 基于NVIDIA AI的3D机器人感知与地图构建系统设计
基于NVIDIA AI的3D机器人感知与地图构建系统设计

机器人必须感知和理解其 3D 环境,才能安全高效地行动。这一点在非结构化或陌生空间中的自主导航、对象操作和远程操作等任务尤为重要。当前机器人感知技术的进展,越来越多地体现在通过统一的实时工作流与强大的感知模块,实现 3D 场景理解、可泛化物体跟踪与持久性空间记忆的集成。
本期“NVIDIA 机器人研究与开发摘要 (R?D?) ”将探讨 NVIDIA 研究中心的多个感知模型和系统,这些模型和系统支持统一的机器人 3D 感知堆栈。它们可在不同的真实世界环境中实现可靠的深度估计、摄像头和物体位姿追踪以及 3D 重建:
FoundationStereo(CVPR 2025 最佳论文提名):用于立体深度估计的基础模型,可在各种环境(包括室内、室外、合成和真实场景)中实现零样本性能的泛化。
PyCuVSLAM:用于 cuVSLAM 的 Python Wrapper,支持 Python 用户利用 NVIDIA 的 CUDA 加速 SLAM 库,用于实时摄像头位姿估计和环境建图。
BundleSDF:用于 RGB-D 视频中 6-DoF 物体位姿追踪和密集 3D 重建的神经系统。
FoundationPose:可泛化的 6D 物体位姿估计器和跟踪器,适用于仅有最少先验信息的新物体。
nvblox Pytorch Wrapper:nvblox 库的 Pytorch wrapper,nvblox 是一个 CUDA 加速库,用于 PyTorch 的深度摄像头 3D 重建。
3D 空间表示:机器人感知的核心
这些项目的核心在于强调 3D 空间表示,即以机器人可以使用的形式捕获环境或物体的结构。FoundationStereo 可处理立体图像深度估计的基本任务。它引入了一个用于立体深度的基础模型,专为实现强零样本泛化而设计。

图 1. 使用 FoundationStereo 生成的视差图像
FoundationStereo 已在超过 100 万对合成立体图像上进行训练。它无需针对特定场景进行调整,即可在各种环境(包括室内、室外、合成和真实场景,如图 1 所示)中推断出准确的视差,从而推理得到 3D 结构。输出包括表示场景 3D 结构的密集深度图或点云。
在环境映射方面,nvblox 和 cuVSLAM 等库会随着时间的推移构建空间表示。NVIDIA 的 nvblox 是一个 GPU 加速的 3D 重建库,可重建体素网格体素网格,并输出用于导航的 Euclidean signed distance field (ESDF) 热图。这使移动机器人能够仅使用视觉进行 3D 避障,为昂贵的 3D 激光雷达传感器提供了一种经济高效的替代方案。
虽然 nvblox 擅长几何映射,但缺乏对环境的语义理解。借助 nvblox_torch,我们引入了一个 PyTorch Wrapper,它可以将 2D VLM 基础模型的语义嵌入提升到 3D。
