 缓解高性能存算一体芯片IR-drop问题的软硬件协同设计
缓解高性能存算一体芯片IR-drop问题的软硬件协同设计

在高性能计算与AI芯片领域,基于SRAM的存算一体(Processing-In-Memory, PIM)架构因兼具计算密度、能效和精度优势成为主流方案。随着存算一体芯片性能的持续攀升,供电电压降(IR-drop)问题日益成为制约其性能、能效与可靠性的关键瓶颈,而传统电路级优化方法往往需在功耗、性能或面积上做出妥协,难以实现系统化解决。
针对这一挑战,后摩智能与北京大学等高校合作的论文《AIM: Software and Hardware Co-design for Architecture-level IR-drop Mitigation in High-performance PIM》,创新性地提出了AIM软硬件协同设计,成功入选ISCA 2025。
该论文首创性地建立了量化工作负载与IR-drop关联的关键参数HR,开发了基于正则化与权重优化的算法以降低权重HR值,设计了动态反馈系统实现电压/频率的实时调节以应对IR-drop波动,并通过HR感知的任务映射机制实现了跨层协同优化。这一系列软硬件协同创新技术有效缓解了高性能PIM芯片的IR-drop问题,同时显著提升了芯片性能与能效表现。基于一款256 TOPS PIM芯片的后仿真验证数据表明,AIM能够将IR-drop大幅降低69.2%,并同步实现能效提升2.29倍或性能增益15.2%。
