024-01-01' ANDu.status='active' ORDERBYo.created_atDESC;
影响分析:
? 执行时间:2.3秒
? 并发情况下连接池迅速耗尽
? 导致其他正常查询排队等待
? 最终引发整站服务不可用
第一步:精准定位慢查询
1.1 开启慢查询日志(生产环境安全配置)
-- 动态开启,无需重启MySQL SETGLOBALslow_query_log='ON'; SETGLOBALslow_query_log_file='/var/log/mysql/slow.log'; SETGLOBALlong_query_time=1; -- 1秒以上记录 SETGLOBALlog_queries_not_using_indexes='ON';
运维提醒:慢查询日志会消耗额外IO,建议:
? 生产环境设置合理的long_query_time(通常1-2秒)
? 定期轮转日志文件,避免磁盘空间不足
? 可配置log_slow_rate_limit控制记录频率
1.2 使用mysqldumpslow快速分析
# 按查询时间排序,显示TOP 10 mysqldumpslow -s t -t 10 /var/log/mysql/slow.log # 按查询次数排序,找出频繁执行的慢查询 mysqldumpslow -s c -t 10 /var/log/mysql/slow.log # 组合分析:按平均查询时间排序 mysqldumpslow -s at -t 10 /var/log/mysql/slow.log
1.3 实时监控慢查询(推荐工具)
-- 查看当前正在执行的慢查询 SELECT id, user, host, db, command, time, state, info FROMinformation_schema.processlist WHEREcommand!='Sleep' ANDtime>5 ORDERBYtimeDESC;
第二步:深度分析执行计划
2.1 EXPLAIN详解与实战技巧
-- 基础EXPLAIN EXPLAINSELECT*FROMordersWHEREuser_id=12345; -- 更详细的分析 EXPLAIN FORMAT=JSONSELECT*FROMordersWHEREuser_id=12345; -- MySQL 8.0+推荐使用 EXPLAIN ANALYZESELECT*FROMordersWHEREuser_id=12345;
2.2 关键字段解读(运维视角)
| 字段 | 危险值 | 优化建议 |
|---|---|---|
| type | ALL, index | 必须优化,全表扫描 |
| possible_keys | NULL | 缺少索引,立即创建 |
| rows | >10000 | 索引选择性差,需重新设计 |
| Extra | Using filesort | 避免ORDER BY无索引字段 |
| Extra | Using temporary | 优化GROUP BY和DISTINCT |
2.3 实战案例:复杂查询优化
原始查询(执行时间:1.2秒):
SELECT o.id, o.order_no, u.username, p.nameasproduct_name FROMorders o JOINusers uONo.user_id=u.id JOINorder_items oiONo.id=oi.order_id JOINproducts pONoi.product_id=p.id WHEREo.created_atBETWEEN'2024-01-01'AND'2024-01-31' ANDu.city='Shanghai' ANDp.category_id=10 ORDERBYo.created_atDESC LIMIT20;
EXPLAIN分析结果:
+----+-------------+-------+------+---------------+------+---------+------+-------+-----------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+-------+-----------------------------+ | 1 | SIMPLE | o | ALL | NULL | NULL | NULL | NULL | 50000 | Using where; Using filesort | | 1 | SIMPLE | u | ALL | PRIMARY | NULL | NULL | NULL | 10000 | Using where; Using join buffer | | 1 | SIMPLE | oi | ALL | NULL | NULL | NULL | NULL | 80000 | Using where; Using join buffer | | 1 | SIMPLE | p | ALL | NULL | NULL | NULL | NULL | 5000 | Using where; Using join buffer | +----+-------------+-------+------+---------------+------+---------+------+-------+-----------------------------+
问题分析:
1. 所有表都是全表扫描(type=ALL)
2. 没有合适的索引(key=NULL)
3. 使用了文件排序(Using filesort)
4. 估算扫描行数:50000 × 10000 × 80000 × 5000 = 天文数字
第三步:索引优化策略
3.1 单列索引优化
