 Ceph分布式存储系统解析
Ceph分布式存储系统解析

引言
在当今数据爆炸的时代,企业对存储系统的需求日益增长,传统的集中式存储已经无法满足大规模数据处理的要求。分布式存储系统应运而生,而Ceph作为开源分布式存储系统的佼佼者,以其高可用性、高扩展性和统一存储架构赢得了众多企业的青睐。
Ceph概述
Ceph是一个开源的分布式存储系统,由Sage Weil在加州大学圣克鲁斯分校开发,现已成为Linux基金会项目。它提供了对象存储、块存储和文件存储三种存储接口,能够在commodity硬件上运行,具有无单点故障、自动数据修复和智能数据分布等特性。
核心特性
高可用性:通过数据复制和分布式架构,确保系统在硬件故障时仍能正常工作。
高扩展性:支持从几个节点扩展到数千个节点的PB级存储集群。
统一存储:单一集群同时提供对象、块和文件存储服务。
自管理:具备自动故障检测、数据修复和负载均衡能力。
架构组件
Monitor(MON)
Monitor是Ceph集群的大脑,负责维护集群状态信息,包括Monitor Map、OSD Map、PG Map等。通常部署奇数个Monitor实例(3或5个)以避免脑裂问题。Monitor通过Paxos算法保证集群状态的一致性。
Object Storage Daemon(OSD)
OSD是Ceph的核心存储组件,每个OSD管理一个存储设备(通常是硬盘)。OSD负责存储数据、处理数据复制、恢复和重新平衡,以及向Monitor报告状态信息。一个典型的Ceph集群包含数十到数千个OSD。
Metadata Server(MDS)
MDS专门为CephFS文件系统服务,负责管理文件系统的元数据。对于对象存储和块存储,MDS不是必需的。MDS支持动态扩展和故障转移,确保元数据服务的高可用性。
Manager(MGR)
Manager是Ceph Luminous版本引入的新组件,负责收集集群指标、提供管理接口和扩展功能。MGR支持插件架构,可以集成各种监控和管理工具。
核心算法
CRUSH算法
CRUSH(Controlled Replication Under Scalable Hashing)是Ceph的核心数据分布算法。它通过确定性的哈希函数将数据映射到存储位置,无需维护中心化的映射表。CRUSH算法考虑了硬件层次结构,能够根据故障域进行智能的数据分布。
Placement Group(PG)
PG是Ceph中的逻辑概念,作为对象和OSD之间的中间层。每个PG包含多个对象,并被复制到多个OSD上。PG的数量需要根据OSD数量合理配置,通常建议每个OSD管理50-100个PG。
存储接口
RADOS块设备(RBD)
RBD提供块存储服务,支持快照、克隆和精简配置等企业级功能。RBD可以直接挂载到虚拟机或物理主机,广泛应用于云计算环境。
# 创建RBD镜像 rbd create --size 1024 mypool/myimage # 映射RBD设备 rbd map mypool/myimage # 格式化并挂载 mkfs.ext4 /dev/rbd0 mount /dev/rbd0 /mnt/ceph-disk
CephFS文件系统
CephFS是一个POSIX兼容的分布式文件系统,支持多客户端并发访问。它通过MDS管理元数据,提供目录层次结构和文件权限管理。
# 挂载CephFS mount -t ceph mon1/ /mnt/cephfs -o name=admin,secret=AQD... # 或使用内核客户端 ceph-fuse /mnt/cephfs
RADOS网关(RGW)
RGW提供RESTful对象存储接口,兼容Amazon S3和OpenStack Swift API。它支持多租户、用户管理和访问控制,适用于云存储和备份场景。
部署最佳实践
硬件选择
网络:建议使用10Gb以太网,公共网络和集群网络分离。
