 企业和个人基于业务知识和代码库增强的大模型生成代码实践
企业和个人基于业务知识和代码库增强的大模型生成代码实践

1.源起
李明是今年刚加入某互联网公司的研发新人,满怀期待地开始了他的职业生涯。然而,短短两周后,他的热情就被现实浇了一盆冷水。
第一周: 当他第一次接手需求时,mentor只是简单交代了几句:“这个功能之前做过类似的,你参考下历史代码。”可当他打开代码仓库,却发现注释寥寥,变量名像密码一样难懂,更找不到任何需求文档。他硬着头皮修改,结果上线后引发了线上故障——原来有个隐藏的业务规则,只有老员工才知道。
第二周: 测试同事小张跑来问:“这次改动会影响订单状态流转吗?”李明愣住了,他根本不知道系统里还有这样一条链路。小张无奈地说:“上次变更时没留文档,现在只能靠猜。”
第三周: 产品经理突然要求紧急修复一个“历史遗留问题”,但翻遍Confluence,只找到三年前零散的会议记录。运维团队更头疼:每天要花大量时间重复解答“这个报错是什么意思”“服务依赖谁”这类问题。
某天深夜加班时,李明对着屏幕发呆:
?为什么每次变更都像在挖雷?
?为什么系统做这么久,代码烟囱式设计越来越多,知识却只维护在老员工的脑子里?新人学习成本为什么这么大?
?如果有AI能直接告诉我这段代码对应什么需求,或者自动生成业务逻辑说明该多好…
这时,他想如果利用大模型将——它似乎能关联代码、需求文档和运维手册。一个念头闪过:或许,打破这座“代码迷宫”的钥匙,就藏在AI与知识库的结合中?
2.解题思路
连续几周的挫折让李明意识到,这些问题不是他一个人能解决的。他决定主动寻找解决方案。
深夜的办公室里,李明盯着屏幕上复杂的代码,突然萌生了一个想法:如果能把这些零散的知识点都串联起来,是不是就能解决现在的问题?
第一次尝试: 他想起mentor提到过的大模型技术。抱着试试看的心态,他写了个简单的脚本,把公司文档库里的需求文档和代码提交记录做了关联索引。虽然粗糙,但至少能通过关键词搜索到相关文档了。他又想如果把这种基于索引的代码结果,放到大模型训练会碰撞出什么火花呢?
初步验证: 当李明训训练好一个基本的智能体后,当产品经理再次询问某个历史功能时,李明腿间了这个智能体,产品经理查到了两年前的需求,并且还可以做解释。虽然不够完善,但比之前漫无目的地翻找强多了。
系统升级: 受到初步成果的鼓舞,李明开始思考更系统的解决方案。他梳理出三个关键点:
1.基础查询:让新人产品和研发能快速找到常见业务问题的标准答案
2.知识关联:把代码变更和需求文档、故障记录打通,做针对于需求的知识库
3.智能提示:在新需求开发时自动关联历史经验
