 进迭时空 V8 RISC-V 后端优化
进迭时空 V8 RISC-V 后端优化

前 言
V8 是 Google 开发及开源的 JavaScript 和 WebAssembly 语言编译引擎,是 Chromium 项目的一部分,主要应用于 Chrome 浏览器 和 Node.js 等项目,在浏览器生态中发挥着至关重要的作用。自 2020 年起,中科院软件所 PLCT 实验室等团队开始为 V8 引擎开发 RISC-V 后端,并持续推动 V8 对 RISC-V 架构的支持,不断完善功能完整性,持续优化性能表现。目前,V8 引擎的 RISC-V 后端已经完成了解释器和 JIT 编译器的开发,实现了基本功能的完整支持。全球 RISC-V 生态共建者正在积极推动更多高级特性的开发与完善,持续优化 V8 在 RISC-V 平台上的性能与兼容性。
RISC-V 作为新兴的架构,其后端仍有不少优化机会。本文将介绍一些进迭时空在 V8 JavaScript 引擎 RISC-V 后端的优化工作,并说明这些优化如何提升 JavaScript 在 RISC-V 架构上的执行效率和整体性能表现。
R I S C - V 后 端 优 化
Load/Store 地址计算优化
V8 的 LoadStoreSimplificationReducer Pass 会将 LoadOp(Load Operation)和 StoreOp(Store Operation)的地址计算规约为 Base + Index 的形式,Base 表示基地址,Index 表示索引偏移,比如指令 ld t3, 8(t1) 中 Base 为 t1,Index 为 8,加载地址为 t1 + 8。
·使用 Shift And Add 指令计算 Base
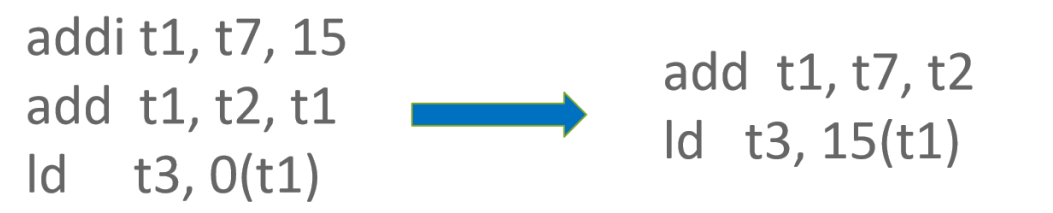
RISC-V Zba Extension 提供了 shift and add 系列指令来快速完成地址计算,使用该系列指令可在地址计算过程省去 1 条指令。以如下代码为例,在计算 Base 过程中使用了 slli + add 来完成对 Base 的计算,可被 shift and add 指令替换。