本文将展开介绍这一创新方法。
研究动机
在高性能存算一体(PIM)芯片中,IR-drop 已成为制约性能与可靠性的关键挑战。7nm 工艺下 256 TOPS SRAM PIM 芯片实测显示,动态 IR-drop 可达 140mV,导致时序违规和计算精度退化。传统电路级方案(如电源平面修改、电容插入)虽能缓解 IR-drop,但会引入高额设计成本并牺牲功耗、性能和面积(PPA)。例如,Graphcore IPU 通过 3D 封装和深槽电容缓解 100mV IR-drop,却导致设计成本激增。
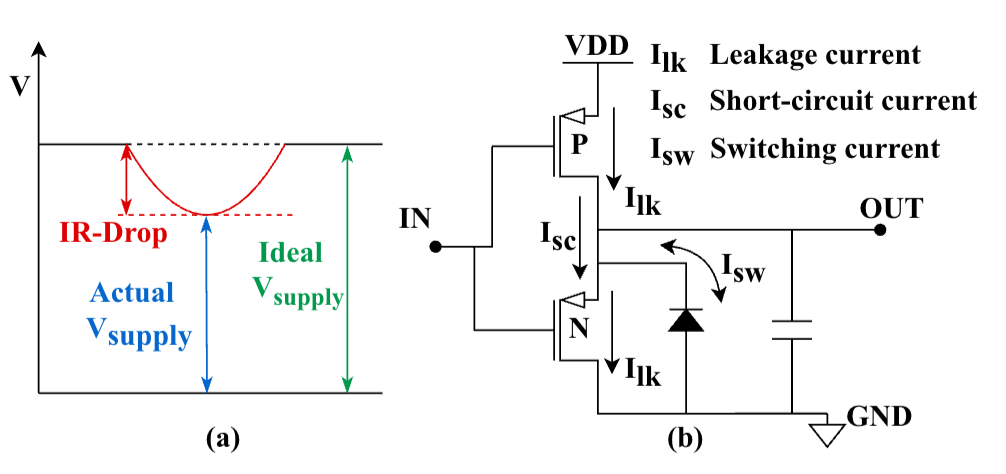
图1:(a)IR-drop现象(b)静态和动态电流
图1 IR-drop现象。实际电源电压和理想电压的插值,由电流通过电源网络的寄生电阻引起,这会导致电路单元电压不足,引发时钟延迟、时序违规甚至功能失效。
图1:(b):静态和动态电流。IR-drop 由静态和动态电流共同决定,其中动态电流随计算负载波动,是高性能 PIM 中 IR-drop 恶化的主要原因。
PIM架构的独特优势为架构级优化提供契机:
工作负载规律性: PIM 专为神经网络设计, workload 可预测(如自LLMs的推理的结构和工作流固定);
原位处理特性:权重数据可离线分析,输入数据流和计算模式解耦。这为建立IR-drop和工作负载的关联奠定基础。
方法简介