实际应用: 在开发一个新功能时,李明尝试着把相关历史需求、代码和运维记录都整理到一起。他发现,这样不仅自己理解得更透彻,组内新来的实习生同学都可以用这个快速上手
?
?
?
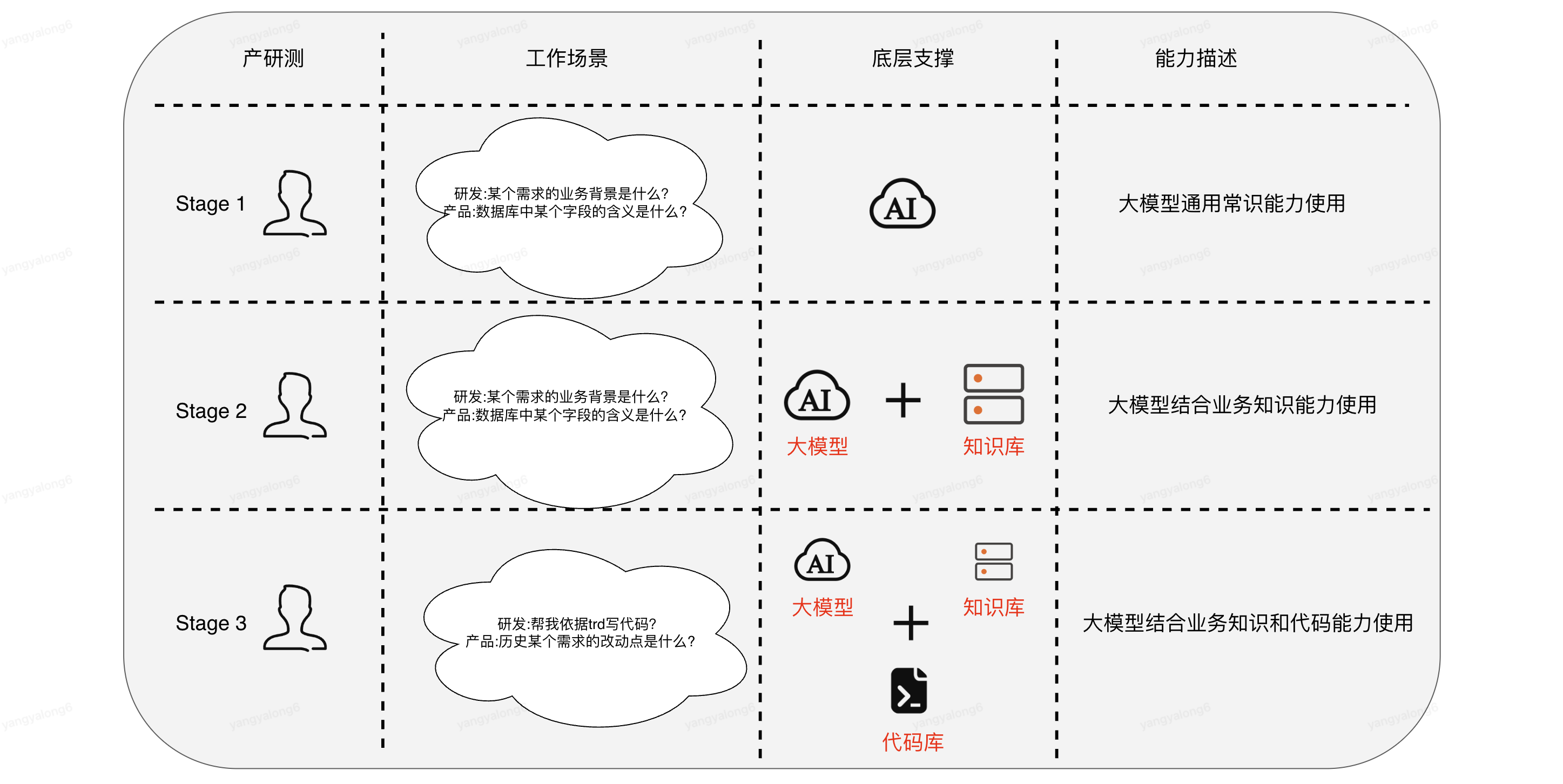
3.大模型应用STAGE-1
此阶段不赘述,作为一个基本常识,能够运用基本的提示词对大模型提问一些常见的工作问题
4.大模型应用STAGE-2
4.1架构图
?
?
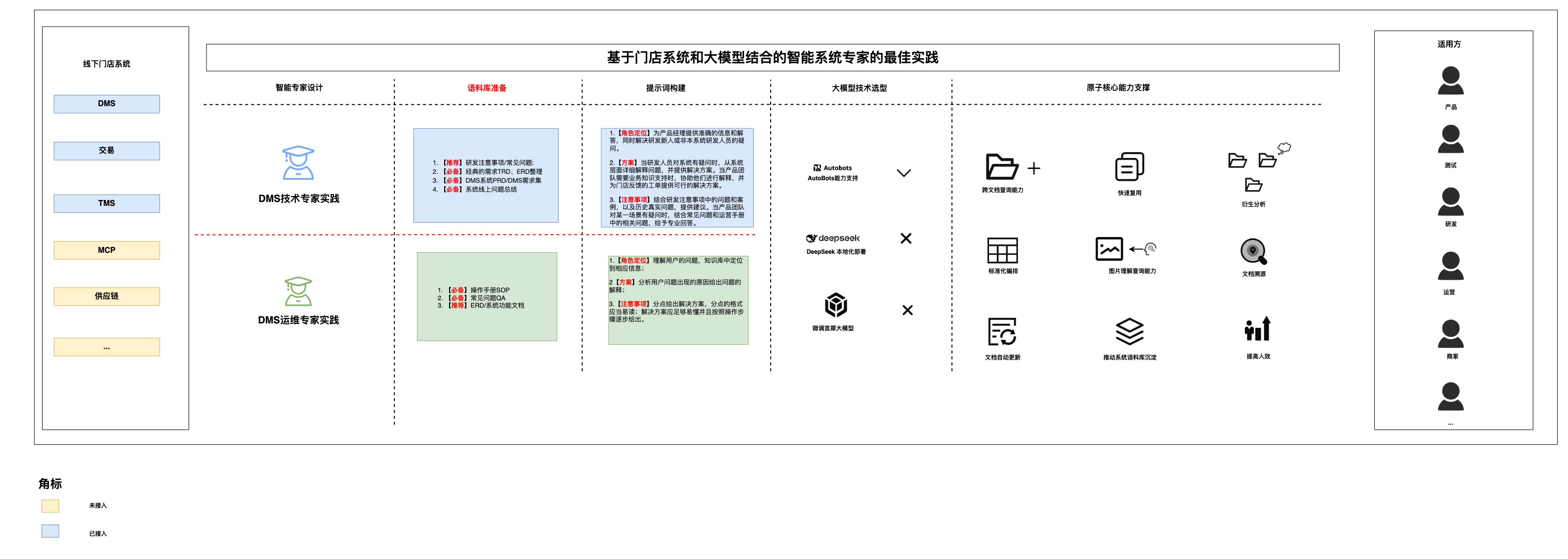
4.2技术路线
ps:此处以DIFY(大模型工作流平台)为例,对于在企业内部的小伙伴要注意权限敏感问题,强烈建议使用各自的内部的大模型平台工具 此处技术路线参考5.2,与5.2类似,此处不赘述
4.3 结果展示-DMS技术专家实践
4.3.1推荐语料库
示例文档添加 扩充文档作用 细化 给出具体范例
1.【必备】经典的需求TRD、ERD整理
ERD文档: 系统文档的梳理可以有助于模型快速熟悉系统,并且可以解释业务方面的知识
TRD文档: 模型可以结合TRD(技术文档),可以从技术角度提出专业意见,并且对系统/技术知识进行解答
系统梳理文档: 可以从数据库设计/系统设计/系统业务功能分享等角度,对系统文档进行补充
1.【推荐】研发注意事项/常见问题:
技术专家可以结合常见问题的文档,给出专业的解释,并且结合历史案例,预防事故的发生。
例如:
(1)历史出现的线上问题,避免线上问题的再次发生
(2)研发/产品整理的Q/A文档,协助产研快速定位并且解决问题
1.【必备】DMS系统PRD/DMS需求集
通过PRD文档,可以帮助模型理解业务,并且结合具体需求,对需求的特定问题进行解答
1.【必备】系统常见的坑合集
通过常见系统问题,例如上线前需要预热,redis共用一套风险,某些MQ流量大消费可能时常积压,
4.3.2推荐提示词
【实践】1.问题解答:为产品经理提供准确的信息和解答,处理他们关于门店工单或系统功能的问题,同时解决研发新人或非本系统研发人员的疑问。
2.方案指引:当研发人员对系统有疑问时,从系统层面详细解释问题,并提供解决方案。当产品团队需要业务知识支持时,协助他们进行解释,并为门店反馈的工单提供可行的解决方案。
3.系统的详细介绍:针对任何人提出的系统设计问题,结合ERD、TRD等文档,详细解释数据库设计、系统设计或业务流程设计,并通过可能的使用场景进行说明。
4.注意事项:在研发提出注意事项或建议时,结合研发注意事项中的问题和案例,以及历史真实问题,提供建议。当产品团队对某一场景有疑问时,结合常见问题和运营手册中的相关问题,给予专业回答。
4.3.3范例
?