同样,cuVSLAM 通过 Isaac ROS 为机器人提供 GPU 加速的视觉惯性 SLAM。cuVSLAM 以前仅限于 ROS 用户,现在可以通过名为 PyCuVSLAM 的新 Python API 进行访问,这简化了数据工程师和深度学习研究人员的集成工作。
深度和地图构建模块可创建几何支架(无论是点云、signed distance fields,还是特征网格),并在此基础上构建更高级别的感知和规划。如果没有可靠的 3D 呈现,机器人就无法准确感知、记忆或推理世界。
用于场景理解的实时 SLAM和摄像头位姿估计
将这些项目连接在一起的一个关键方面是通过 SLAM(同步定位与地图构建)实现实时场景理解。cuVSLAM 是一种高效的 CUDA 加速 SLAM 系统,用于在机器人的板载 GPU 上运行的立体视觉惯性 SLAM。

图 2. 使用 cuVSLAM 生成的定位
对于更偏向使用 Python 的简单性和通用性的开发者来说,利用强大而高效的 Visual SLAM 系统仍然是一项艰巨的任务。借助 PyCuVSLAM,开发者可以轻松地对 cuVSLAM 进行原型设计并将其用于应用,例如通过互联网规模的视频生成机器人训练数据集。该 API 可以从第一人称观看视频中估计自我摄像头的位姿和轨迹,从而增强端到端决策模型。此外,将 cuVSLAM 集成到 MobilityGen 等训练流程中,可以通过学习真实的 SLAM 系统错误来创建更稳健的模型。功能示例如图 2 所示。
实时 3D 映射

图 3. 上图显示了使用 nvblox_torch 构建的重建,左下角展示了将视觉基础模型特征融合到 3D voxel grid 中的过程,这是表示场景语义内容的常用方法。
右下角显示了从重建中提取的 3D 距离场切片
nvblox_torch 是一个易于使用的 Python 接口,用于 nvblox CUDA 加速重建库,允许开发者轻松地对用于操作和导航应用的 3D 地图构建系统进行原型设计。
空间记忆是机器人完成较长距离任务的核心能力。机器人通常需要推理场景的几何和语义内容,其中场景的空间范围通常大于单个摄像头图像所能捕获的空间范围。3D 地图将多个视图中的几何和语义信息聚合为场景的统一表示。利用 3D 地图的这些特性可以提供空间记忆,并支持机器人学习中的空间推理。
nvblox_torch 是一个 CUDA 加速的 PyTorch 工具箱,用于使用 RGB-D 摄像头进行机器人映射。该系统允许用户在 NVIDIA GPU 上将环境观察结果与场景的 3D 呈现相结合。然后,可以查询此 3D 表示形式的数量,例如障碍物距离、表面网格和占用概率(请见图 3)。nvblox_torch 使用来自 PyTorch 张量的零复制输入/ 输出接口来提供超快性能。
此外,nvblox_torch 还添加了深度特征融合这一新功能。此功能允许用户将视觉基础模型中的图像特征融合到 3D 重建中。随后,生成的重建将同时表示场景的几何图形和语义内容。3D 基础模型特征正在成为基于语义的导航和语言引导操作的热门表示方法。nvblox_torch 库中现已提供此表示方法。
