 NVIDIA Blackwell GPU优化DeepSeek-R1性能 打破DeepSeek-R1在最小延迟场景中的性能纪录
NVIDIA Blackwell GPU优化DeepSeek-R1性能 打破DeepSeek-R1在最小延迟场景中的性能纪录

近年来,大语言逻辑推理模型取得了显著进步,但也带来了新的部署挑战。其中,因复杂的“思考与逻辑推理”过程而引起的输出序列长度 (OSL) 的加长已成为一大难题。OSL 的加长提高了对 token 间延迟 (Token-to-Token Latency, TTL) 的要求,往往会引发并发限制。在最极端的情况下,实时应用会面临单并发(最小延迟场景)这一特别棘手的问题。
本文将探讨NVIDIATensorRT-LLM如何基于 8 个 NVIDIA Blackwell GPU 的配置,打破 DeepSeek-R1 在最小延迟场景中的性能纪录:在 GTC 2025 前将 67 token / 秒 (TPS) 的速度提升至 253 TPS(提速3.7 倍),而目前这一速度已达 368 TPS(提速5.5 倍)。
实现配置
一、工作负载配置文件
输入序列长度 (ISL):1000 token
输出序列长度 (OSL):2000 token
二、模型架构
DeepSeek-R1 的基础主模型包含:3 个密集层(初始)和 58 个 MoE 层,此外还有 1 个多 token 预测 (Multi-Tokens Prediction, MTP) 层(相当于 MoE 架构)用于推测性解码。我们的优化配置将 MTP 层扩展成 3 个层,采用自回归方法探索其最大性能。
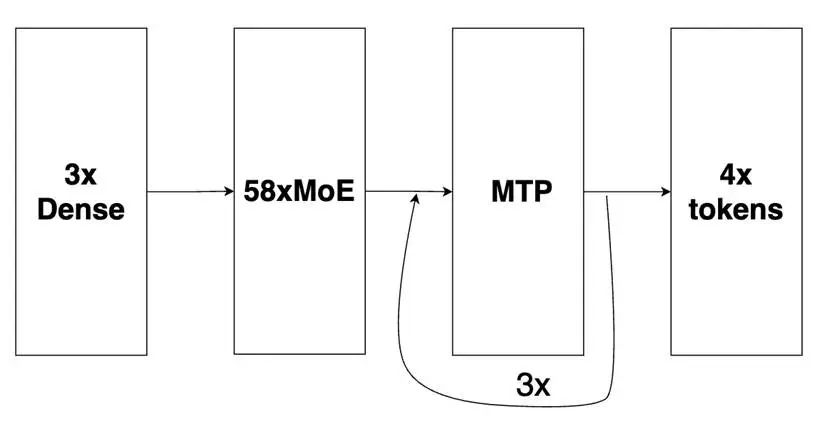
图1: DeepSeek-R1 的基础主模型
该图片来源于 Github: Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA Blackwell GPUs 一文,若您有任何疑问或需要使用该图片,请联系该文作者
三、精度策略
我们探索出了一种能够更好平衡准确度与性能的混合精度方案。