?
?
5.大模型应用STAGE-3
5.1架构图
?
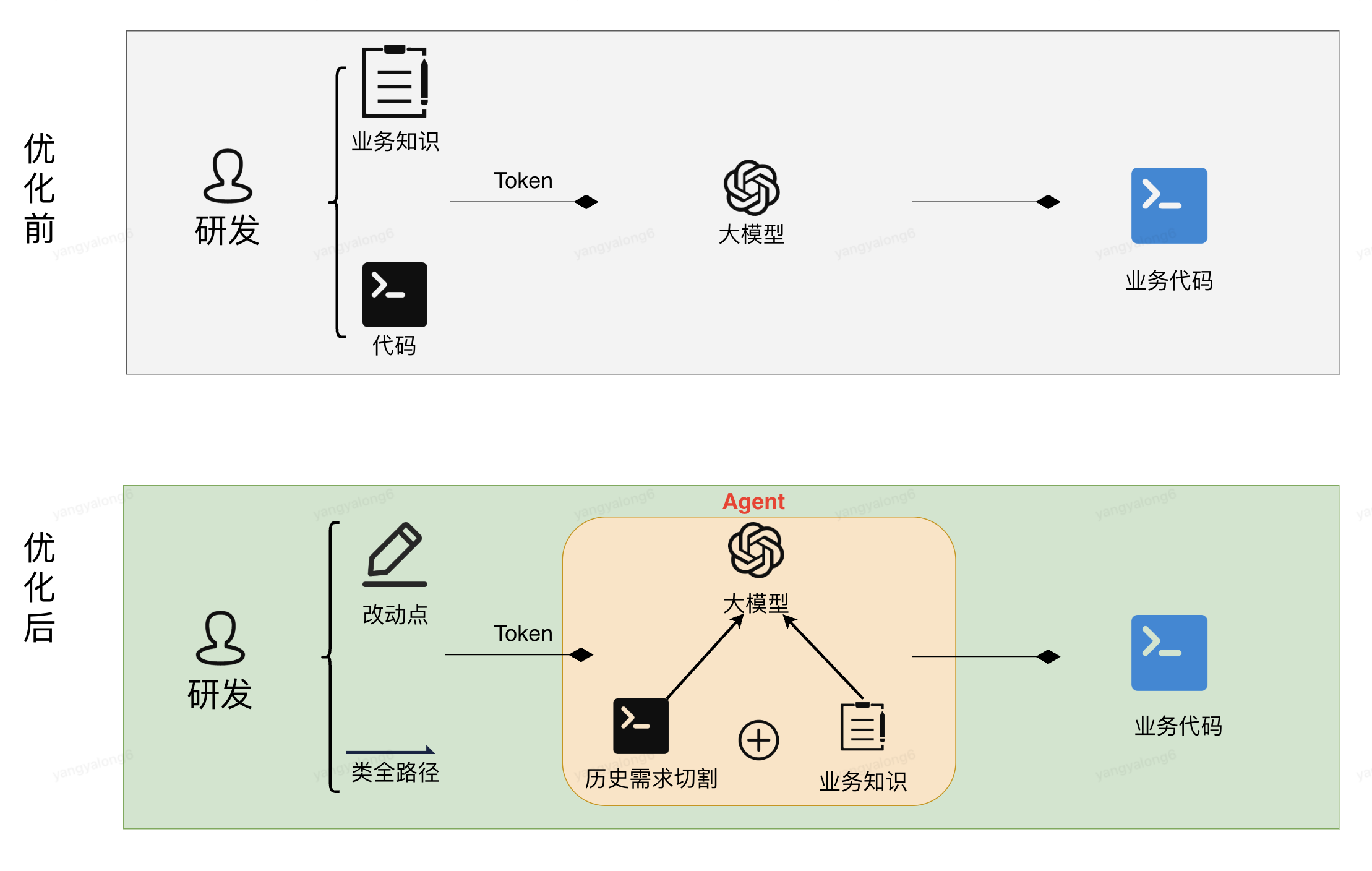
?
?