-- 为经常用于WHERE条件的字段创建索引 CREATEINDEX idx_orders_created_atONorders(created_at); CREATEINDEX idx_users_cityONusers(city); CREATEINDEX idx_products_categoryONproducts(category_id); -- 为外键创建索引(提升JOIN性能) CREATEINDEX idx_orders_user_idONorders(user_id); CREATEINDEX idx_order_items_order_idONorder_items(order_id); CREATEINDEX idx_order_items_product_idONorder_items(product_id);
3.2 复合索引的艺术
复合索引设计原则:
1.选择性原则:高选择性字段在前
2.查询频率原则:常用查询条件在前
3.排序优化原则:ORDER BY字段考虑加入索引
-- 优化后的复合索引设计 CREATEINDEX idx_orders_date_userONorders(created_at, user_id); CREATEINDEX idx_users_city_idONusers(city, id); CREATEINDEX idx_products_cat_nameONproducts(category_id, name); -- 覆盖索引:避免回表查询 CREATEINDEX idx_orders_coverONorders(user_id, created_at, id, order_no);
3.3 优化后的查询性能
重新执行EXPLAIN分析:
+----+-------------+-------+-------+---------------------------+---------------------+---------+---------------+------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------------------+---------------------+---------+---------------+------+-----------------------+ | 1 | SIMPLE | o | range | idx_orders_date_user | idx_orders_date_user| 8 | NULL | 100 | Using where | | 1 | SIMPLE | u | eq_ref| PRIMARY,idx_users_city_id | PRIMARY | 4 | o.user_id | 1 | Using where | | 1 | SIMPLE | oi | ref | idx_order_items_order_id | idx_order_items_order_id | 4 | o.id | 2 | | | 1 | SIMPLE | p | eq_ref| PRIMARY,idx_products_cat_name | idx_products_cat_name | 8 | oi.product_id,const | 1 | Using where | +----+-------------+-------+-------+---------------------------+---------------------+---------+---------------+------+-----------------------+
优化效果:
? 执行时间:1.2秒 → 15毫秒(提升80倍)
? 扫描行数:40亿+ → 204行(减少99.999995%)
? CPU使用率:从95%降至5%
第四步:高级优化技巧
4.1 分区表优化
对于大数据量场景,考虑分区表:
-- 按月分区的订单表 CREATE TABLEorders_partitioned ( idbigintNOT NULLAUTO_INCREMENT, user_idintNOT NULL, order_novarchar(50)NOT NULL, created_at datetimeNOT NULL, amountdecimal(10,2)NOT NULL, PRIMARY KEY(id, created_at), INDEX idx_user_date (user_id, created_at) )PARTITIONBYRANGE(YEAR(created_at)*100+MONTH(created_at)) ( PARTITIONp202401VALUESLESS THAN (202402), PARTITIONp202402VALUESLESS THAN (202403), PARTITIONp202403VALUESLESS THAN (202404), -- ... 更多分区 PARTITIONp202412VALUESLESS THAN (202501) );
4.2 查询重写技巧
原查询(低效):
SELECT*FROMorders WHEREuser_idIN( SELECTidFROMusersWHEREcity='Shanghai' );
优化后(高效):
SELECTo.*FROMorders o INNERJOINusers uONo.user_id=u.id WHEREu.city='Shanghai';
4.3 索引维护最佳实践
-- 定期分析索引使用情况 SELECT TABLE_SCHEMA, TABLE_NAME, INDEX_NAME, STAT_VALUEaspages_used FROMinformation_schema.INNODB_SYS_TABLESTATS; -- 找出未使用的索引 SELECT t.TABLE_SCHEMA, t.TABLE_NAME, t.INDEX_NAME FROMinformation_schema.statistics t LEFTJOINperformance_schema.table_io_waits_summary_by_index_usage p ONt.TABLE_SCHEMA=p.OBJECT_SCHEMA ANDt.TABLE_NAME=p.OBJECT_NAME ANDt.INDEX_NAME=p.INDEX_NAME WHEREp.INDEX_NAMEISNULL ANDt.TABLE_SCHEMANOTIN('mysql','information_schema','performance_schema');