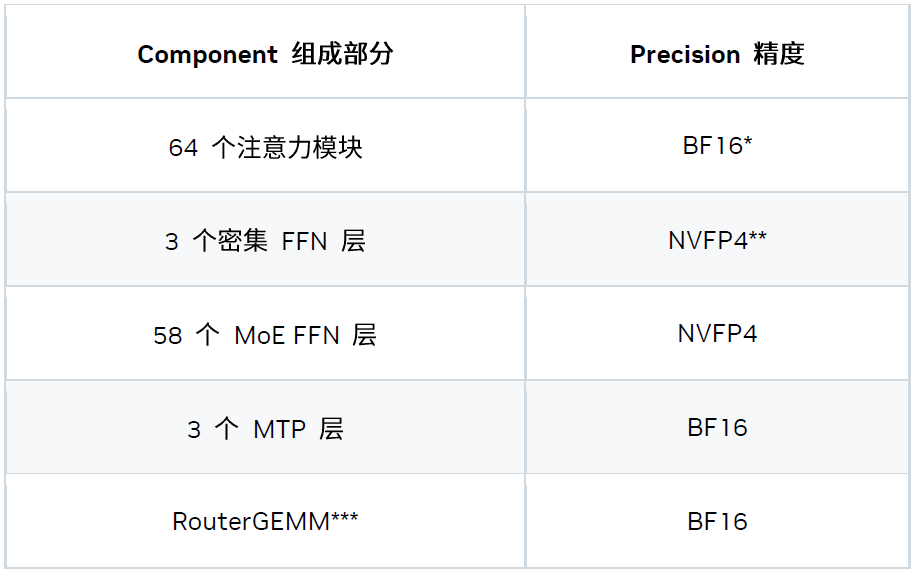
* TensorRT-LLM 已支持 FP8 Attention。但在该延迟场景下,低精度注意力计算并不能提升性能,因此我们为注意力模块选择了 BF16 精度。
** NVFP4 模型检查点由 NVIDIA TensorRT 模型优化器套件生成。
*** RouterGEMM 使用 BF16 输入 / 权重与 FP32 输出来确保数值的稳定性
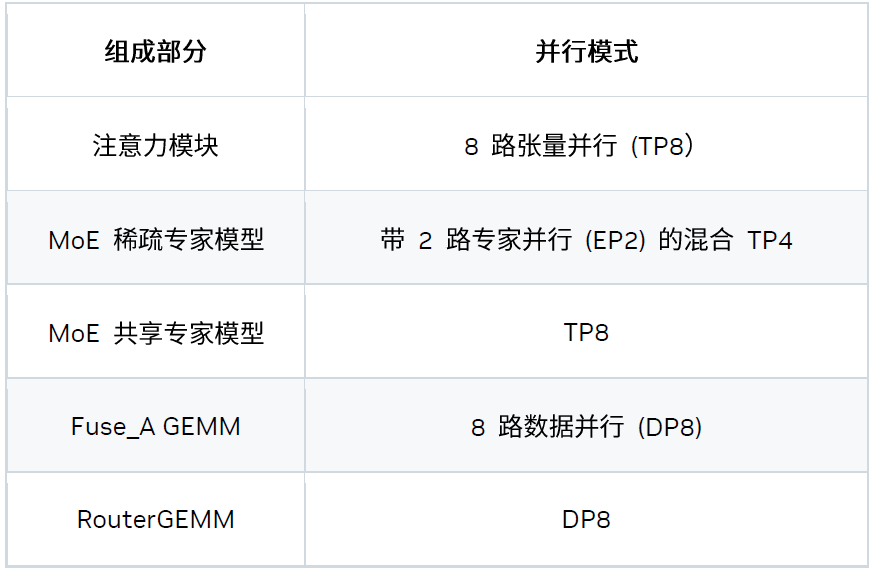
四、并行策略
我们还在 8 个 Blackwell GPU 上尝试并引入了混合并行策略。具体而言,该延迟场景的最佳策略为 “TP8EP2”,其定义如下:
五、一图整合
现在,我们将所有内容整合成一张图,该图表示的是解码迭代中的一个 MoE 层。

该图片来源于 Github: Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA Blackwell GPUs 一文,若您有任何疑问或需要使用该图片,请联系该文作者
图中的模块包括:
-
输入模块:一个形状为 [m, 7168] 的 BF16 张量,其中 m 表示 token 数量(例如使用 3 个 MTP 层时 m = 4),7168 为模型的隐藏大小。
-
模块 1:Fuse_A_GEMM 拼接 WDQ、WDKV 和 WKR 的权重,以减少内核调用开销。
-
模块 2:2 个 RMSNorm 对 Q / K 张量进行归一化。这些张量可以重叠在多个流上,也可以合并成单个分组 RMSNorm。
-
模块 3:UQ_QR_GEMM 拼接 WUQ 和 WQR 的权重,以减少内核调用开销。
-
模块 4:UK_BGEMM 在批量 GEMM 中使用 WUK。为防止权重规模膨胀和产生新的加载成本,我们未加入模块 3 和 4。
-
模块 5:Concat KVCache & applyRope 合并 K / V 缓存并应用 ROPE(旋转位置编码)。
-
模块 6:genAttention 在生成阶段执行 MLA,作用类似于 num_q_heads = 128 / TP8 = 16 的 MQA