5.2实践路线
5.2.1 步骤1:绑定需求名称和代码之间的关联关系
1. 通过 Issue/PR 编号关联代码
场景:如果代码提交时在 Commit Message 中引用了 Issue/PR 编号(如 Fix #123),可以通过以下步骤获取关联代码:
curl -H "Authorization: token YOUR_TOKEN"
"https://api.github.com/repos/{owner}/{repo}/issues/{issue_number}"
?返回的 JSON 中会包含 pull_request 字段(如果是 PR)或 timeline_url(通过事件查询关联提交)。
Step 2: 使用 GitHub Commit API 获取具体代码变更:
curl -H "Authorization: token YOUR_TOKEN"
"https://api.github.com/repos/{owner}/{repo}/commits/{commit_sha}"
方法2. 通过 Search API 直接搜索代码
场景:如果代码文件或提交信息中明确包含需求标识(如 [REQ-123]):
curl -H "Authorization: token YOUR_TOKEN"
"https://api.github.com/search/commits?q=repo:{owner}/{repo}+[REQ-123]+in:message"
搜索代码文件内容:
curl -H "Authorization: token YOUR_TOKEN"
"https://api.github.com/search/code?q=repo:{owner}/{repo}+REQ-123+in:file"
?注:需启用 GitHub Advanced Security 才支持代码内容搜索。
3. 通过 Pull Request 获取关联代码
场景:如果需求通过 PR 实现,直接获取 PR 的代码变更:
?Step 1: 获取 PR 详情(包含分支和提交):
curl -H "Authorization: token YOUR_TOKEN"
"https://api.github.com/repos/{owner}/{repo}/pulls/{pr_number}"
?Step 2: 获取 PR 的差异文件(Diff):
curl -H "Authorization: token YOUR_TOKEN"
"https://api.github.com/repos/{owner}/{repo}/pulls/{pr_number}/files"
4. 如果是相关企业
Step 1: 通过内部的代码平台分页获取该应用的历次变更信息
Step 2: 遍历获取唯一id对应的代码变更然后转换成KEY/VALUE格式
6.2.2 步骤2:将获取的数据进行清洗标注上传知识库
ps:此处以DIFY(大模型工作流平台)为例,对于在企业内部的小伙伴要注意权限敏感问题,强烈建议使用各自的内部的大模型平台工具,否则会有法律风险,涉及代码安全