AIM通过“指标建模-软件优化-硬件协同”三层架构实现端到端IR-drop缓解:
1.架构级指标关联
提出瞬时位流翻转率(Rtog)和权重汉明率(HR),建立工作负载与IR-drop的直接关联。Rtog量化了PIM bank中从SRAM到加法器的位流翻转频率,如图2所示,其与 IR-drop 的线性相关系数在 7nm DPIM 中达 0.977。而HR作为Rtog的理论上界,可通过量化过程优化,且与输入无关,便于离线处理。
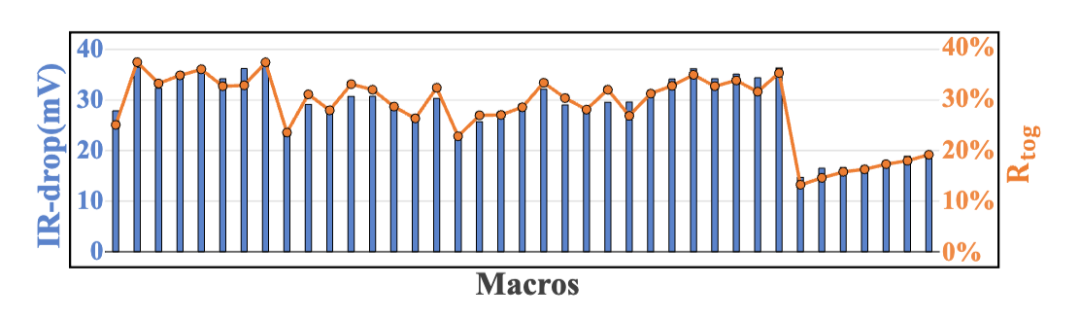
图2:IR-drop和Rtog的相关性
2.软件侧HR优化
2.1 LHR(低汉明率正则化)
在量化训练中引入可微HR近似,惩罚高HR权重,使权重分布趋向低HR局部极小值(如-8、0、8),精度损失可忽略。如图3中所示,Resnet18的可以通过LHR平均降低28%,且精度损失可以忽略。
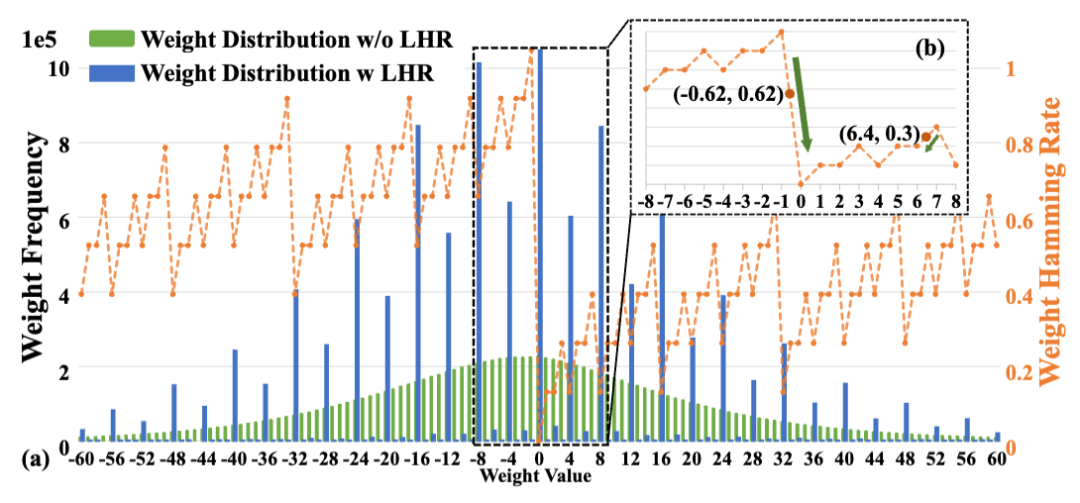
图3:(a) LHR的权重分布与汉明率的局部极小值对齐 (b) 通过插值计算浮点数的HR及其相应梯度
2.2 WDS(权重分布偏移)
通过向量化偏移δ(如8/16)将权重分布推向正区间,利用补码编码特性降低HR,并通过硬件移位补偿消除计算误差。
3.硬件侧动态调节
3.1 IR-Booster
结合软件HR信息与硬件IR监测,动态调整电压-频率(V-f)对。通过安全级与激进级双层调节,在保障可靠性的同时提升能效(如低功耗模式下能效提升2.29×)。
