 自动驾驶为什么需要NPU?GPU不够吗?
自动驾驶为什么需要NPU?GPU不够吗?

纯GPU能做自动驾驶吗?
[首发于智驾最前沿微信公众号]从技术上来说,纯GPU可以实现一定程度的自动驾驶,但存在明显短板,难以满足高级别自动驾驶的需求。
GPU能够处理自动驾驶所需的并行计算任务(如传感器数据融合、图像识别等),但其设计初衷是图形渲染,存在以下局限性:
能效比低:GPU的通用计算单元在处理AI任务时功耗较高,不适合车载电池供电场景。
实时性挑战:自动驾驶需毫秒级响应,GPU的通用架构可能导致延迟波动不确定。
成本高:高端GPU价格昂贵,且需额外散热设计。
早期一些自动驾驶测试车辆曾尝试使用纯GPU方案。比如某款基于英伟达GTX1080GPU的测试车,在处理单路摄像头数据时,目标检测延迟约80毫秒,而车辆以60公里/小时行驶时,80毫秒内会前进1.33米,这在突发状况下会带来安全隐患。
特斯拉早期也使用GPU(NVIDIA PX2),后转向自研NPU(FSD芯片)以优化能效。
在数据处理能力方面,L4级自动驾驶汽车每秒产生的数据量约5-10GB,纯GPU处理时,需要多颗GPU协同工作。某测试显示,用4颗英伟达TITAN X GPU处理8路摄像头和1路激光雷达数据,功耗达到320W,这会使电动汽车续航减少约30%。
另外,在运行复杂深度学习模型时,纯GPU的效率偏低。以ResNet-152模型为例,在GPU上处理一帧4K图像需要28毫秒,而同样的任务在专用NPU上只需8毫秒,差距明显。
所以,纯GPU可以实现低级别自动驾驶的基本功能,但在延迟、功耗和效率上的表现,难于满足L3及以上级别自动驾驶的要求,至少性价比不高。

GPU、NPU、TPU的根本原理对比
GPU最初是为图形渲染设计的,其核心是由大量流处理器组成的并行计算单元。以英伟达GTX 1080为例,有2560个流处理器,这些处理器以线程块为单位工作,支持浮点、整数等多种计算类型。
在处理图形数据时,GPU能同时对millions个像素进行计算,完成纹理映射、光照计算等操作。在深度学习中,它可以并行处理矩阵运算,但由于架构是通用设计,在执行神经网络计算时,有30%-40%的硬件资源处于闲置状态。