存储:SSD用于OSD日志和元数据,HDD用于数据存储。
CPU和内存:OSD节点建议每个OSD分配1-2GB内存,Monitor节点需要更多内存。
集群规划
节点数量:最少3个节点,推荐5个或以上节点以提高可用性。
副本数量:生产环境建议设置3副本,可根据可用性需求调整。
PG数量:合理配置PG数量,避免过多或过少影响性能。
安装部署
使用ceph-deploy工具可以简化部署过程:
# 安装ceph-deploy pip install ceph-deploy # 初始化集群 ceph-deploy new node1 node2 node3 # 安装ceph软件包 ceph-deploy install node1 node2 node3 # 部署Monitor ceph-deploy mon create-initial # 部署OSD ceph-deploy osd create node1 --data /dev/sdb ceph-deploy osd create node2 --data /dev/sdb ceph-deploy osd create node3 --data /dev/sdb
运维管理
监控指标
集群健康状态:通过ceph health命令监控集群整体状态。
存储使用率:监控各个存储池的使用情况,及时扩容。
性能指标:关注IOPS、延迟和带宽等关键性能指标。
OSD状态:监控OSD的up/down和in/out状态。
故障处理
OSD故障:自动检测并将故障OSD标记为down,数据会自动重新平衡。
Monitor故障:通过多个Monitor实例保证服务连续性。
网络分区:通过合理的网络规划和Monitor配置避免脑裂。
性能优化
调整复制数量:根据业务需求平衡可用性和性能。
配置参数优化:调整OSD、Monitor和客户端相关参数。
硬件升级:使用更快的网络和存储设备提升整体性能。
使用场景
云计算平台
Ceph广泛应用于OpenStack、CloudStack等云计算平台,为虚拟机提供块存储服务。通过与云管理平台集成,实现存储资源的动态分配和管理。
大数据分析
Ceph可以作为Hadoop、Spark等大数据处理框架的存储后端,提供高吞吐量的数据访问能力。CephFS特别适合需要POSIX语义的大数据应用。
备份和归档
利用Ceph的对象存储能力,构建企业级备份和归档解决方案。RGW的S3兼容接口使得与现有备份软件集成变得简单。
总结
Ceph作为成熟的开源分布式存储系统,在企业级应用中表现出色。它的统一存储架构、高可用性和可扩展性使其成为现代数据中心的理想选择。随着云计算和大数据技术的发展,Ceph将继续在存储领域发挥重要作用。
对于运维工程师而言,深入理解Ceph的架构原理和运维要点,能够帮助构建更加稳定、高效的存储系统。在实际部署中,需要根据具体业务需求进行合理规划和优化,确保系统的最佳性能和可靠性。
-
开源
+关注
关注
3文章
3754浏览量
43981 -
分布式存储
+关注
关注
4文章
181浏览量
19908 -
Ceph
+关注
关注
1文章
25浏览量
9562
原文标题:运维必备:Ceph分布式存储从原理到实践的完整技术栈
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Ceph是什么?Ceph的统一存储方案简析
存储分布式系统中如何从CAP转到PACELC
关于腾讯的开源分布式存储系统DCache
盘点分布式存储系统的主流框架
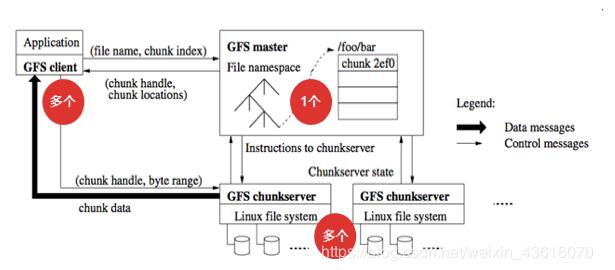
分布式文件存储系统GFS的基础知识
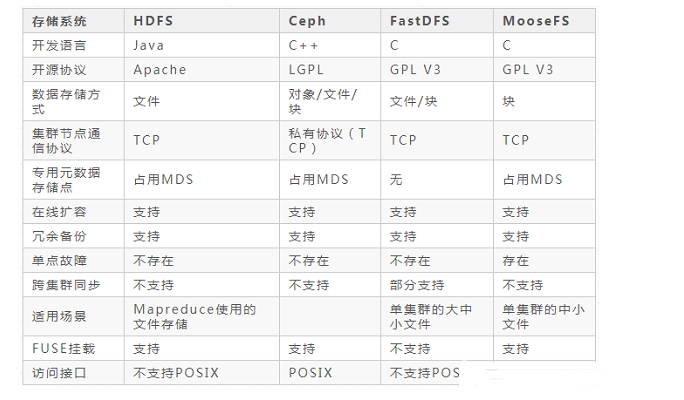
常见的分布式存储系统有哪些类型
常见的分布式文件存储系统的优缺点
云存储中的Ceph分布式文件系统及节点选择








 工商网监
工商网监
评论