-
模块 7:UV_GEMM 执行带 WUV 权重的批量 GEMM。
-
模块 8:WO_GEMM 使用 WO 权重运行密集 GEMM。为避免增加权重加载的开销,我们未加入模块 7 和 8。
-
模块 9:融合内核将 oneshotAllReduce、Add_RMSNorm 和 DynamicQuant (BF16->NVFP4) 整合到单个内核中。
-
模块 10:routerGEMM & topK 处理路由器 GEMM (Router GEMM) 和 topK 选择。
-
模块 11:共享专家模型与模块 10 和模块 12 部分重叠。
-
模块 12:稀疏专家模型通过分组 GEMM (Grouped GEMM) 实现专家层。
-
模块 13:最终融合内核同时执行 localReduction、oneshotAllReduce 和 Add_RMSNorm 操作。
主要优化
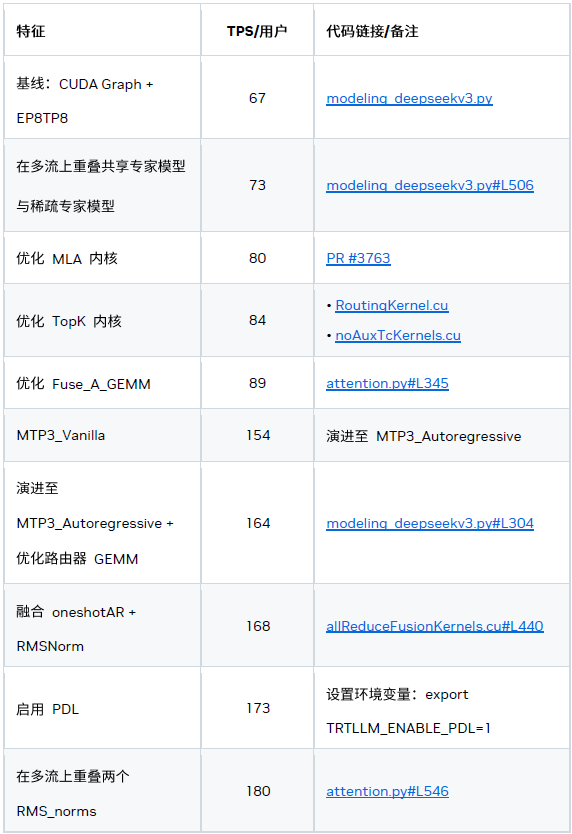
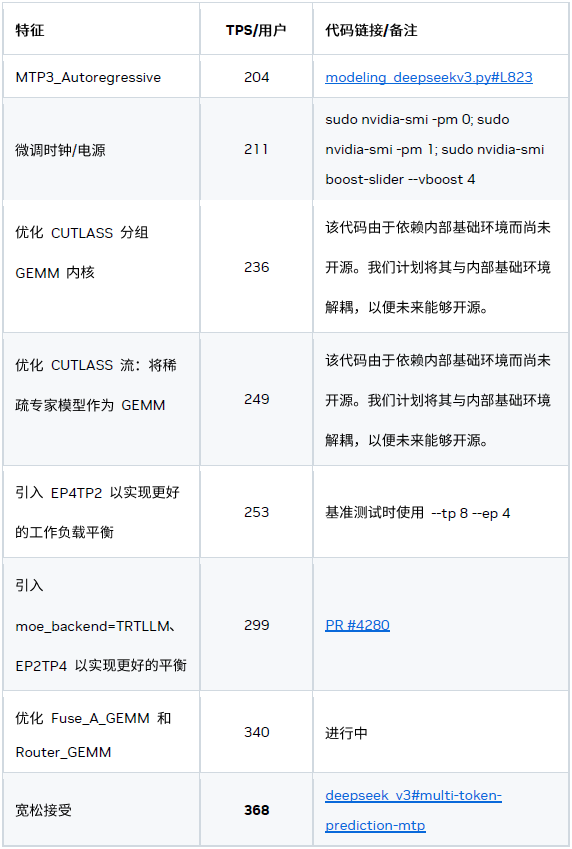
一、系统级优化
1、CUDA Graph 与可编程依赖启动
CUDA Graph 对于克服小型工作负载中的 CPU 开销必不可少,而可编程依赖启动可进一步降低内核启动延迟。
2、MTP
基于 MTP 的两种优化措施:
1) 自回归 MTP 层
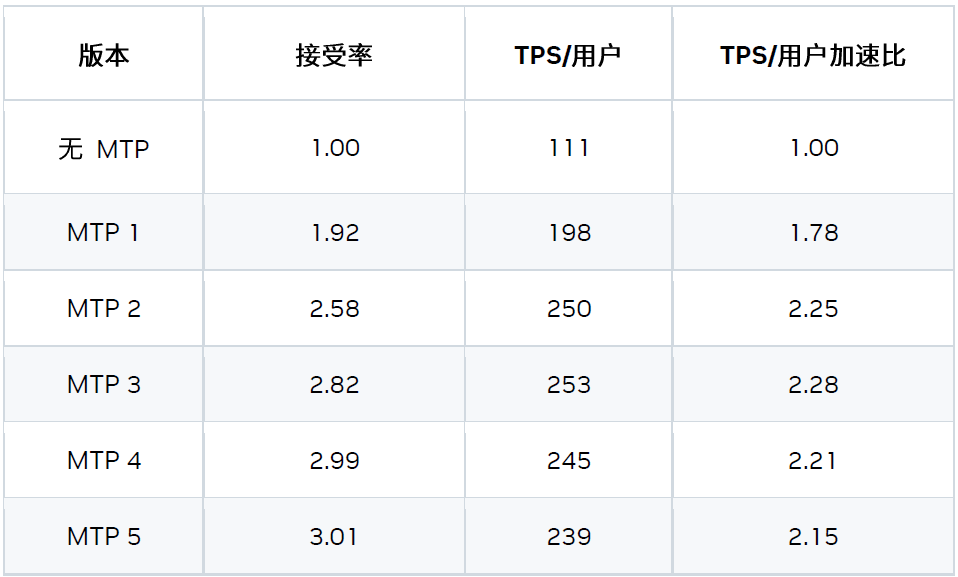
根据我们的研究结果,3x MTP 层的配置性能最佳。
2) 宽松接受验证
逻辑推理模型 (如 DeepSeek R1) 的生成过程可以分为两个阶段:思考阶段和实际输出阶段。在思考阶段,如果启用宽松接受 (Relax Acceptance) 模式,候选 token 处于候选集时即可被接受。该候选集基于 logits topN 和概率阈值生成。
-
topN:从 logits 中采样前 N 个 token。
-
概率阈值:基于 topN 个候选 token,只有概率大于 Top1 的概率减去 delta 的 token 时可保留在候选集。
在非思考阶段,我们仍采用严格接受模式。