1. 创建空的知识库
curl --location --request POST 'https://api.dify.ai/v1/datasets'
--header 'Authorization: Bearer {api_key}'
--header 'Content-Type: application/json'
--data-raw '{"name": "name", "permission": "only_me"}'
2. 添加分段(代码-需求对)
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/segments'
--header 'Authorization: Bearer {api_key}'
--header 'Content-Type: application/json'
--data-raw '{
"segments": [
{
"content": "需求描述1的详细内容",
"answer": "对应的代码实现1",
"keywords": ["关键词1", "关键词2"]
},
{
"content": "需求描述2的详细内容",
"answer": "对应的代码实现2",
"keywords": ["关键词3", "关键词4"]
}
]
}'
方案二:使用元数据增强搜索(高级方案)
1. 创建元数据字段
curl --location 'https://api.dify.ai/v1/datasets/{dataset_id}/metadata'
--header 'Content-Type: application/json'
--header 'Authorization: Bearer {api_key}'
--data '{
"type": "string",
"name": "code_language"
}'
2. 上传文档并附加元数据
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/document/create_by_text'
--header 'Authorization: Bearer {api_key}'
--header 'Content-Type: application/json'
--data-raw '{
"name": "Python代码示例",
"text": "[代码内容]",
"indexing_technique": "high_quality",
"metadata": {
"code_language": "python"
}
}'
5.2.3 步骤3配置工作流 (此处仅给出示意图)
?
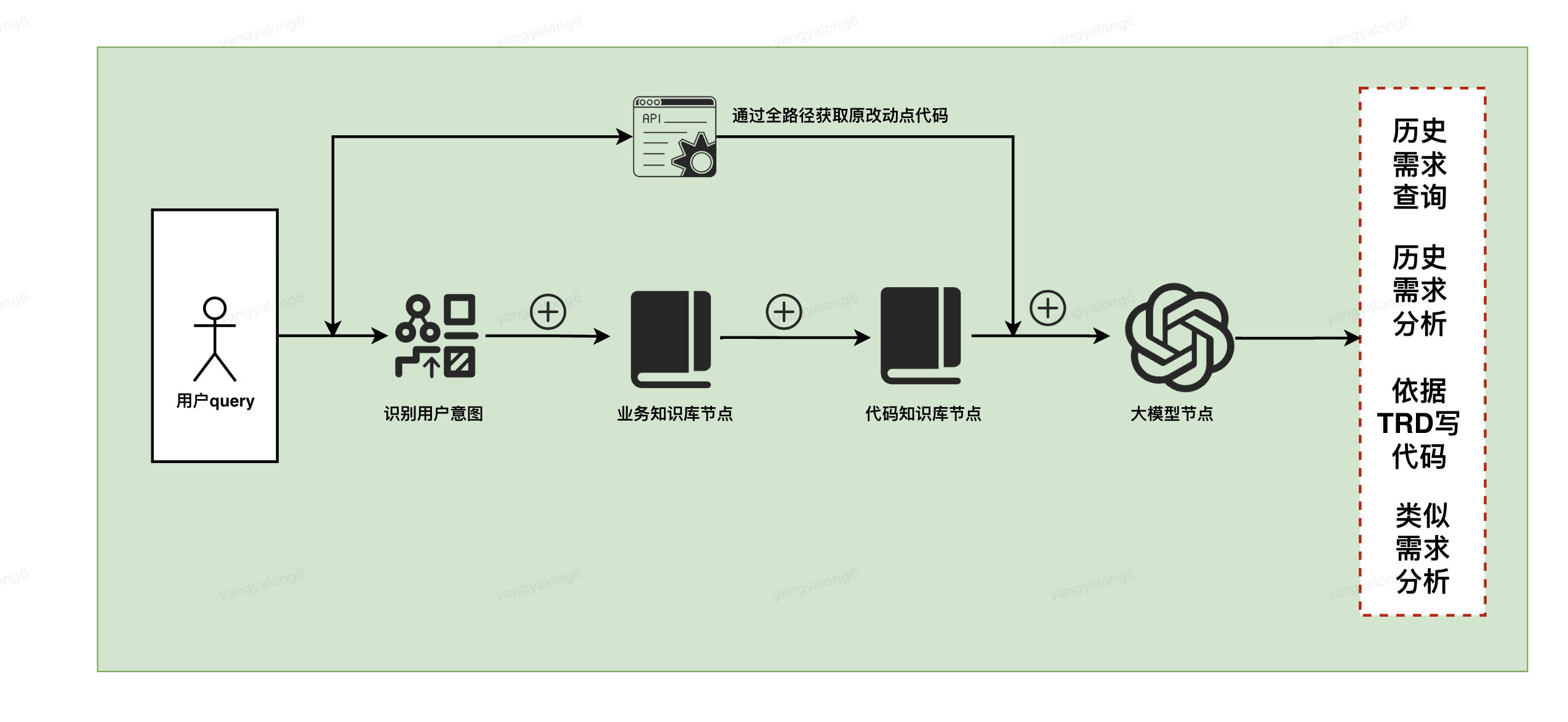
?
?
5.3结果展示
5.3.1历史变动检索
现在想要结合<交易历史需求变更>知识库 拼拼融合华冠改了什么 给出改动代码
?
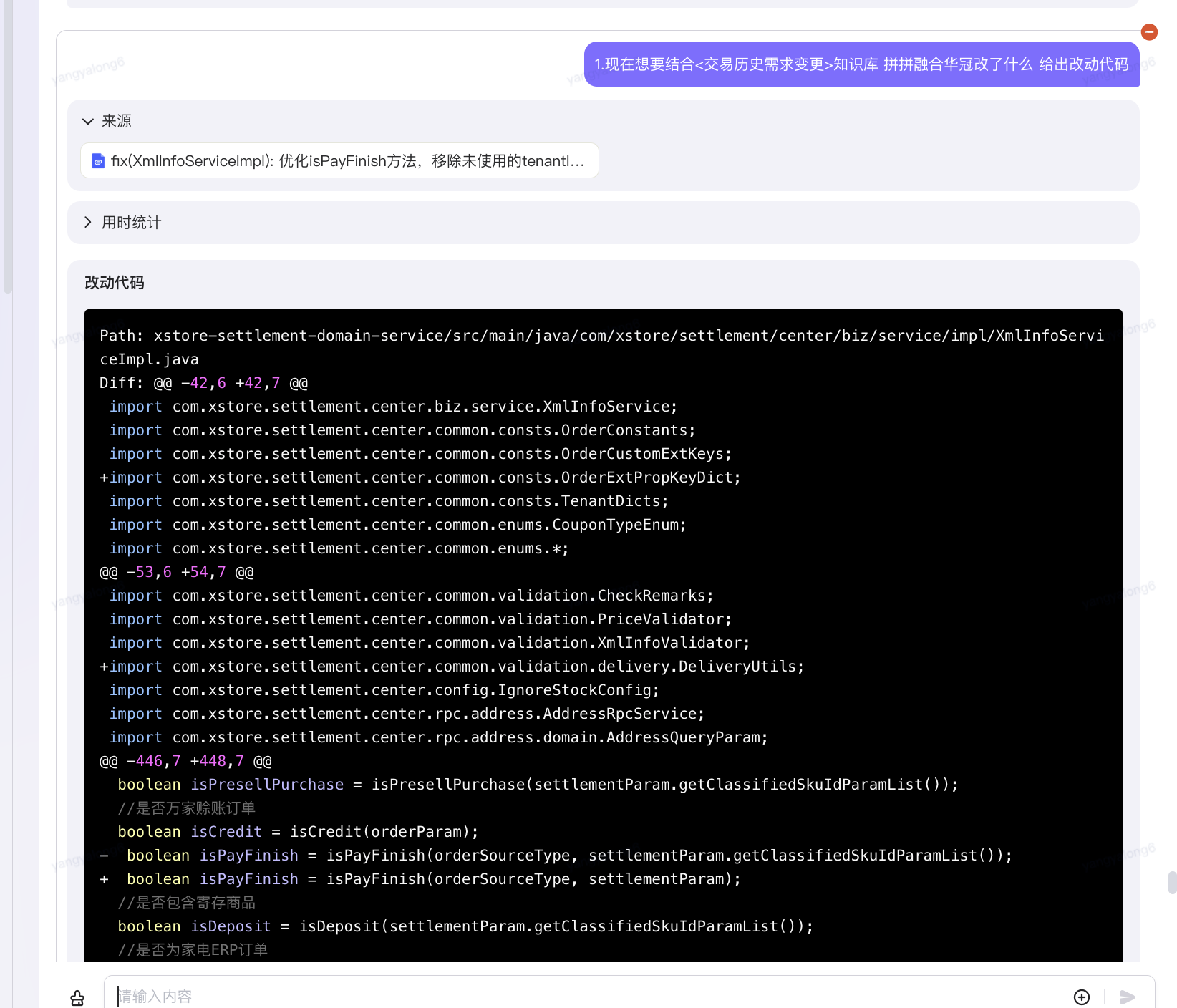
?