·Index 立即数参数融合进 Load/Store 指令
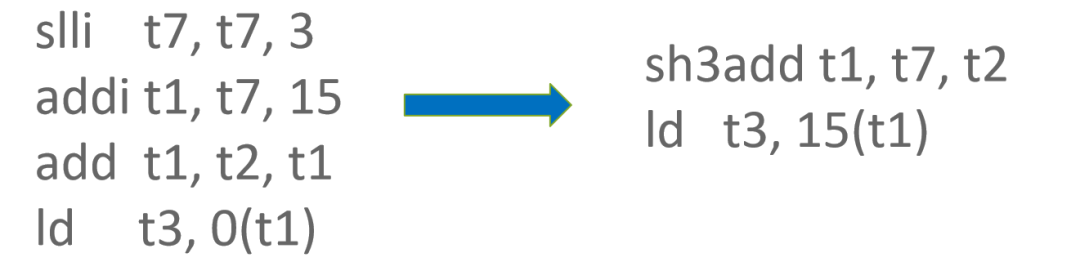
有时候 Index 并不一定是立即数,而是一个通过 WordBinopOp::Add 节点计算得到的寄存器值,并且该 WordBinopOp::Add 节点的参数中存在符合 RISC-V Load/Store 指令索引偏移范围 [-2048, 2047] 的立即数,则可以将 Index 中的立即数参数融合进 Load/Store 指令中,从而节省 1 条指令。
更进一步地,如果上述两种优化方法的条件都符合,则可以同时使用两种优化方法,从而节省 2 条指令。
Comparison + Branch 优化
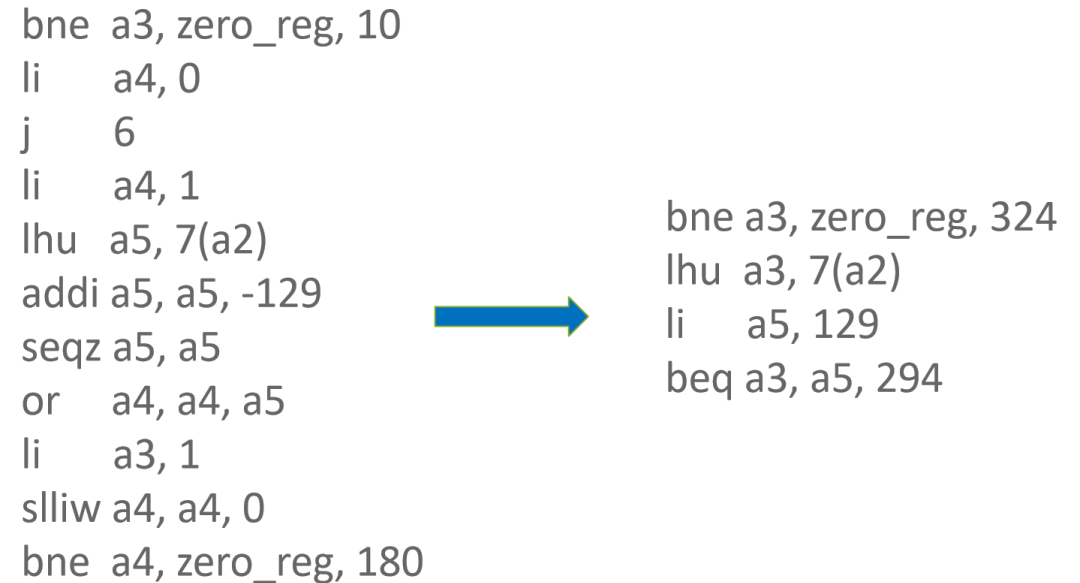
Comparison + Branch 一般位于 BasicBlock 结束处,用于条件分支跳转。
MERGEB3<-?B2,B1? 21:Phi(#16,#19)[Tagged]? 22:Constant()[heap?object:?0x00ec00000011?? 23:Comparison(#4,#22)[Equal, Tagged]? 24:Branch(#23)[B319,B4,False]
如果 ComparisonOp 的 RegisterRepresentation 是 Tagged 类型,则可以将 Tagged 类型映射为 Word32 或者 Word64 类型,如此便可在对 Branch 节点做指令选择时,选择 kRiscvCmp 虚拟指令而不是选择 kRiscvCmpZero 虚拟指令,同时会将 ComparisonOp 的参数和 FlagsCondition(表示判断条件)融合进 kRiscvCmp 虚拟指令中。因此 ComparisonOp 节点计算结果不再被直接使用,所以不会对 ComparisonOp 生成指令,从而达到节省指令的目的。
原来使用 kRiscvCmpZero 节点时,需要使用 xor + slt 指令来计算 ComparisonOp 的结果然后再传给 Branch 指令。切换为 kRiscvCmp 节点后,可以将 ComparisonOp 操作融合进 Branch 指令中,从而省去 xor 和 slt 指令。

Load + ChangeUint32ToUint64 优化
在 Load + ChangeUint32ToUint64 匹配模式下,ChangeUint32ToUint64 用于将 LoadOp 加载出来的 uint32 类型数据转化为 uint64 类型。
但当 LoadOp 需要加载的数据其符号类型为 unsigned,MachineRepresentation 类型为 Word32 时,会选择 lwu 指令来进行加载,该指令加载数据时自身会进行零扩展,故不需要再额外使用 zext.w 指令来进行零扩展,从而省去 zext.w 指令。

