 Aux-Think打破视觉语言导航任务的常规推理范式
Aux-Think打破视觉语言导航任务的常规推理范式

Aux-Think,把推理当作训练时的助力,而非测试时的负担,打破视觉语言导航任务的常规推理范式
视觉语言导航(VLN)任务的核心挑战,是让机器人在复杂环境中听懂指令、看懂世界,并果断行动。我们系统性地引入推理任务,探索其在导航策略学习中的作用,并首次揭示了VLN中的“推理崩塌”现象。研究发现:无论是行动前推理(Pre-Think),还是行动后推理(Post-Think),一旦在测试阶段显式生成推理链,反而更容易让机器人迷失方向。
Aux-Think提出一种更实用的路径:在训练阶段引入推理任务作为辅助监督,引导模型习得更清晰的决策逻辑;而在测试阶段,则彻底省去推理生成,直接进行动作预测。把推理用在该用的地方,模型在任务中反而更稳、更准、更省。Aux-Think不仅有效避免了测试阶段的推理幻觉,也为“推理应在何时、如何使用”提供了清晰答案,进一步拓展了数据高效导航模型的能力边界。
? 论文题目:
Aux-Think: Exploring Reasoning Strategies for Data-Efficient Vision-Language Navigation
? 论文链接:
https://arxiv.org/abs/2505.11886
?项目主页:
https://horizonrobotics.github.io/robot_lab/aux-think/
视觉语言导航 (VLN) 的推理策略