?
5.3.2历史变更分析
现在想要结合<交易历史需求变更>知识库 总结拼拼融合华冠改动点 我是产品 看不懂代码 给出
?
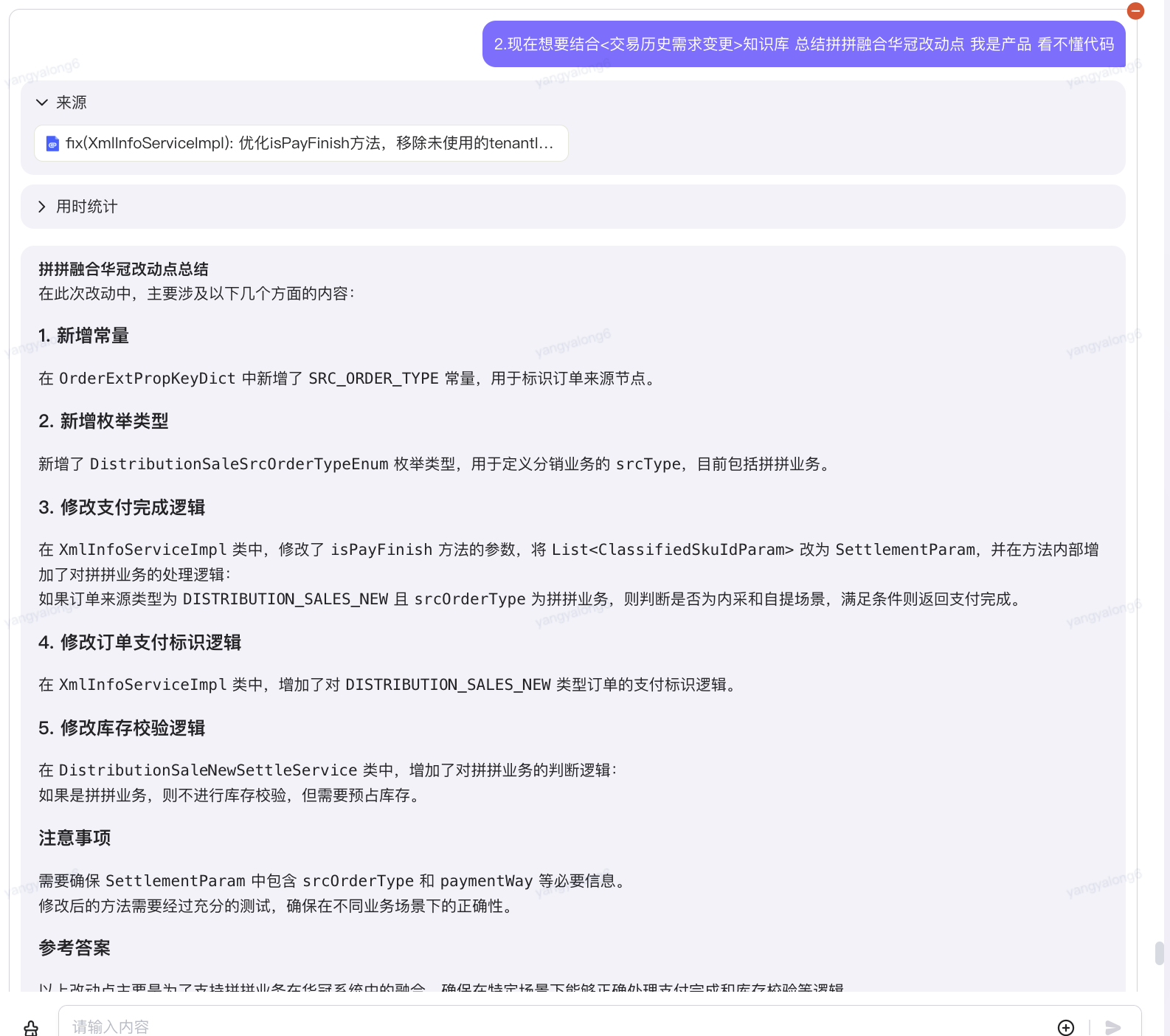
?
?
5.3.3依据TRD写代码
类的全路径com.jd.xstore.settlement.center.biz.service.CommonSettlementFacadeSaasImpl#calculateTotalPrice
改造点PRD:
1)支持POS传入是否使用京豆,
2)查询积理会员系统获取京豆总数量和本单抵扣数量、转变比例,
3)根据京豆总数量和本单抵扣数量、转变比例,计算可抵扣金额,京豆总余(不使用也返回)
4)进行各资产试算
5)结果返回京豆可抵扣金额,本次抵扣数量,京豆总刷量、京豆总余额(不使用也返回)。
?