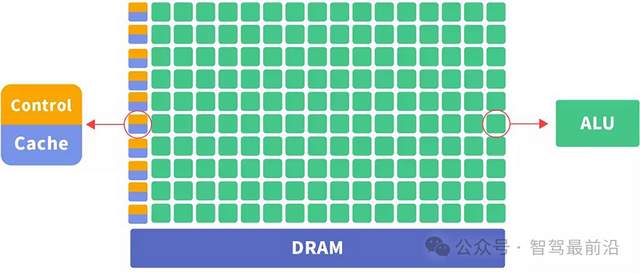
图 GPU架构图,来自网络
注意到GPU的控制单元control,如果不需要控制,是不是就可以降低很多能耗和闲置算力呢?答案是的。
NPU是专门为神经网络计算设计的芯片,内部集成了大量MAC(乘加单元)。比如华为昇腾310B,含有2048个MAC单元,这些单元以阵列形式排列,直接针对矩阵乘法和累加操作进行优化。
NPU采用数据流架构,数据在存储单元和计算单元之间的传输路径固定且简短。在处理卷积运算时,数据从缓存进入MAC阵列后,直接完成计算并输出结果,中间环节比GPU少60%以上。
TPU是谷歌为机器学习定制的芯片,采用脉动阵列架构。以TPU v2为例,其脉动阵列规模为512x512,数据进入阵列后,像脉搏一样在单元间流动,每个单元完成一次乘加操作后,将结果传递给下一个单元。
这种架构下,数据一旦进入阵列,就会在内部持续流转并完成计算,减少了外部存储访问次数。在处理大型矩阵乘法时,TPU的数据复用率比GPU高3倍以上。
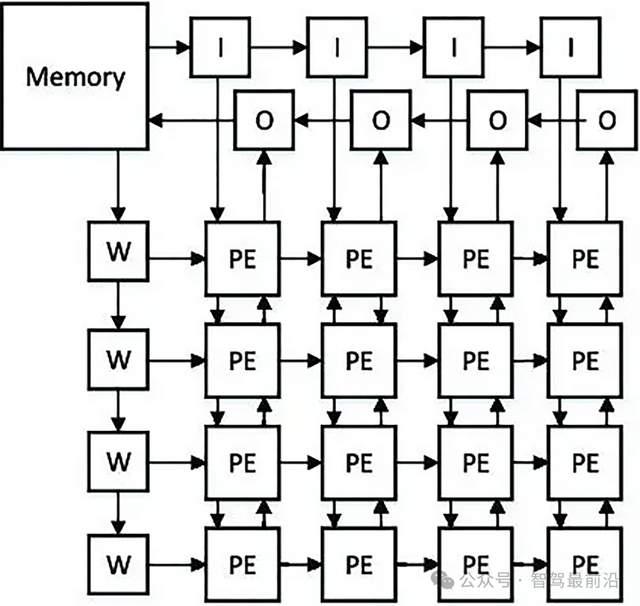
图 NPU和TPU共有的特点,计算单元阵列,来自网络
只不过TPU(脉动阵列就是谷歌为TPU提出来的)和部分NPU是脉动阵列,大部分NPU是MAC阵列。
脉动阵列是一种特殊的阵列结构,设计灵感源于人体血液循环系统。其核心概念是让数据在运算单元的阵列中流动,减少访存次数。整个阵列以“节拍”方式运行,每个处理单元(PE,Processing Element)在每个计算周期处理一部分数据,并将其传达给下一个互连的PE。以矩阵乘法为例,在4x4的脉动网中,参与运算的矩阵元素按照特定顺序在阵列单元间流动,每个单元完成一次乘加操作后,将结果传递给下一个单元,数据一旦进入阵列,就会在内部持续流转并完成计算。这种结构下,数据在阵列中像脉搏跳动一样流动,极大提升了数据复用率,减少了外部存储访问次数,在处理大型矩阵乘法时,其数据复用率比传统架构高3倍以上。例如谷歌的TPU采用脉动阵列架构,像TPUv2的脉动阵列规模为512x512,在执行大型矩阵乘法等运算时,能高效利用数据,减少数据在芯片内外搬运的开销。