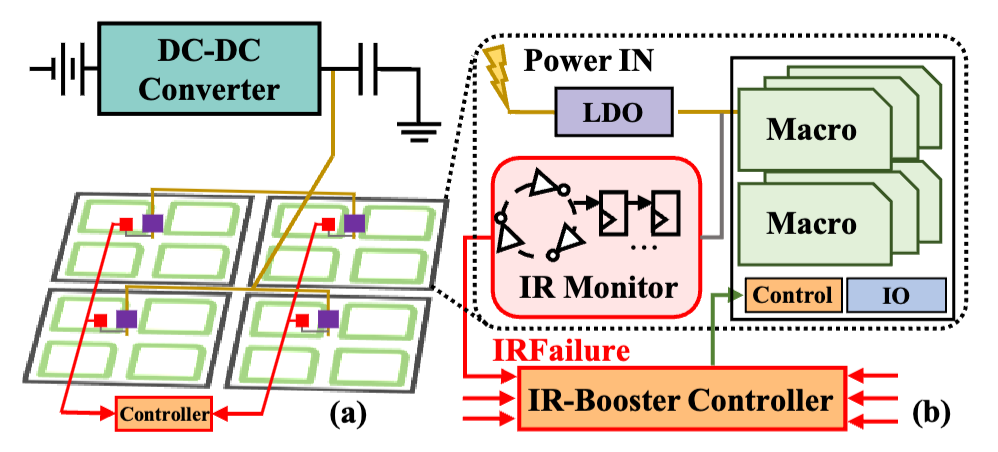
图4:(a) 宏组颗粒度下的电源和V-f调整 (b) 由IRFailure调节的IR-Booster
3.2 HR-aware任务映射
基于模拟退火算法,按 HR 特性分配任务至宏单元组,避免不同 HR 任务相互干扰。与顺序映射相比,如图5所示,该方法将多算子并发时能效提升 15%~22%。
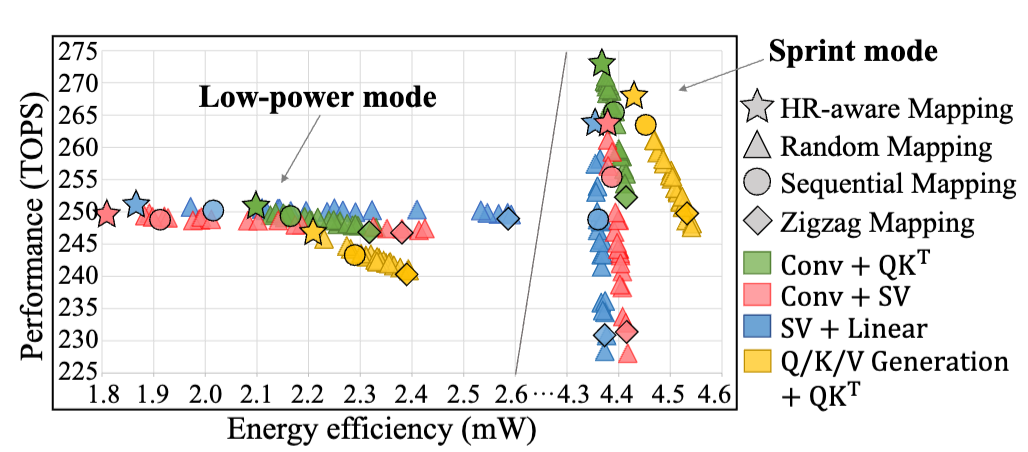
图5:HR感知任务映射与其他方法对比
实验结果
在7nm 256 TOPS PIM芯片的后布局仿真中,AIM展现显著优势:
1.IR-drop缓解
图6展示了展示了应用 AIM 前后,7nm PIM 芯片布局中 IR-drop(电源网络电压降)的分布变化。后布局仿真显示,AIM 将宏单元内的 IR-drop 从 140mV 降至 43.2~58.1mV,缓解率达 58.5%~69.2%,直接证明其在硬件层面的有效性。
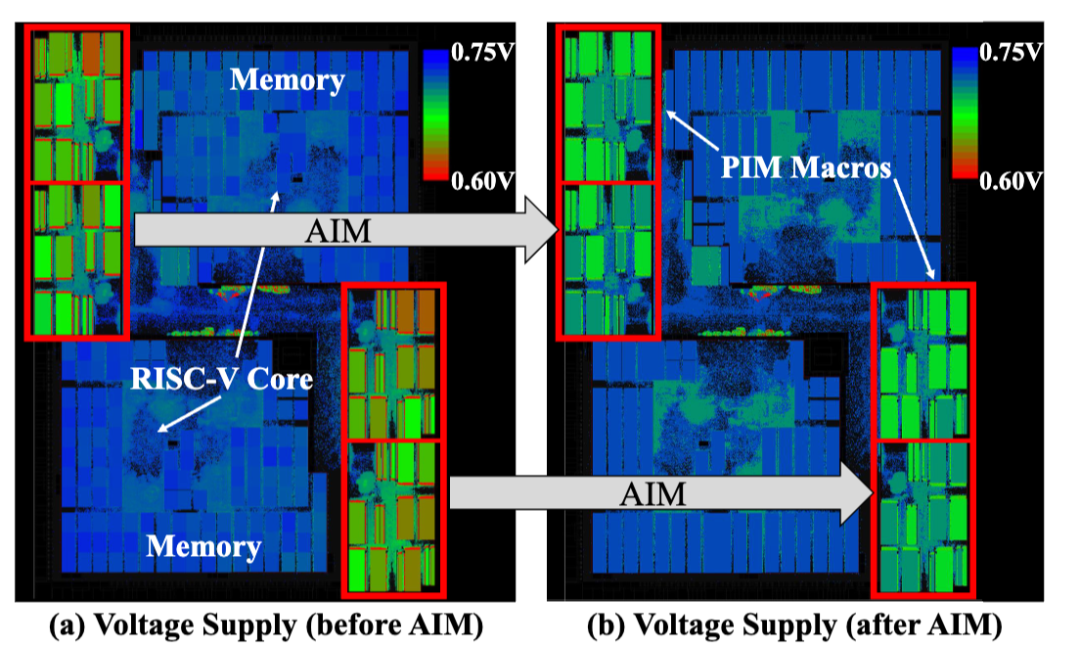
图6:7nm 工艺 256 TOPS PIM 芯片布局的 IR-drop 缓解效果
2.能效与性能提升
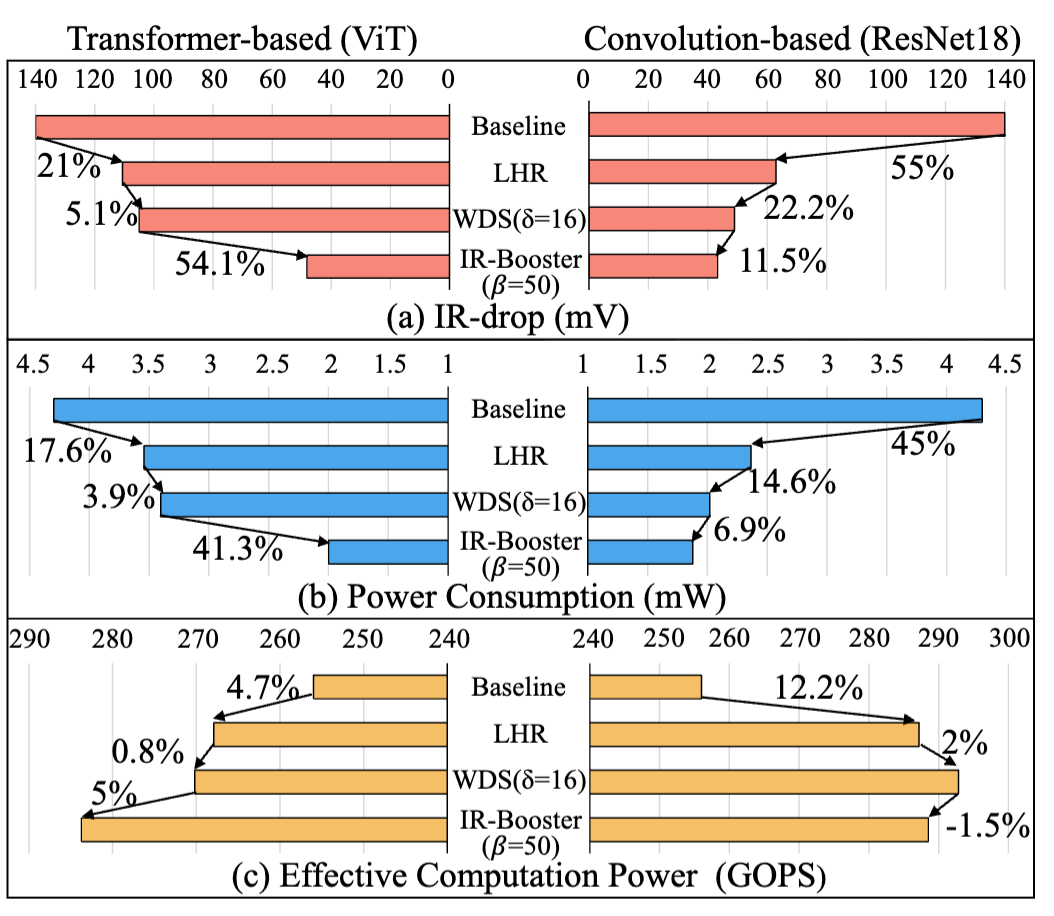
图7:IR-drop、功耗与性能的消融研究
如图7所示,AIM在解决IR-drop的同时优化了芯片的功耗和计算性能。