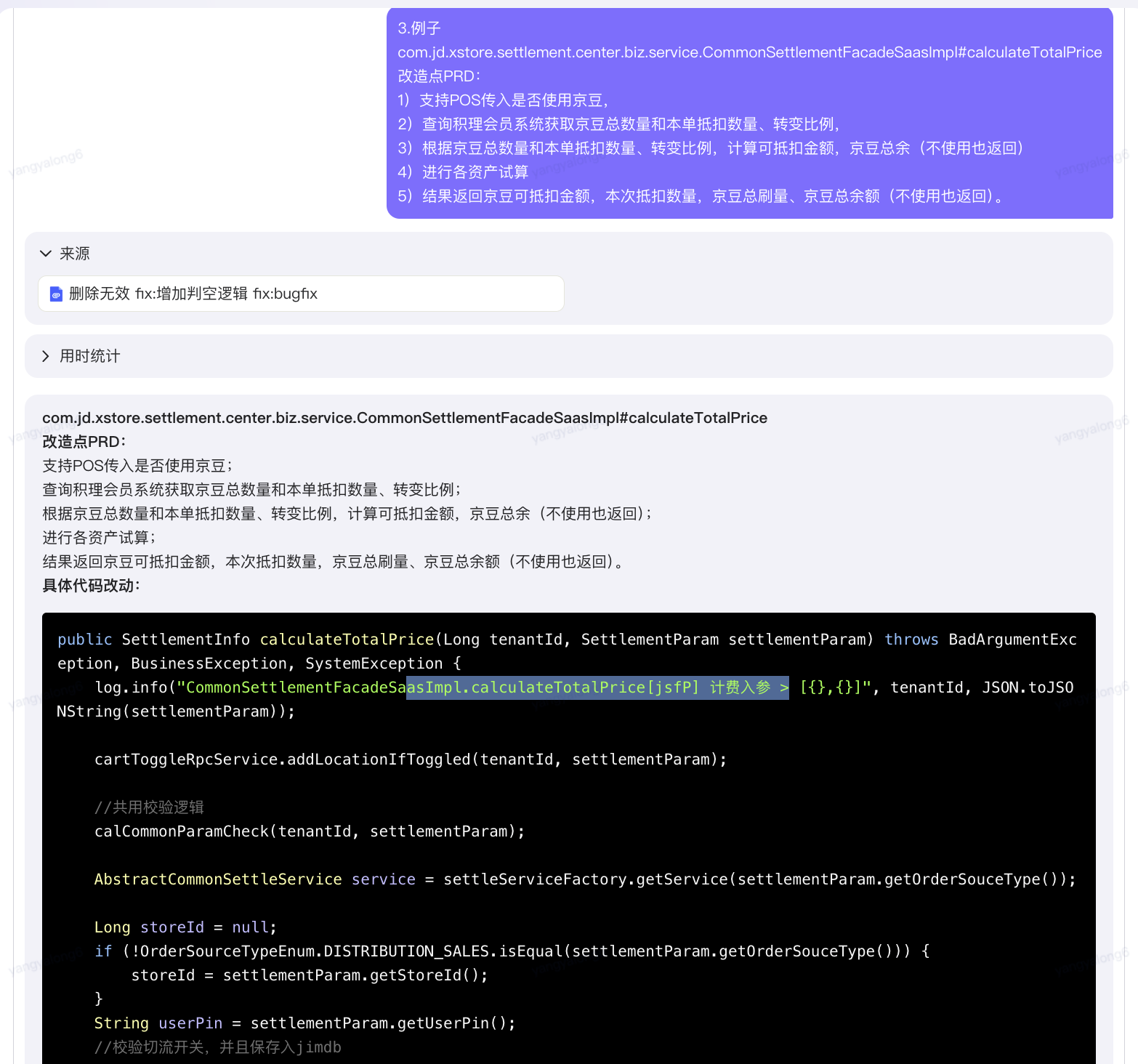
?
?
5.3.4做过的类似的需求设计
新增加一种SendPayParam 需要改动哪些 类型需求支持
?
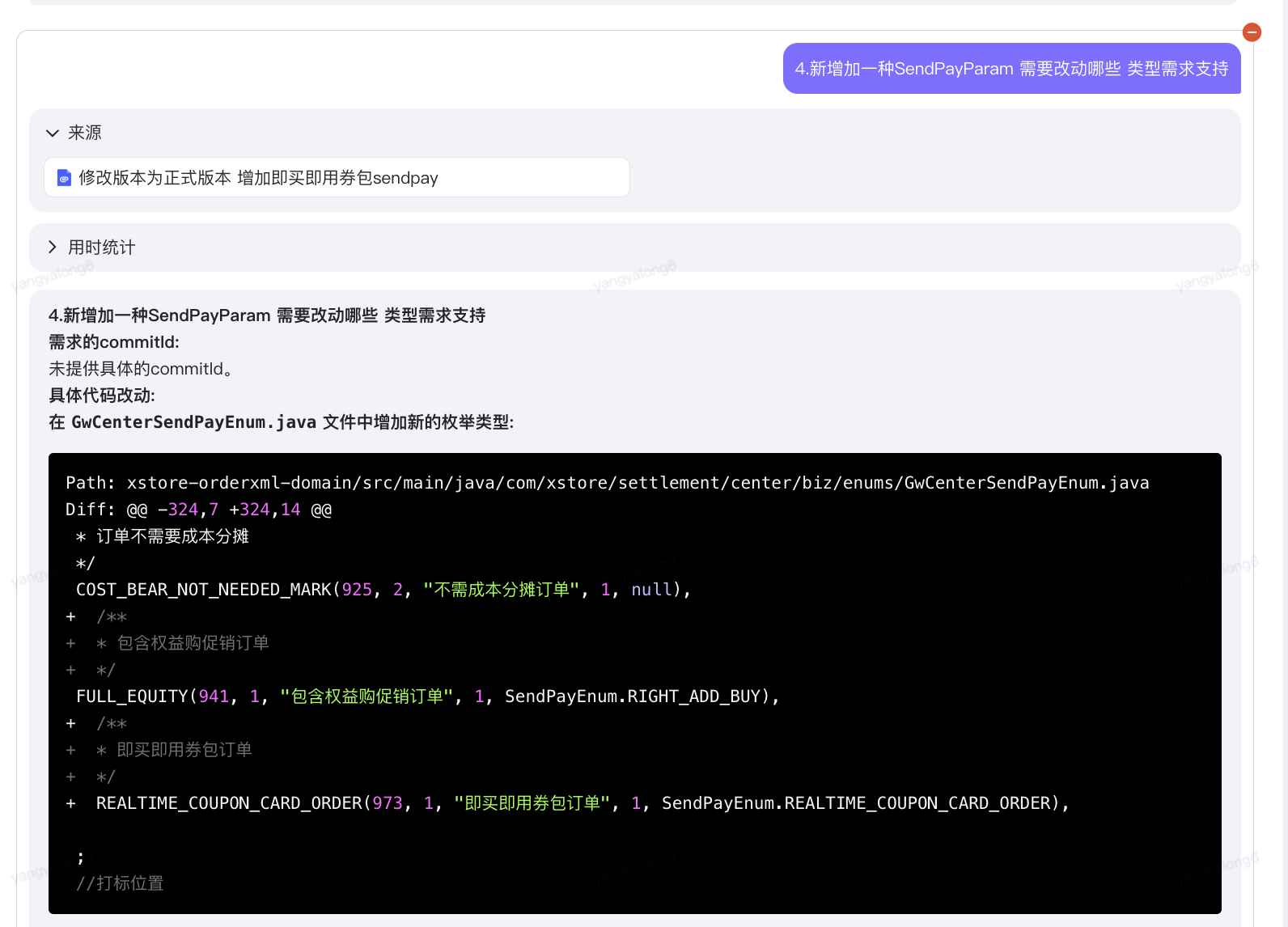
?
?
6.总结
阶段1 - 基础应用 李明首先整理了团队日常使用大模型的常见场景:
?研发人员用AI生成基础代码片段
?测试人员用AI编写测试用例
?产品经理用AI辅助撰写需求文档 这些基础应用虽然简单,但确实提高了部分工作效率。
阶段2 - 知识整合 在取得初步成效后,李明开始着手解决更深层的问题:
1.建立了系统维度的知识库模版,确保关键文档都能被有效收录
2.开发了智能检索功能,不仅能给出答案,还能定位到具体文档位置
3.通过知识库建设,反向推动了各部门完善文档沉淀
4.系统能够结合已有知识,给出更贴近实际的解决方案
阶段3 - 深度应用 随着系统不断完善,李明团队实现了更高级的功能:
1.代码变更追溯:可以查询任意代码段的历史修改记录
2.需求分析:新人产品可以快速了解系统的演进历程
3.开发辅助:研发人员可以基于需求文档自动生成基础代码
4.经验传承:系统可以提供类似需求的实现思路和关键点
这个逐步推进的方案,让团队的知识管理从碎片化走向系统化,有效解决了新人上手难、知识传承难的问题。最重要的是,它建立了一个可持续优化的知识沉淀机制。
7.未来优化
在推进的过程中,李明也发现了一些需要持续改进的问题:
1.代码生成质量依赖需求变动频率李明注意到,对于那些需求变动较少的模块,系统生成的代码往往比较基础,缺乏深度。比如订单核心流程这样长期稳定的模块,生成的代码只能覆盖最基础的场景,难以应对复杂业务逻辑。