MAC(乘加单元,Multiplier-Accumulator Unit)阵列则主要由大量乘加单元集成以阵列形式排列构成。乘加单元是完成一次乘法运算和一次加法运算的基本硬件单元。比如华为昇腾310B的NPU中,含有2048个MAC单元,这些单元针对神经网络计算中的矩阵乘法和累加操作进行了专门优化。在处理卷积运算时,数据从缓存进入MAC阵列,乘加单元对输入数据和权重数据进行乘加运算,直接完成计算并输出结果。MAC阵列通常采用数据流驱动架构,深度优化数据在存储单元与计算单元间的流转路径,通过硬件化的激活函数单元、池化单元等,直接加速神经网络关键操作,减少数据搬运次数,提升计算效率,中间环节相比传统通用架构减少60%以上。
脉动阵列和MAC阵列最主要的区别是控制时序。脉动阵列的控制时序具有严格的周期性,数据按固定节拍在单元间流动,每个处理单元的运算与数据传输精准同步,像脉搏跳动般有序;而MAC阵列的控制时序更灵活,各单元可相对独立地响应指令,无需严格遵循统一的数据流节拍,更侧重高效执行乘加操作。
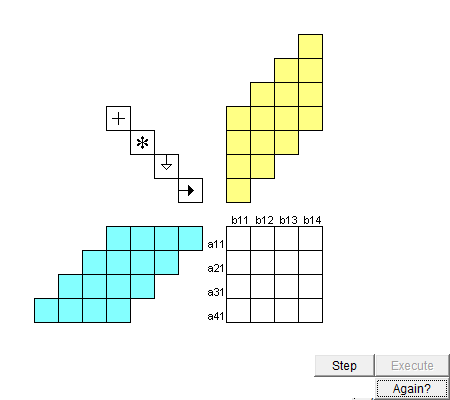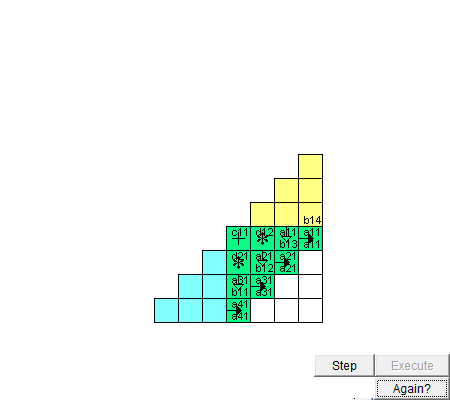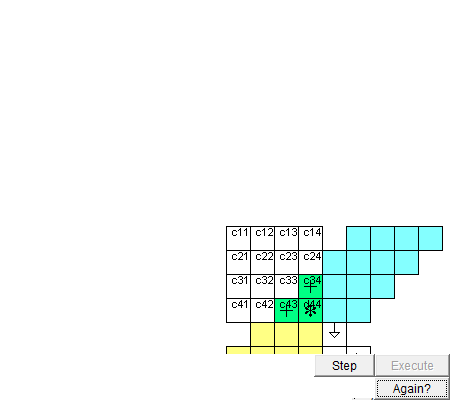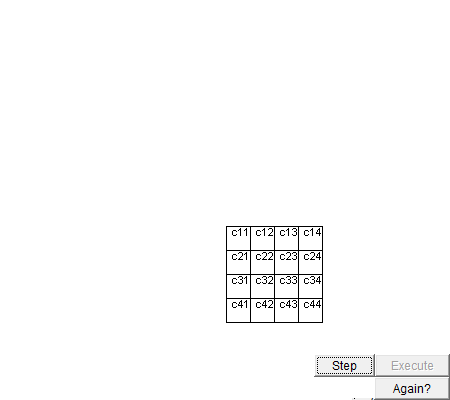
图 脉动阵列进矩阵乘法的动图,来自网络
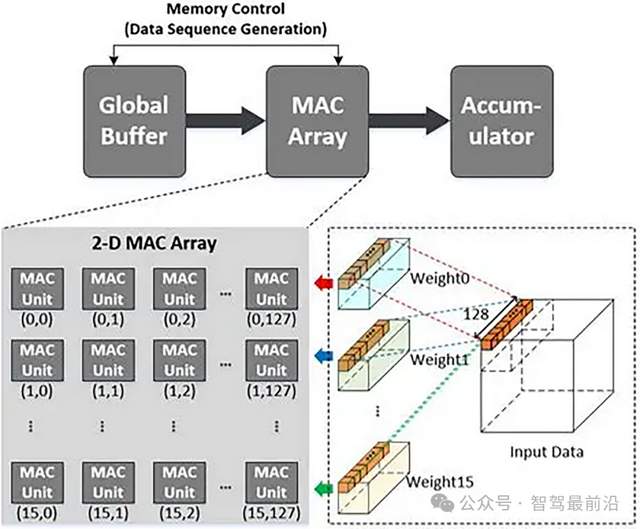
图 MAC单元阵列,来自网络
总结起来一句话,阵列形式的NPU和TPU,之所以在神经网络的推理计算上,比GPU更经济(响应时间,造价,能耗都更经济),就是因为阵列排列的简单计算单元,就在扮演神经网络的神经元,而它们之间联系的数据通路,就在扮演神经网络的权重。就像很多文章说的,NPU和TPU内部物理结构,就是在模拟神经网络的结构。
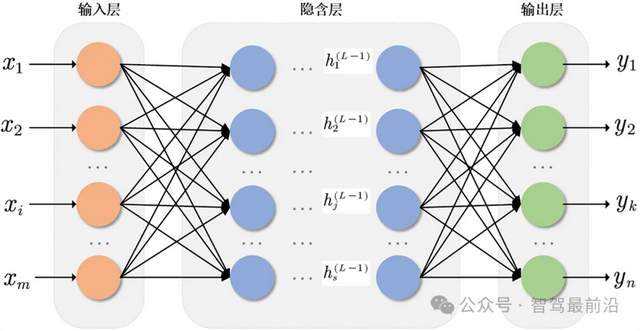
图 神经网络推理图,来自网络
相信很多读者会问两个问题。
第一、NPU如何处理比它的原生阵列更大的神经网络?