IsNumeric 优化
IsNumeric(value) 用于判断给定的 JavaScript 值是否是一个 Number 类型或 BigInt 类型:
Number:表示浮点数和整数(如 42,3.14)
BigInt:表示任意精度的大整数(如 123456789012345678901234567890n)
在 IsNumberic 函数实现中,需要对 IsHeapNumber 和 IsBigInt 函数返回值进行 or 运算,而因为 IsBigInt 函数需要数条指令完成,所以如果 IsHeapNumber 返回值为 1,则两者 or 运算的结果可以直接用 1 来表示,避免通过 IsBigInt 函数引入较多的指令。
同理,IsSharedStringInstanceType 函数也可以照此修改优化。
DecompressTagged 优化
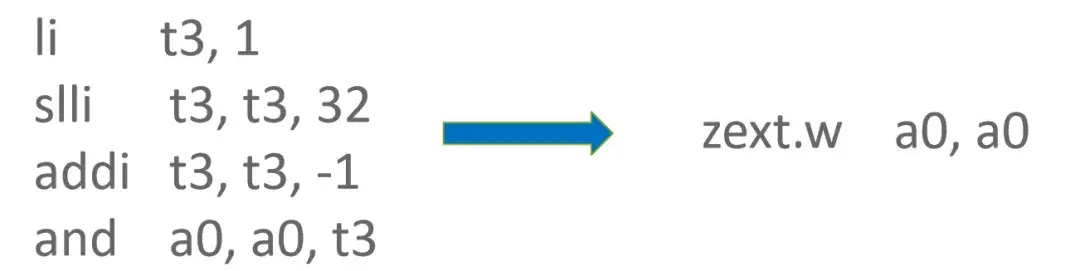
RISC-V Zba Extension 中提供了 zext.w 伪指令可用于零扩展。当使能 V8 Compress pointer 机制时,需要通过DecompressTagged 函数对 Tagged 类型数据进行解压缩。DecompressTagged 函数实现中,存在对 source register 上的数据执行 And 0xFFFFFFFF 的操作,而 0xFFFFFFFF 需要使用 3 条 RISC-V 基础指令来构造。当存在 RISC-V Zba Extension 时,可以使用 zext.w 指令来替换 And 0xFFFFFFFF 操作,从而节省 3 条指令。
AssembleReturn 优化
V8 中 AssembleReturn 用于对 ArchRet 节点生成指令,当符合下列条件时:
frame_access_state()->has_frame(),即表示当前是否正在使用栈帧。
call_descriptor->IsJSFunctionCall(),即表示当前是否为 JavaScript 函数调用。
parameter_slots != 0,即表示当前被调用函数的函数定义中参数数量不为 0
则需要将 JavaScript 函数参数从栈帧中移出。因实际传入参数的数量和函数定义中参数的数量不一定相同,因此需要取两者之中较大值来进行栈帧调整。
RISC-V Zbb Extension 提供了 max 指令来获取两个参数的较大值,既减少 1 条指令,又能避免产生分支指令导致分支预测失败时需要清空流水线。
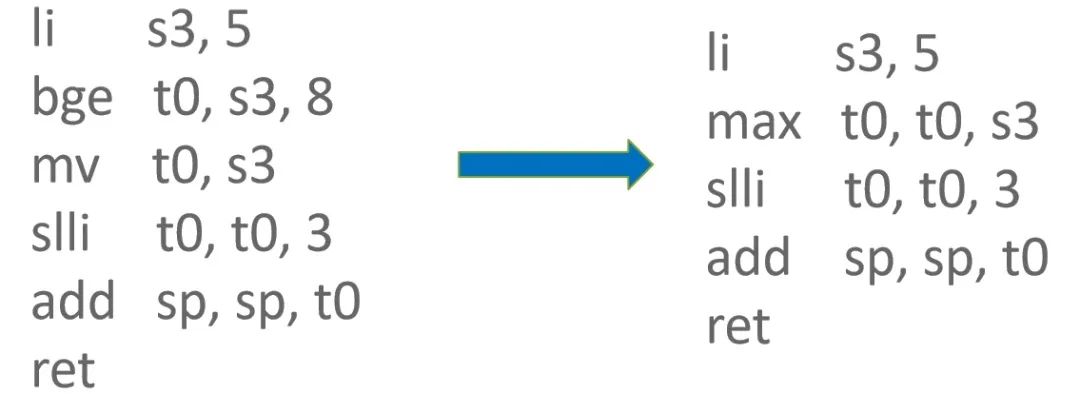
TaggedIsSmi 优化
在 V8 中,为了提高性能和减少内存使用,小整数被直接编码到 Tagged 类型值中,这种编码方式使得小整数无需分配额外的内存即可存储,并且可以直接在寄存器中传递,从而提高了运算速度。
TaggedIsSmi 函数用于判断 Tagged 类型值是否为 Smi(Small Integer)数据,在 V8 中属于高频使用函数。对于 Smi 类型,最低位通常设置为 0;而对于指向堆对象的 Tagged 类型值,最低位则设置为 1。TaggedIsSmi 源码如下:
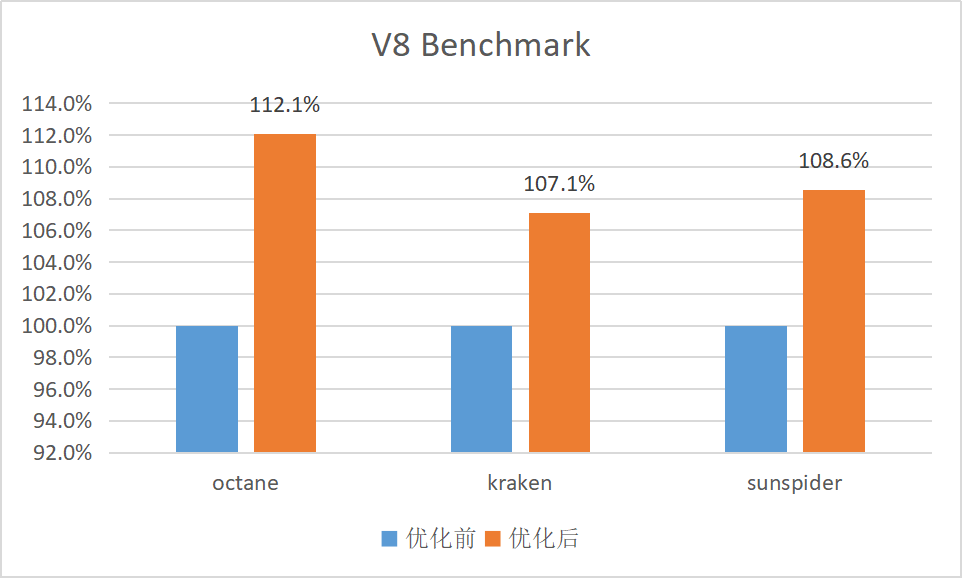
TNode 对应的 IR 节点则如下图所示: 25:TaggedBitcast(#0)[Compressed, Word32, TagAndsmiBits]26:Constant()[word32:1]27:Change(#25)[Truncate, NoAssumption, Word64, Word32]28:WordBinop(#27,#26)[BitwiseAnd,Word32]29:Branch(#28)[B5,B4,None] 此处的 BitwiseAnd 运算是与常数 1 进行 And 运算,必然是在 Word32 数据表示范围内,故并不需要进行扩展操作。经过优化后,TaggedIsSmi 函数生成的指令序列可节省 2 条指令。 SwitchTable 二分查找优化 AssembleArchBinarySearchSwitch 是用于为 switch-case 语句(特别是 case 值为整数时)生成高效汇编代码的方法。它通过使用二分查找算法来优化 switch-case 结构的执行效率,从而减少条件分支的数量,提高性能。当使能 Compress pointer 时,会在二分查找比较时将输入值进行符号扩展操作,然而实际上,输入值在整个二分查找阶段并不会发生变化,可以对其做循环不变量提升,减少符号扩展操作的数量。 CompareTaggedAndBranch 优化 CompareTaggedAndBranch 是用于比较两个值,并根据比较结果执行条件跳转的函数。当使能 Compress pointer 时,两个值需要进行符号扩展之后才能比较。但是如果一个参数为立即数并在 [0, 0x7FFFFFFF] 范围内,实际上并不需要进行符号扩展。 性 能 测 试 经过进迭时空的多项优化,包括但不限于上述改进,V8 基准性能测试的各项指标均取得了不同程度的提升。 结 束 语 秉承着以 RISC-V 架构数智未来的使命,进迭时空将持续关注和支持 RISC-V 生态的发展,下一步会陆续将优化成果向 V8 开源社区贡献,并与开源社区伙伴一起继续努力,共建 RISC-V 生态。