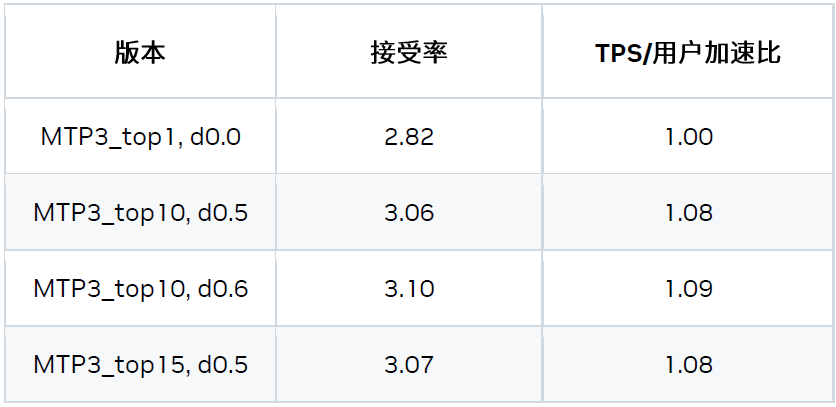
这是一种宽松的验证和比较方法,可以在对精度影响很小的情况下,提升接受率并带来加速。
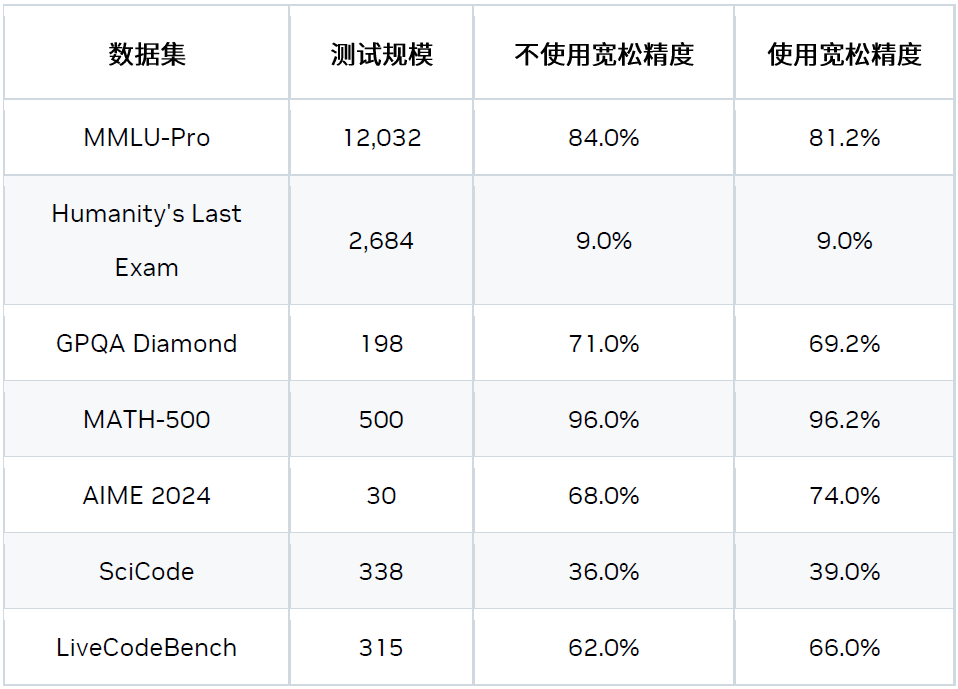
如需了解更多信息,请访问:
multi-token-prediction-mtp
3、多流
我们引入了基于多流的优化措施以隐藏部分内核的开销,例如:
-
将共享专家模型与稀疏专家模型重叠
-
将 Concat_KVCache 内核与 GEMM 重叠
稀疏专家模型作为 GEMM (仅当 moe_backend=CUTLASS 时有效)
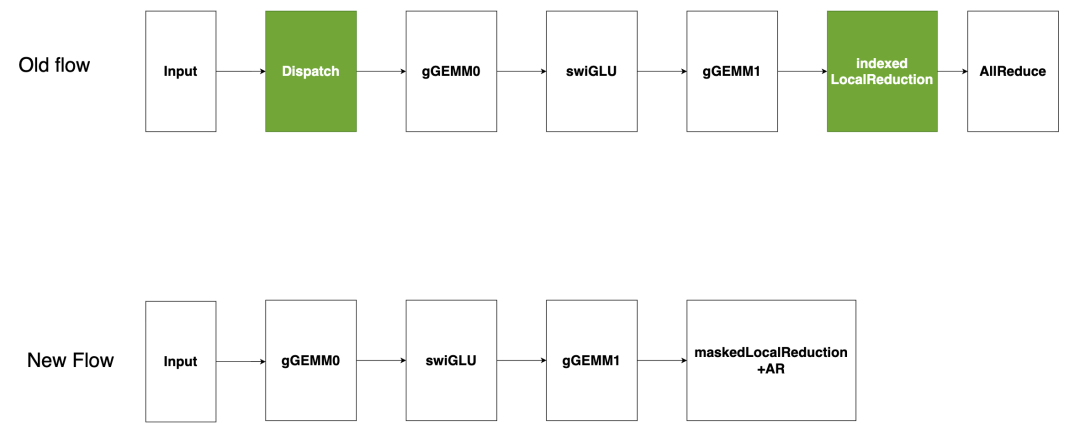
该图片来源于 Github: Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA Blackwell GPUs 一文,若您有任何疑问或需要使用该图片,请联系该文作者
现有的基于 CUTLASS 的稀疏专家模型流(如图所示)将输入的 token 分发到指定的专家模型,然后在每个专家模型的输出上进行索引式的局部归约,最后进行全局AllReduce。分发和索引局部归约在低延迟场景下会产生高开销。为解决此问题,我们提出将“稀疏专家模型作为 GEMM”处理,即将所有 token 发送至每个激活的专家模型,并在局部归约前屏蔽不需要的输出。由于分组 GEMM 受显存限制,冗余 token 产生的额外计算开销几乎没有影响,有效避免了昂贵的分发,同时减少开销。
4、重新平衡稀疏专家模型
稀疏专家模型常用的并行化策略有两种:专家并行 (EP) 和张量并行 (TP)。专家并行 (EP) 将每个专家模型分配到独立的 GPU,以此实现高显存和计算效率。但 token 放置依赖于数据,导致 GPU 间工作负载分布不均,并在 MoE 模块后的 AllReduce 步骤中显示额外开销。张量并行 (TP) 将每个专家模型均匀划分到多个 GPU,虽平衡了工作负载,但却牺牲了数学 / 显存效率。
-
混合 ETP
结合 EP / TP 的混合方法可缓解上述问题。实验结果表明,TP4EP2 配置在实际中表现最佳。