从硬件架构层面来看,NPU要处理比其阵列规模大的神经网络,确实面临诸多挑战,但并非完全不可行。NPU内部集成的MAC(乘加单元)阵列是其进行神经网络计算的核心组件,像华为昇腾310B的NPU就含有2048个MAC单元。这些单元以阵列形式排列,直接针对神经网络计算中的矩阵乘法和累加操作进行优化,在处理卷积运算等神经网络常见操作时,数据从缓存进入MAC阵列后,能直接完成计算并输出结果,中间环节比GPU等传统架构减少60%以上。
然而,如果神经网络的规模超出了MAC阵列的原生处理能力,例如在面对参数规模达到数十亿甚至上百亿的超大规模神经网络时,单个NPU的MAC阵列在一个计算周期内难以完成所有数据的并行处理。因为MAC阵列的规模限制了其同时处理的数据量,就好比一条车道有限的公路,车流量过大时就会拥堵。以某款面向智能安防的NPU为例,其MAC阵列设计用于处理中等规模的图像识别神经网络,当尝试运行一个专为超高清视频分析设计的大规模神经网络时,原本能实时处理的图像帧率从30帧/秒骤降至5帧/秒以下,延迟大幅增加,无法满足实际应用的实时性需求。
办法就是分帧,把大网络切成NPU一次能处理的小块,但是会有性能问题。
第二、要处理比它的原生阵列小,但形状不一致的神经网络怎么办?毕竟神经网络每一层的神经元数量都可以不一样。
答案是填充padding,空着的神经元和权重填充0(或者特殊的信号表示忽略)。目的是在乘加运算时不发生作用,因为乘0还是0,加0还是0,且没有别的计算。
TPU是类似的。
三者的对比表如下:
| 特性 | GPU | NPU | TPU |
| 设计目标 | 图形渲染/通用并行计算 | 神经网络推理与训练加速 | 张量运算(Google专用) |
| 核心架构 | 数千个SIMD核心(通用计算单元) | 专用矩阵运算单元(如MAC阵列) | 脉动阵列(数据流优化) |
| 优势 | 灵活性强,适合多样化任务 | 能效比高,低延迟推理 | 云端大规模训练性能优异 |
| 典型应用 | 游戏、科学计算、AI训练 | 自动驾驶、边缘AI、手机端侧推理 | Google Cloud AI服务 |
| 代表产品 | NVIDIA A100、AMD Radeon Instinct | 特斯拉FSD、华为昇腾 | Google TPU v4 |
原理差异:
lGPU:通过大规模并行线程处理浮点运算,但需软件层优化AI任务。
lNPU:硬件级支持矩阵乘加(MAC)操作,直接映射神经网络计算图。
lTPU:采用脉动阵列减少数据搬运开销,专为TensorFlow优化。
三者相比,GPU通用性强但针对性不足,NPU专注于神经网络计算效率,TPU在特定机器学习任务(针对tensorflow优化)上有更高的计算密度。
如果进一步讲,GPU更适合训练,因为模型训练时需要反向传播算法,计算需要从两个方向进行,变换计算方向是需要额外控制器的。但NPU(TPU)更适合对训练好的模型进行推理,推理只需要闷着头朝一个方向走就行了。
为什么thor要保留GPU,又有NPU
英伟达Thor是一款面向自动驾驶的计算芯片,其包含多种PU,是超异构融合芯片的典型。
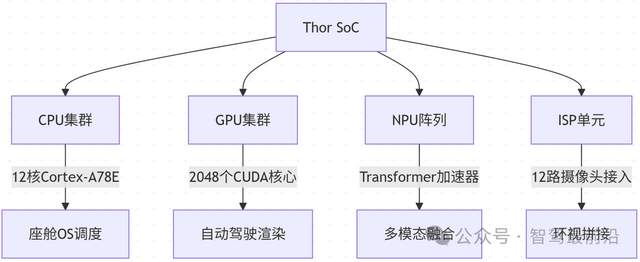
图 雷神索尔Thor芯片的框架和功能,其中ISP不是网络服务商,而是ImageSignalProcessor,图像信号处理器
它保留GPU同时配备NPU,主要有以下几方面原因。
从功能分工来看,自动驾驶系统中有不同类型的计算任务。NPU适合处理神经网络相关任务,比如用YOLOv8模型检测行人,Thor的NPU处理单帧图像耗时约5毫秒;而GPU则负责传感器数据预处理,比如将激光雷达的点云数据从极坐标转换为笛卡尔坐标,Thor的GPU处理100万个点云数据耗时约3毫秒。