在视觉语言导航 (VLN) 任务中,机器人需要根据自然语言指令在复杂环境中做出实时决策。虽然推理在许多任务中已有广泛应用,但在VLN任务中,推理的作用一直未被充分探讨。我们是第一个系统性研究推理策略对VLN任务影响的团队,发现现有的推理策略 (Pre-Think和Post-Think) 在测试阶段反而导致了较差的表现,让机器人导航失败。与此不同的是,我们提出的Aux-Think框架通过创新设计有效解决了这一问题。
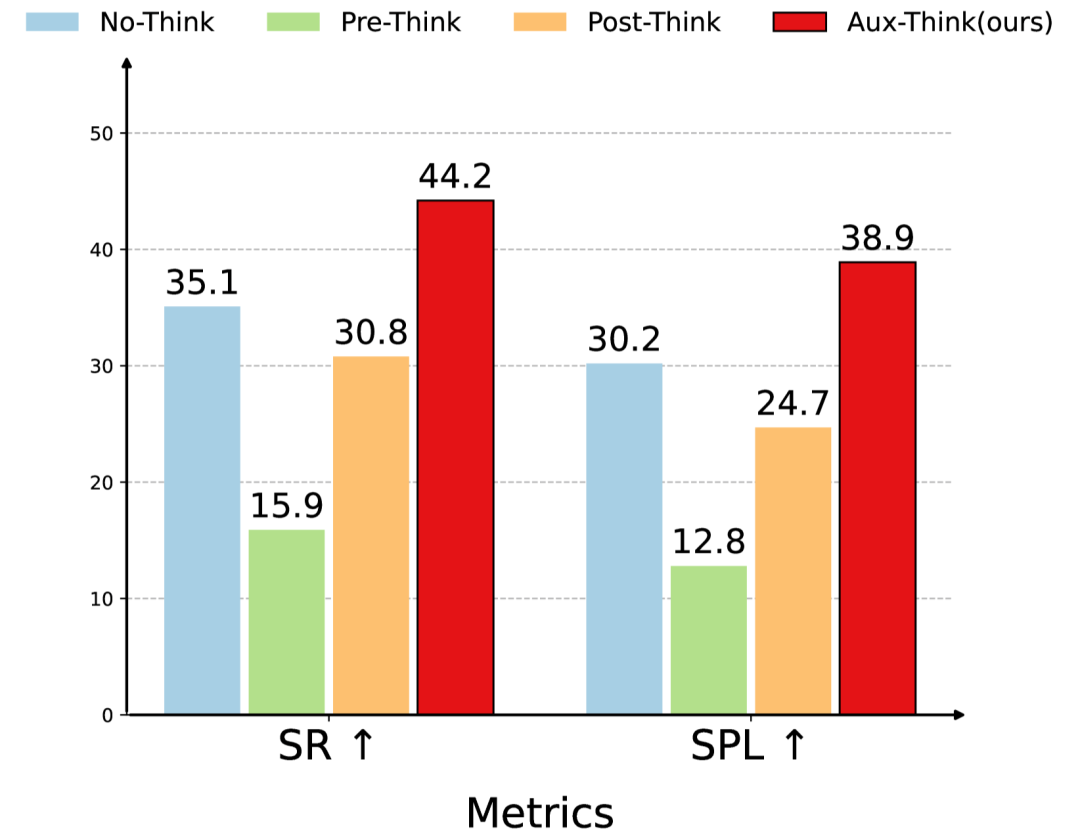
Aux-Think优于Pre-Think和Post-Think其它推理策略
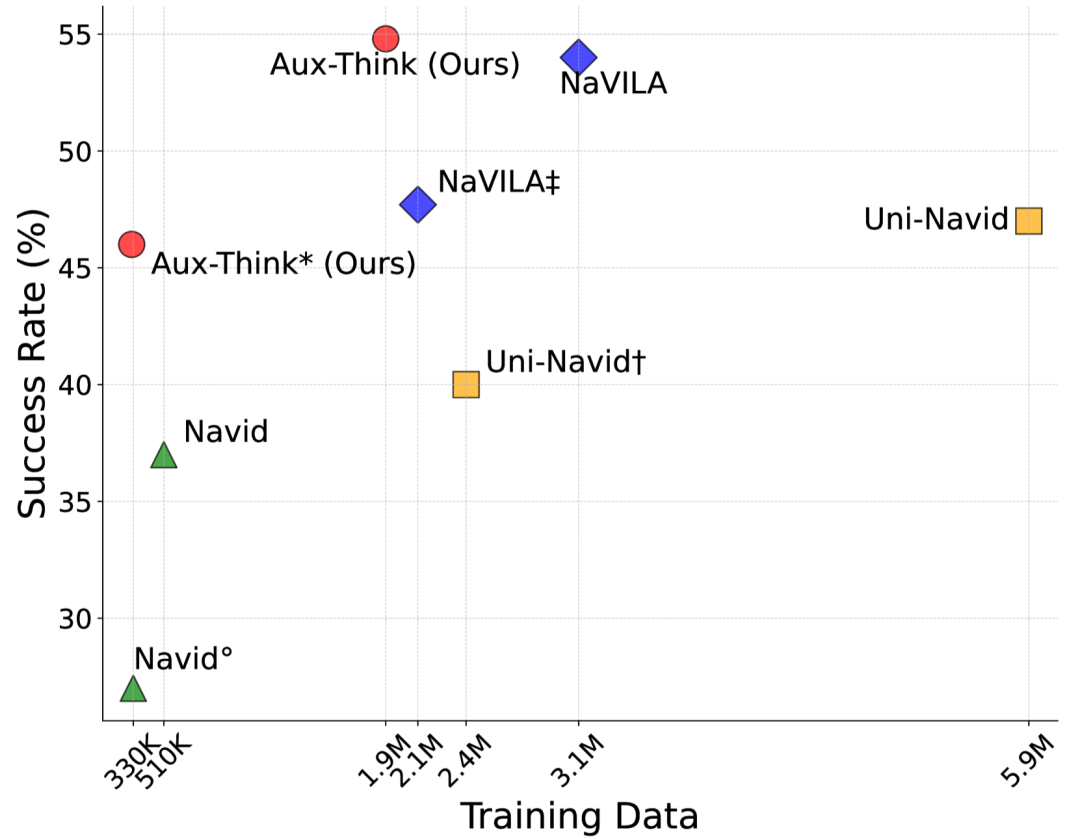
Aux-Think在数据效率与成功率之间达到帕累托最优
测试阶段推理的挑战
想象一名司机在开车时不断分析路况,并频繁回顾交通规则后才做决策。虽然这有助于理解环境,但当遇到陌生或复杂情况时,这种“思考过度”的方式反而容易因推理偏差而判断失误。
在视觉语言导航任务中,推理就像回顾交通规则,决策则对应真实的驾驶操作。推理本意是为了帮助机器人理解任务,但一旦进入训练中未见过的状态,思维链便可能产生幻觉。尤其是在不熟悉的环境中,过度依赖推理不仅无法提升决策,反而干扰行动、累积误差,最终导致机器人“误入歧途”。这种“推理崩塌”现象正是Aux-Think希望解决的关键问题。
Aux-Think给出的新答案
为了应对上述问题,我们提出了Aux-Think,一种全新的推理训练框架。Aux-Think的核心思想是:在训练阶段通过推理指导模型的学习,而在测试阶段,机器人直接依赖训练过程中学到的知识进行决策,不再进行推理生成。具体来说,Aux-Think将推理和行动分开进行:
训练阶段:通过引导模型学习推理任务,帮助其内化推理模式。
测试阶段:直接根据训练中学到的决策知识进行行动预测,不再进行额外的推理生成。