-
开源
+关注
关注
3文章
3754浏览量
43968 -
RISC-V
+关注
关注
46文章
2608浏览量
49032 -
进迭时空
+关注
关注
0文章
33浏览量
158
发布评论请先 登录
2025RISC-V中国峰会|进迭时空RISC-V AI CPU驱动智能化应用发展

迎接泛机器人时代:进迭时空如何以RISC-V架构数智未来
RISC-V架构下的编译器自动向量化
大象机器人携手进迭时空推出 RISC-V 全栈开源六轴机械臂产品
进迭时空携手珠海共建RISC-V生态应用中心
高校赛事 | 进迭时空携手蓝桥杯,诚邀全国高校学子共启RISC-V人工智能应用创新赛道
大象机器人携手进迭时空推出 RISC-V 全栈开源六轴机械臂产品
大象机器人×进迭时空联合发布全球首款RISC-V全栈开源小六轴机械臂

香蕉派 BPI-CM6 工业级核心板采用进迭时空K1 8核 RISC-V 芯片开发
RISC-V+OpenHarmony5.0:进迭时空与中科院共筑数字世界新基石
进迭时空完成A+轮数亿元融资 加速RISC-V AI CPU产品迭代
进迭时空亮相RISC-V产业发展大会:新AI CPU引领大模型时代

Banana Pi BPI-F3 进迭时空RISC-V架构下,AI融合算力及其软件栈实践
RISC-V架构下DSA-AI算力的更多可能性:Banana Pi BPI-F3进迭时空
RT-Thread携手进迭时空:共建RISC-V实时计算生态






 工商网监
工商网监
评论