6-DoF 物体位姿追踪和新物体的 3D 重建
以物体为中心的感知也同样重要:了解场景中的物体是什么、它们在哪里以及它们如何移动。FoundationPose 和 BundleSDF 这两个项目解决了 6-DoF 物体位姿估计和追踪的挑战,其中也包括机器人以前从未见过的物体。
FoundationPose 是一种基于学习的方法:它是用于 6D 物体位姿估计和跟踪的统一基础模型,适用于基于模型和无模型的场景。这意味着同一系统可以处理已知对象(如果有可用的 CAD 模型)或全新对象(仅使用少量参考图像),而无需重新训练。FoundationPose 通过利用神经隐式表示来合成物体的新视图来实现这一点,有效地弥合了完整 3D 模型与仅有稀疏观察之间的差距。
它在大规模合成数据上进行训练(借助基于 LLM 的数据生成工作流等技术),具有强大的泛化能力。事实上,只要提供最少的信息,比如模型或图像,就可以在测试时即时应用于新对象。这种基础模型方法在位姿基准测试中实现了最出色的准确性,在保持对新物体的零样本能力的同时,性能优于专门方法。

图 4. FoundationPose 在机器人机械臂中的应用
BundleSDF 采用在线优化驱动的方法来解决此问题,提供了一种近实时 (~ 10 Hz) 方法,用于从 RGB-D 视频中同时进行 6-DoF 位姿追踪和神经 3D 重建。它仅假设第一帧中的分割;之后不需要先验 CAD 模型或类别知识。
BundleSDF 的关键是并发学习的 Neural Object Field,一种神经隐式 SDF,可在观察时捕获物体的几何图形和外观。当物体移动时,BundleSDF 会使用过去的帧不断优化位姿图,随着时间的推移优化位姿轨迹和形状估计。位姿估计与形状学习的集成可有效解决大型位姿变化、遮挡、低纹理表面和镜面反射等挑战。在交互结束时,机器人可以拥有一致的 3D 模型并追踪动态获取的位姿序列。
该框架概述如图 5 所示。首先,在连续图像之间匹配特征以获得粗略的位姿估计 (Sec. 3.1),一些位姿帧存储在内存池中一遍后续进行优化 (Sec. 3.2),根据池中的一个子集动态创建位姿图 (Sec. 3.3),在线优化会细化图中的所有位姿以及当前位姿,更新的位姿存储回池中。最后,池中的所有位姿帧在单独的线程中,学习 Neural Object Field,用于对几何和视觉纹理进行建模 (Sec. 3.4),同时调整之前估计的位姿。
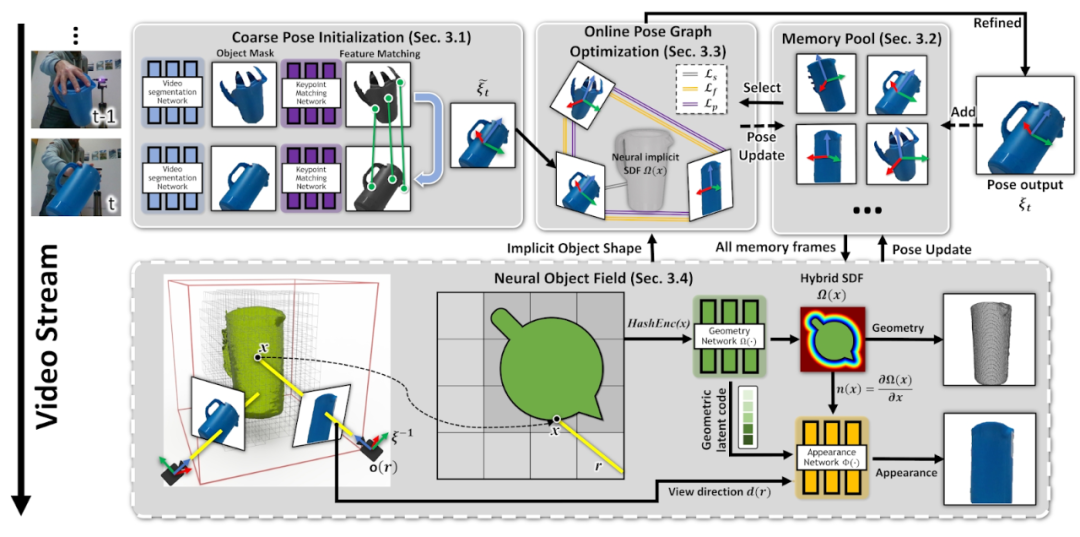
图 5. BundleSDF 框架,该框架使用内存增强的位姿图来估计和优化视频流中的 3D 物体位姿,
并学习几何图形和外观的神经物体表示
FoundationPose 和 BundleSDF 都强调了对象级 3D 理解在机器人开发中的重要性。机器人如果需要抓取或操控任意物体,必须能够感知物体的 3D 位置和方向(位姿),通常还需要感知其形状。这些项目展示了两条互补的路径:预训练的基础模型,通过学习广泛的先验来泛化到新对象;以及用于构建自定义模型的对象的在线 neural SLAM 。在实践中,这些功能甚至可以协同工作,例如,基础模型可以提供初步猜测,然后通过在线重建进行改进。机器人正在朝着新物体的实时 6D 感知发展,而不是局限于识别一组固定的已知物体。