这种设计有效避免了测试阶段推理带来的错误和不稳定性,确保机器人能更加专注于执行任务,减少了推理过程中可能引入的负面影响。
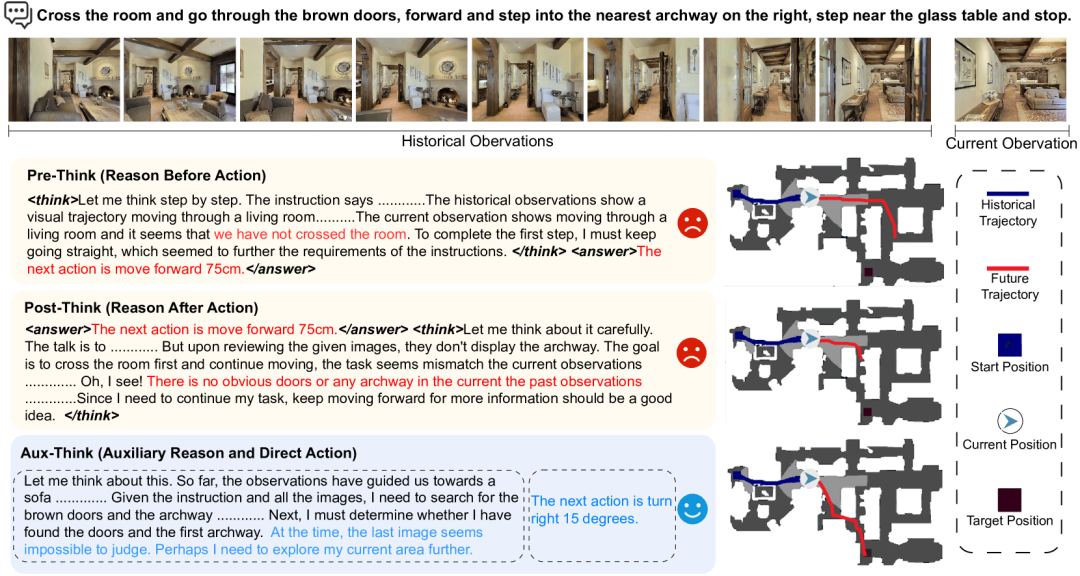
上图中展示的是一个导航任务:“穿过房间,走到右侧的拱门并停在玻璃桌旁”。三种策略面对相同场景做出了不同反应:Pre-Think模型在行动前试图推理整条路径,认为应该“前进75cm”,但忽视了当前观察并未穿过房间,导致偏离目标;Post-Think模型在执行动作后才分析环境,发现没有看到拱门,但错误已发生,只能继续试探,继续偏航;Aux-Think则在训练时学习推理逻辑,测试时直接基于当前观察判断“右转15度”,准确识别拱门位置,成功完成导航任务。
实验结果
大量实验表明,Aux-Think在数据效率与导航表现方面优于当前领先方法。尽管训练数据较少,Aux-Think仍在多个VLN基准上取得了单目 (Monocular) 方法中的最高成功率。通过仅在训练阶段内化推理能力,Aux-Think有效缓解了测试阶段的推理幻觉与错误传播,在动态、长程导航任务中展现出更强的泛化能力与稳定性。
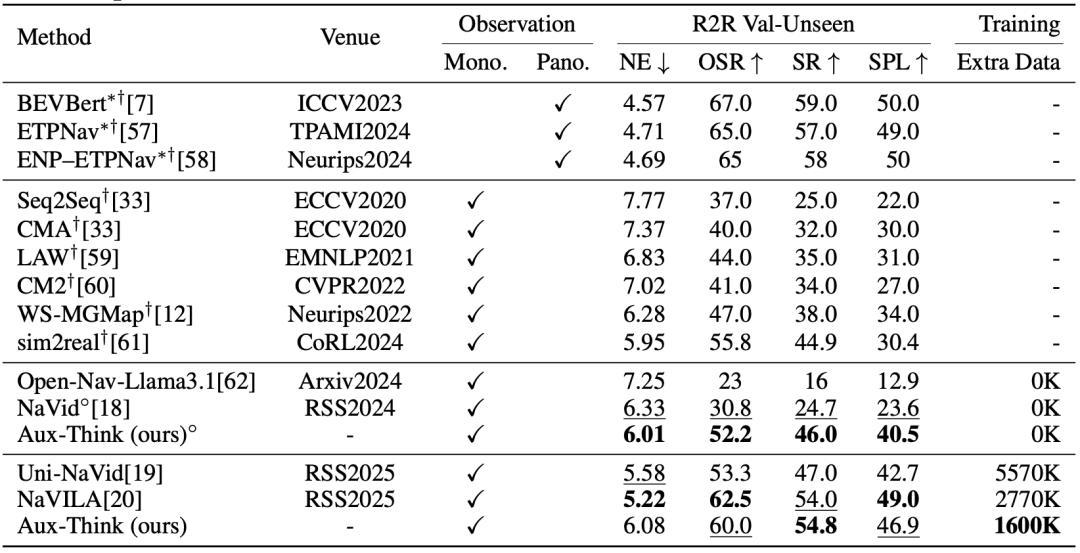
R2R-CE上的指标:Aux-Think在视觉语言导航任务的R2R验证集 (Val-Unseen) 上取得领先的成功率 (SR) ,即使使用的训练数据更少,也能超越多种现有方法。
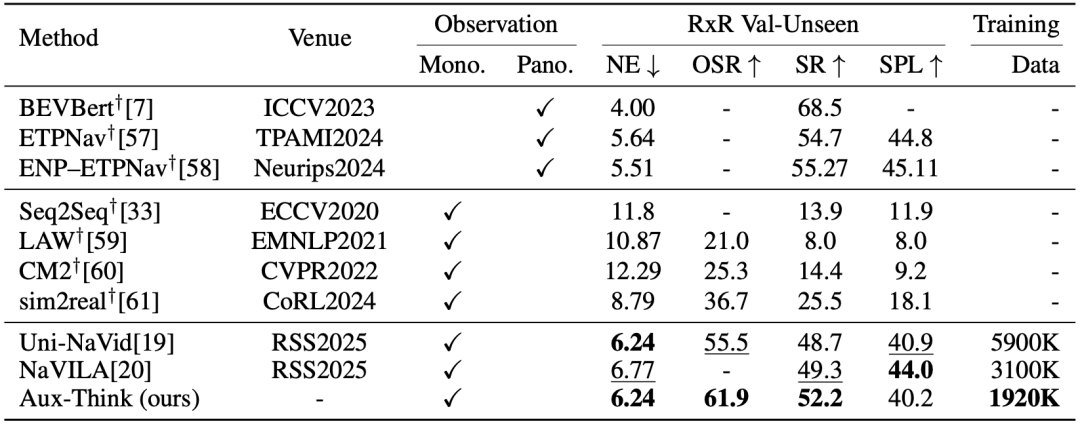
RxR-CE上的指标:RxR比R2R更大、更复杂,Aux-Think在RxR验证集上依然以更少数据实现更高成功率 (SR) ,展现出优越的泛化能力。