2.知识关联的准确性有待提升当前系统对代码变更记录和需求文档的关联还不够精准。特别是在处理历史数据时,经常出现匹配错误的情况。李明发现,如果能严格要求每次代码提交都必须关联明确的需求文档,系统的准确率会有显著提升。
3.他发现,由于采用了RAG技术,生成代码后比较依赖于对于query识别到需求的准确度,比较依赖召回的准确度。
李明意识到,这些问题都需要通过持续优化算法,严格卡控需求和代码绑定来逐步解决。他计划将这些优化点纳入下一阶段的改进计划中。不过他坚信,道阻且长,行则将至,他一次又一次对自己说,"我知道的,我做什么都会成功的"~
审核编辑 黄宇
-
代码
+关注
关注
30文章
4905浏览量
70988 -
大模型
+关注
关注
2文章
3191浏览量
4147
发布评论请先 登录
代码革命的先锋:aiXcoder-7B模型介绍

AI知识库的搭建与应用:企业数字化转型的关键步骤
RAKsmart企业服务器上部署DeepSeek编写运行代码
为什么MotorControl Workbench无法生成代码?
《AI Agent 应用与项目实战》阅读心得3——RAG架构与部署本地知识库

聚云科技荣获亚马逊云科技生成式AI能力认证 助力企业加速生成式AI应用落地
了解DeepSeek-V3 和 DeepSeek-R1两个大模型的不同定位和应用选择
【「基于大模型的RAG应用开发与优化」阅读体验】+第一章初体验
STM32CubeMX生成的代码,是怎样的HAL架构?

借助浪潮信息元脑企智EPAI高效创建大模型RAG

阿里云开源Qwen2.5-Coder代码模型系列
探索设计稿自动生成Flutter代码的技术方案





 工商网监
工商网监
评论