基础模型:跨任务的泛化和统一
更多的机器人感知系统利用基础模型,即只需极少调整即可跨任务泛化的大型神经网络。这在 FoundationStereo 和 FoundationPose 中很明显,它们分别为立体深度估计和 6D 物体位姿追踪提供了强有力的基准。
FoundationStereo 将之前于 DepthAnythingV2 的侧调整单目深度整合到立体模型框架中,无需重新训练即可增强鲁棒性和域泛化。它在各种环境中使用超过 100 万个合成立体对进行训练,在 Middlebury、KITTI 和 ETH3D 数据集等基准测试中实现了先进的零样本性能。该模型改进了成本体积编码器和解码器,增强了远程差异估计。
在图 6 中,Side-Tuning Adapter (STA) 利用来自冻结的 DepthAnythingV2 的丰富单目先验,以及来自多级 CNN 的详细高频特征来提取一元特征。Attentive Hybrid Cost Filtering (AHCF) 将 Axial-Planar Convolution (APC) 过滤与 Disparity Transformer (DT) 模块相结合,在 4D 混合成本体积中有效聚合跨空间和差异维度的特征。根据此过滤后的成本量预测初始差异,并使用 GRU 块进行细化。每个优化阶段都会使用更新后的差异从过滤后的混合成本体积和相关体积中查找特征,从而指导下一个优化步骤,并产生最终的输出差异。
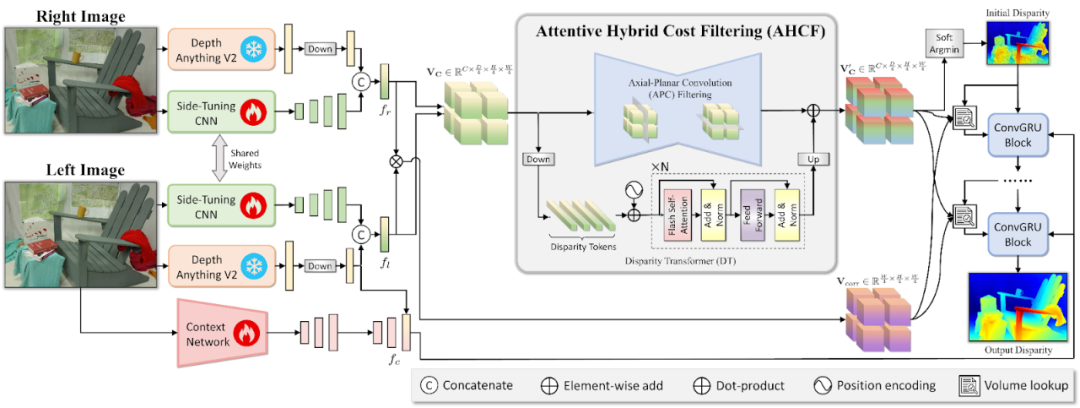
图 6. 通过 AHCF 从输入图像到输出差异的 FoundationStereo 流
FoundationPose 是一个统一模型,用于对新物体进行单帧 6D 位姿估计和多帧位姿追踪。它通过学习物体几何图形的神经隐式表示,支持基于模型和基于图像的推理。它使用 CAD 模型或一些 RGB 引用泛化到不可见的对象。它基于大语言模型生成的大型合成数据集进行训练,包括各种任务提示和场景变体。
FoundationPose 利用对比训练和基于 Transformer 的编码器,在 YCB-Video、T-LESS 和 LM-OCC 等基准测试中的表现明显优于 CosyPose 和 StablePose 等特定任务基准。图 7 展示了 FoundationPose 的工作原理。为了减少大规模训练的人工工作量,我们使用新兴技术和资源(包括 3D 模型数据库、LLMs 和 diffusion models)创建了合成数据生成工作流 (Sec. 3.1)。为了将无模型设置和基于模型的设置连接起来,我们使用 object-centric neural field (Sec. 3.2),用于新颖的视图 RGB-D 渲染和渲染与比较。对于位姿估计,我们会在物体周围均匀地初始化全局位姿,并通过 refinement network 进行优化 (Sec. 3.3)。最后,我们将优化后的位姿发送到位姿选择模块,以预测其分数,并选择具有最佳分数的姿势作为输出 (Sec. 3.4)。