总结与展望
Aux-Think为解决测试阶段推理引发的导航问题提供了新的思路。通过在训练阶段引入推理指导,在测试阶段去除推理负担,Aux-Think能够让机器人更加专注于任务执行,从而提高其导航稳定性和准确性。这一突破性进展将为机器人在实际应用中的表现奠定更为坚实的基础,也为具身推理策略提供了重要启示。
.
-
机器人
+关注
关注
213文章
29829浏览量
213544 -
导航
+关注
关注
7文章
555浏览量
43252
原文标题:开发者说|Aux-Think:为什么测试时推理反而让机器人「误入歧途」?
文章出处:【微信号:horizonrobotics,微信公众号:地平线HorizonRobotics】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
大型语言模型的逻辑推理能力探究
一种在视觉语言导航任务中提出的新方法,来探索未知环境
各位高手,我想在汽车导航电路板上加一个aux输出接口
基于计算机视觉和NLP的跨媒体问答与推理


ACL2021的跨视觉语言模态论文之跨视觉语言模态任务与方法
用于语言和视觉处理的高效 Transformer能在多种语言和视觉任务中带来优异效果
视觉语言导航领域任务、方法和未来方向的综述
多维度剖析视觉-语言训练的技术路线
深度探讨VLMs距离视觉演绎推理还有多远?

基于视觉语言模型的导航框架VLMnav
NaVILA:加州大学与英伟达联合发布新型视觉语言模型
think-cell:与PowerPoint交换文件
新品| LLM630 Compute Kit,AI 大语言模型推理开发平台






 工商网监
工商网监
评论