在数据交互上,两者需要协同工作。摄像头采集的原始图像先由GPU进行畸变校正,校正后的图像再传给NPU进行目标识别。测试显示,这种协同模式比单一处理器处理的效率提升40%,因为避免了数据在不同芯片间的频繁传输。
另外,考虑到软件兼容性,目前有大量传统算法基于GPU开发,比如SLAM(同步定位与地图构建)中的部分模块。保留GPU可以直接运行这些算法,无需重新开发,节省了至少18个月的适配时间。
从成本角度,Thor的GPU和NPU集成在同一芯片上,相比分开设计,硬件成本降低25%,同时减少了50%的电路板空间占用。
GPU、NPU在能耗和造价的对比
在相同AI算力下,NPU的能耗明显低于GPU。
英伟达Jetson AGX Xavier(GPU方案)的AI算力为32TOPS,功耗30W,能效比1.07TOPS/W。华为昇腾310B(NPU方案)算力22TOPS,功耗8W,能效比2.75TOPS/W,是前者的2.5倍。
特斯拉FSD芯片中的NPU部分,算力144TOPS,功耗25W,能效比5.76TOPS/W。而要达到相近的AI算力,需要4颗Jetson AGX Xavier,总功耗120W,是特斯拉NPU的4.8倍。
在实际车载场景中,某L4级自动驾驶测试车采用纯GPU方案(总功耗150W),相比采用NPU+GPU混合方案(总功耗60W),每100公里多消耗8度电,按电动车百公里平均15度电计算,续航减少约53公里。
单颗芯片成本方面,英伟达Jetson AGX Xavier的批量采购价约800美元/颗,华为昇腾310B约300美元/颗。
若要实现144TOPS的AI算力,纯GPU方案需要5颗Jetson AGX Xavier,总成本4000美元;而采用特斯拉FSD芯片(含NPU),单颗成本约500美元,成本仅为纯GPU方案的12.5%。
加上周边电路和散热系统,纯GPU方案的硬件总成本约5500美元,NPU+GPU混合方案约1200美元,前者是后者的4.6倍。
从量产角度看,当产量达到10万台时,NPU的单位研发成本可分摊至每台30美元,而GPU由于架构复杂,分摊后仍需80美元/台。
| 指标 | GPU | NPU |
| 功耗 | 高(50-300W) | 极低(1-10W) |
| 单位TOPS功耗 | 1-5W/TOPS | 0.1-0.5W/TOPS |
| 造价 | 高(高端芯片超万元) | 中低(规模化后成本下降快) |
| 适用场景 | 训练/云端推理 | 端侧推理/车载实时处理 |
数据来源:NPU的能效比可达GPU的10倍以上,且制程要求更低(如14nmNPU媲美7nmGPU)
总结
纯GPU可以实现低级别自动驾驶,但在处理速度、能耗等方面存在明显不足,无法满足高级别自动驾驶的需求。
从原理上看,GPU通用但效率低,NPU专为神经网络设计,TPU在特定场景计算密度高,三者架构差异导致适用场景不同。
英伟达Thor同时保留GPU和NPU,是因为两者能分工协作,提高整体效率,还能兼容现有软件,降低成本。
能耗和造价数据显示,NPU的能效比是GPU的2.5-5倍以上,相同算力下,NPU方案的硬件成本仅为纯GPU方案的12.5%-40%。
综合来看,自动驾驶需要NPU,因为它能在低功耗下高效处理神经网络任务,而GPU虽然在部分通用计算上有作用,但单独使用无法满足高级别自动驾驶的要求。未来,NPU+GPU的混合方案会成为主流,既保证处理效率,又兼顾兼容性和成本。
审核编辑 黄宇
-
gpu
+关注
关注
28文章
4956浏览量
131440 -
自动驾驶
+关注
关注
790文章
14344浏览量
170873 -
NPU
+关注
关注
2文章
333浏览量
19807
发布评论请先 登录
卡车、矿车的自动驾驶和乘用车的自动驾驶在技术要求上有何不同?