-
智能路由器
另一方案是将所有专家模型权重存储在由 4 个 GPU 组成的集群中,随后将其复制到另一个 4 GPU 集群,智能路由器可将 token 动态地分配到各集群。该设计在不显著影响本地显存和计算效率的前提下,保持了工作负载分布的平衡。
二、内核级优化
1、注意力内核
我们开发了定制的 MLA 注意力内核,以便更好地使用 GPU 资源应对延迟场景。
2、分组 GEMM
-
CUTLASS 后端(默认后端)
我们的默认 MoE 后端基于 CUTLASS,该后端具有灵活性和稳定性,但可能不是最佳的性能方案。
-
TensorRT-LLM 后端
另一个 MoE 后端是 TensorRT-LLM,其性能更优。我们正在努力提高其灵活性和稳定性,未来将作为延迟场景中分组 GEMM 计算的默认后端。
3、通信内核
对于小规模消息,受常规 NCCL 延迟影响的 AllReduce 内核效率低下,为此我们开发了一款定制化的一次性 AllReduce 内核。该内核通过先模仿初始广播,然后进行局部归约的方式,利用 NVSwitch 的强大硬件能力在最小延迟场景中实现了更优的性能。
4、密集 GEMM 优化
我们重点优化两种密集 GEMM:Fuse_A_GEMM 和 RouterGEMM。因为这两种 GEMM 占据了大部分执行时间、显存效率低下且难以分片(两者均基于 DP)。
-
Fuse_A_GEMM
我们开发了一个定制的 Fuse_A_GEMM,通过将大部分权重预先载入到共享显存(通过 PDL 实现并与 oneshot-AllReduce 重叠),大幅提升了性能。当 num_tokens < 16 时,该内核性能较默认的 GEMM 实现有明显提升。
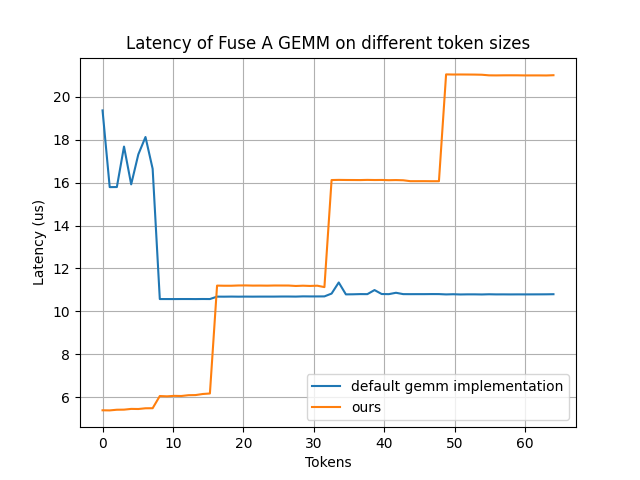
该图片来源于 Github: Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA Blackwell GPUs 一文,若您有任何疑问或需要使用该图片,请联系该文作者
-
RouterGEMM