能效比提升1.91~2.29×(宏单元的功耗从4.2978mW降至1.876mW);
计算性能提升1.129~1.152×(256TOPS提升至295TOPS)。
3.任务映射优化
相比顺序映射,HR-aware映射使多算子并发时的能效提升15%~22%,延迟降低9ms。
总结
AIM通过软硬件协同设计,突破传统IR-drop缓解的PPA瓶颈,为高性能PIM提供了兼具效率与可靠性的解决方案。后布局仿真验证了其在7nm工艺下的有效性,未来可扩展至浮点PIM和异构计算架构(如TPU、GPU)。该工作为存算一体芯片的实用化部署提供了关键技术支撑,代码与模型已开源(https://github.com/pku-zyp/LHR-of-AIM-in-ISCA25.git),推动学术界与产业界的进一步创新。
-
芯片
+关注
关注
460文章
52616浏览量
442669 -
存算一体
+关注
关注
1文章
110浏览量
4702 -
后摩智能
+关注
关注
0文章
38浏览量
1395
原文标题:后摩前沿 | 缓解高性能存算一体芯片IR-drop问题的软硬件协同设计
文章出处:【微信号:后摩智能,微信公众号:后摩智能】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
存算一体大算力AI芯片将逐渐走向落地应用
谈谈芯片设计中的IR-drop







 工商网监
工商网监
评论