Vicor高效电源模块优化自动驾驶系统
自动驾驶安全基石:ODD
新能源车软件单元测试深度解析:自动驾驶系统视角


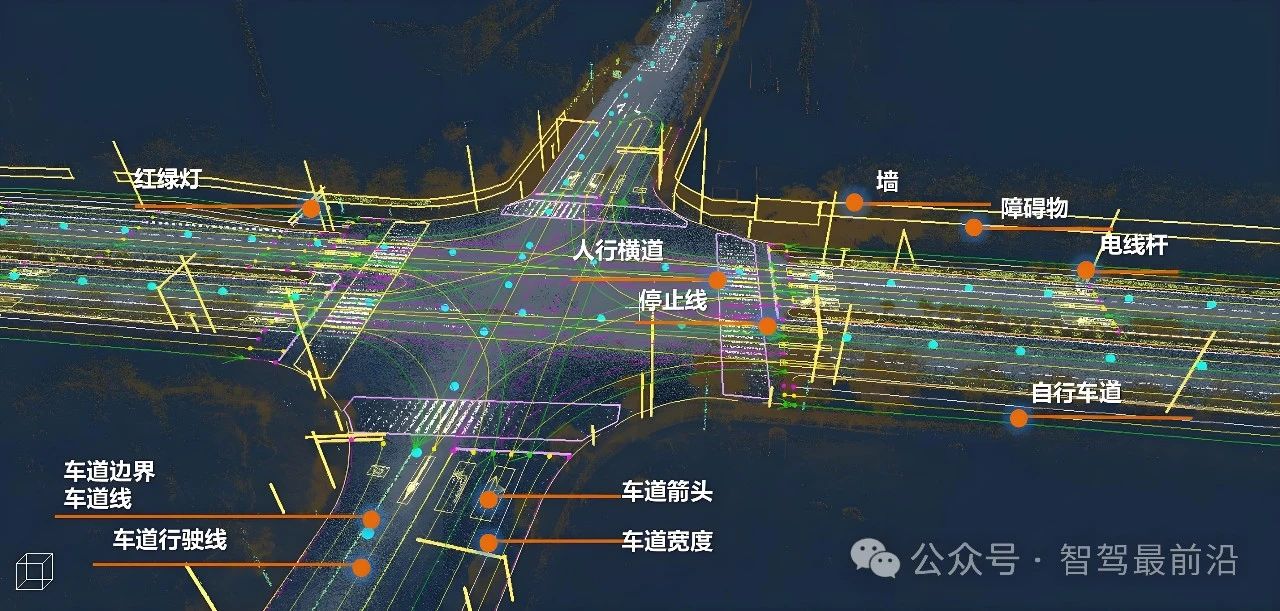
从《自动驾驶地图数据规范》聊高精地图在自动驾驶中的重要性
一文聊聊自动驾驶测试技术的挑战与创新

标贝科技:自动驾驶中的数据标注类别分享

标贝科技:自动驾驶中的数据标注类别分享

自动驾驶汽车安全吗?








 工商网监
工商网监
评论