我们通过使用内部的 AI 代码生成器,自动生成经过优化的 RouterGEMM 内核。在 num_tokens ≤ 30 时,该内核性能较默认的 GEMM 实现有显著提升。
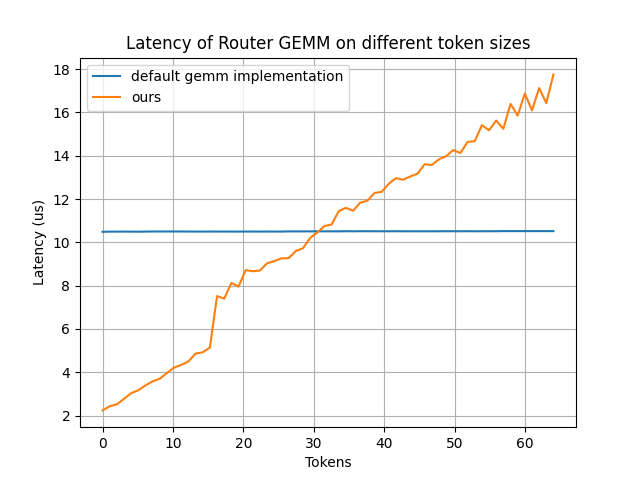
该图片来源于 Github: Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA Blackwell GPUs 一文,若您有任何疑问或需要使用该图片,请联系该文作者
5、内核融合
为了减少最小延迟场景中额外的全局显存写读开销,内核融合必不可少。我们目前支持以下融合模式:
-
将两个重叠的 RMS_Norm 融合成一个 GroupedRMSNorm
-
将 (LocalReduction) + AR + RMS_Norm + (Dynamic_Quant_BF16toNVFP4) 融合成一个内核
-
将 Grouped GEMM_FC1 + 点激活 (当 moe_backend=TRTLLM 时) 融合成一个内核
如何复现
https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/Best_perf_practice_on_DeepSeek-R1_in_TensorRT-LLM.md#b200-min-latency
需要注意的是,宽松接受模式是 Deepseek-R1 模型的特有模式。若要启用该模式,需在准备基准数据集时设置 add_generation_prompt = True,示例代码如下:
input_ids= tokenizer.encode(tokenizer.apply_chat_template(msg, tokenize=False, add_generation_prompt=True), add_special_tokens=False)
还需在 speculative_config 中设置 use_relaxed_acceptance_for_thinking: true, relaxed_topk: 10 和 relaxed_delta: 0.6。
后续工作
-
增加融合
-
增加重叠
-
增加对注意力内核的优化