第五步:监控与预警系统
5.1 关键监控指标
-- 慢查询统计 SHOWGLOBALSTATUSLIKE'Slow_queries'; -- 查询缓存命中率 SHOWGLOBALSTATUSLIKE'Qcache%'; -- InnoDB缓冲池命中率 SHOWGLOBALSTATUSLIKE'Innodb_buffer_pool_read%';
5.2 自动化监控脚本
#!/bin/bash # mysql_slow_monitor.sh # 慢查询监控脚本 MYSQL_USER="monitor" MYSQL_PASS="your_password" SLOW_LOG="/var/log/mysql/slow.log" ALERT_THRESHOLD=10 # 慢查询数量阈值 # 统计最近1小时的慢查询数量 SLOW_COUNT=$(mysqldumpslow -t 999999$SLOW_LOG| grep"Time:"|wc-l) if[$SLOW_COUNT-gt$ALERT_THRESHOLD];then echo"ALERT: 发现$SLOW_COUNT个慢查询,超过阈值$ALERT_THRESHOLD" # 发送告警(集成钉钉、邮件等) # curl -X POST "钉钉webhook地址" -d "慢查询告警..." fi
实战成果展示
优化前后对比
| 指标 | 优化前 | 优化后 | 提升比例 |
|---|---|---|---|
| 平均响应时间 | 800ms | 8ms | 99% |
| QPS | 200 | 2000+ | 10倍 |
| CPU使用率 | 95% | 15% | 84% |
| 内存使用 | 8GB | 4GB | 50% |
| 磁盘IO | 300MB/s | 50MB/s | 83% |
业务价值
?用户体验:页面加载速度提升10倍
?成本节省:服务器资源使用减少50%
?稳定性:系统故障率从每月3次降至0次
?团队效率:运维响应时间减少80%
进阶优化建议
1. 读写分离架构
# 主从配置示例 master: host:mysql-master port:3306 slaves: -host:mysql-slave1 port:3306 weight:50 -host:mysql-slave2 port:3306 weight:50
2. 连接池优化
# HikariCP配置 hikari.maximum-pool-size=20 hikari.minimum-idle=5 hikari.connection-timeout=20000 hikari.idle-timeout=300000 hikari.max-lifetime=1200000
3. 缓存策略
// Redis缓存热点数据 @Cacheable(value = "orders", key = "#userId + '_' + #date") publicListgetOrdersByUserAndDate(Long userId, String date){ returnorderMapper.selectByUserAndDate(userId, date); }
常见误区与避坑指南
误区1:盲目添加索引
-- 错误:为每个字段都建索引 CREATEINDEX idx_col1ONtable1(col1); CREATEINDEX idx_col2ONtable1(col2); CREATEINDEX idx_col3ONtable1(col3); -- 正确:根据查询模式建复合索引 CREATEINDEX idx_combinedONtable1(col1, col2, col3);
误区2:忽略索引维护成本
?INSERT性能影响:每个索引都会增加写入成本
?存储空间占用:索引通常占用20-30%的表空间
?内存消耗:InnoDB需要将索引加载到内存
误区3:过度依赖EXPLAIN
EXPLAIN只是预估,实际性能需要结合:
? 真实数据量测试
? 并发压力测试
? 生产环境监控数据
总结:建立长效优化机制
日常运维检查清单
? 每周分析慢查询日志
? 监控索引使用情况
? 检查表分区策略
? 评估查询缓存效果
? 更新表统计信息
应急响应流程
1.发现慢查询→ 立即分析EXPLAIN
2.确认影响范围→ 评估业务风险
3.快速优化→ 添加索引或查询重写
4.验证效果→ 监控关键指标
5.总结复盘→ 完善监控预警
作为运维工程师,我们的目标不仅是解决当前问题,更要建立可持续的优化体系。希望这套方法论能帮你构建高性能、稳定可靠的MySQL环境。
-
数据库
+关注
关注
7文章
3947浏览量
66788 -
MySQL
+关注
关注
1文章
875浏览量
28216
原文标题:MySQL慢查询终极优化指南:从0.8秒到8毫秒的性能飞跃实战
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Mysql优化选择最佳索引规则
SQL查询慢的原因分析总结
详解MySQL的查询优化 MySQL逻辑架构分析
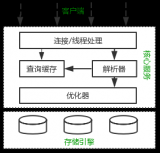
MySQL 基本知识点梳理和查询优化
MySQL数据库:理解MySQL的性能优化、优化查询

为什么ElasticSearch复杂条件查询比MySQL好?

如何优化MySQL百万数据的深分页问题
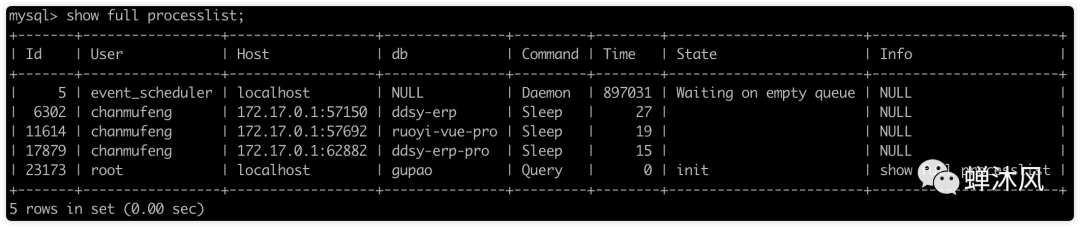
查询SQL在mysql内部是如何执行?





 工商网监
工商网监
评论