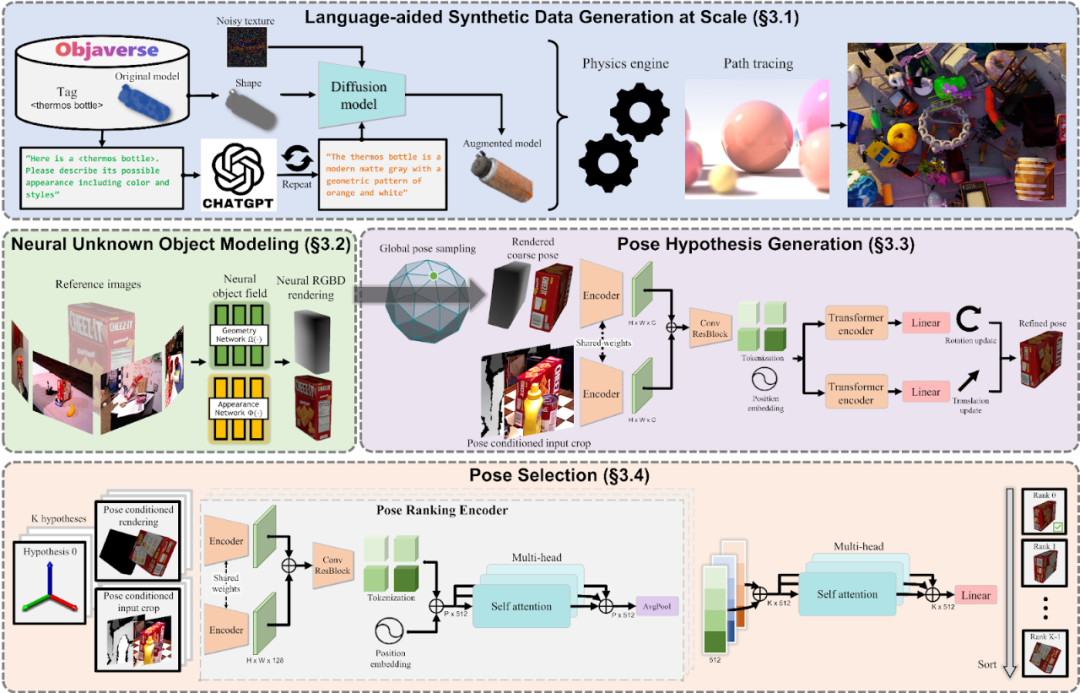
图 7. 该工作流通过结合神经渲染、细化和位姿假设排序来生成合成训练数据并估计物体位姿
这些模型共同标志着机器人技术在构建统一可复用感知主干的道路上迈出了关键一步。通过将深度和物体几何的通用先验知识嵌入实时系统,机器人能够在零样本场景中(包括训练未涉及的环境中以及从未见过的物体交互场景)实现可靠性能,随着机器人技术朝着更具适应性的开放世界部署发展,基础模型提供了在通用感知框架内支持广泛任务所需的灵活性和可扩展性。
迈向集成式 3D 感知堆栈
这些项目共同指向一个统一的 3D 感知堆栈,其中深度估计、SLAM、物体追踪和重建作为紧密集成的组件运行。FoundationStereo 可提供可靠的深度,cuVSLAM 可跟踪摄像头位姿以进行实时定位和映射,而 BundleSDF 和 FoundationPose 可处理物体级理解,包括 6-DoF 追踪和形状估计,即使是未见过的物体也不例外。
通过基于 foundation models 和神经 3D 表征构建,这些系统实现了通用的实时感知,支持在复杂环境中进行导航、操作和交互。机器人技术的未来在于这种集成堆栈,其中感知模块共享表示和上下文,使机器人能够以空间和语义意识进行感知、记忆和行动。
总结
本期 R?D? 探讨了立体深度估计、SLAM、物体位姿跟踪和 3D 重建等领域的最新进展,以及如何融合到统一的机器人 3D 感知堆栈中。这些工具大多由基础模型驱动,使机器人能够实时理解环境并与之交互,即使面对新物体或陌生场景也能应对自如。
-
机器人
+关注
关注
213文章
29829浏览量
213544 -
NVIDIA
+关注
关注
14文章
5324浏览量
106633 -
AI
+关注
关注
88文章
35476浏览量
281232 -
模型
+关注
关注
1文章
3531浏览量
50565
原文标题:R?D?:利用 NVIDIA 研究中心的研究成果,构建 AI 驱动的 3D 机器人感知与地图构建系统
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
《电子发烧友电子设计周报》聚焦硬科技领域核心价值 第20期:2025.07.14--2025.07.18
《电子发烧友电子设计周报》聚焦硬科技领域核心价值 第21期:2025.07.21--2025.07.25
走到哪都不会迷路,全自动机器人是怎么导航的?
Voxel 3D 飞行时间传感器机器人视觉参考设计
基于Arduino的3D打印2轮机器人
INDEMIND 3D语义地图构建技术在机器人上的应用
机器人如何构建3D语义地图?
NVIDIA Isaac 平台先进的仿真和感知工具助力 AI 机器人技术加速发展
利用NVIDIA Isaac平台构建、设计并部署机器人应用






 工商网监
工商网监
评论