-
增加对 MTP 的研究
结语
在延迟敏感型应用中突破 DeepSeek R1 的性能极限是一项非凡的工程。本文详细介绍的优化措施是整个 AI 技术栈各个领域的协作成果,涵盖了内核级优化、运行时增强、模型量化技术、算法改进以及系统性能分析与调优。希望本文介绍的技术和最佳实践,能够帮助开发者社区在任务关键型 LLM 推理应用中更充分地发挥 NVIDIA GPU 的性能。
-
NVIDIA
+关注
关注
14文章
5315浏览量
106546 -
gpu
+关注
关注
28文章
4956浏览量
131440 -
大模型
+关注
关注
2文章
3165浏览量
4114 -
LLM
+关注
关注
1文章
326浏览量
865 -
DeepSeek
+关注
关注
2文章
800浏览量
1796
原文标题:突破延迟极限:在 NVIDIA Blackwell GPU 上优化 DeepSeek-R1 的性能
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
如何使用OpenVINO运行DeepSeek-R1蒸馏模型

RK3588开发板上部署DeepSeek-R1大模型的完整指南
行芯完成DeepSeek-R1大模型本地化部署
Infinix AI接入DeepSeek-R1满血版
了解DeepSeek-V3 和 DeepSeek-R1两个大模型的不同定位和应用选择
超星未来惊蛰R1芯片适配DeepSeek-R1模型
OPPO Find N5将接入DeepSeek-R1,可直接语音使用
AIBOX 全系产品已适配 DeepSeek-R1

软通动力天璇MaaS融合DeepSeek-R1,引领企业智能化转型
deepin UOS AI接入DeepSeek-R1模型
芯动力神速适配DeepSeek-R1大模型,AI芯片设计迈入“快车道”!

网易有道全面接入DeepSeek-R1大模型
原生鸿蒙版小艺App上架DeepSeek-R1, AI智慧体验更丰富
中软国际JointPilot平台上线DeepSeek-R1模型
对标OpenAI o1,DeepSeek-R1发布





 工商网监
工商网监
评论