 计算精度对比:FP64、FP32、FP16、TF32、BF16、int8
计算精度对比:FP64、FP32、FP16、TF32、BF16、int8

在当今快速发展的人工智能领域,算力成为决定模型训练与推理速度的关键因素之一。为了提高计算效率,不同精度的数据类型应运而生,包括FP64、FP32、FP16、TF32、BF16、int8以及混合精度等。本文将浅显易懂地介绍这些精度计算方式及其差别。
什么是精度?
精度,是数据表示的一个重要参数,它决定了数据的准确性。在计算机科学中,精度通常与数值表示的位数有关。对于浮点数,精度取决于浮点数的存储方式,即占用的比特数(bits)越多,精度越高。
为了更直观的理解,举个例子:假设你每秒钟赚到的钱是1块钱,那一个月的收入是1*60*60*24*30=216000,如果每秒钟赚到1块1呢,那一个月的收入是237600,就一个1毛钱的小数点,让你月收入少了1万多,这就是精度不同导致的差异。
另外一个典型的例子是π,常用3.14表示,但是如果要更高精度,小数点后面可以有无数位。
为什么需要不同的精度?
为什么要有这么多精度,因为成本和准确度。
都知道精度高肯定更准确,但是也会带来更高的计算和存储成本。较低的精度会降低计算精度,但可以提高计算效率和性能。所以多种不同精度,可以让你在不同情况下选择最适合的一种。在人工智能领域,不同的应用场景对精度的需求各不相同。例如,在深度学习模型的训练中,需要大量的数据进行计算,如果精度过高,会导致计算量巨大,训练时间延长;而如果精度过低,则可能影响模型的准确性。因此,为了在保证准确性的前提下提高计算效率,就需要使用不同的精度。
精度分类及对比算力精度指的是计算过程中使用的数值精度。分为浮点计算(半精度、单精度、双精度)和整型计算,不同精度的运算代表了在计算中使用不同的位数,影响了计算速度、精度和能耗。
FP64
双精度浮点数,占用64位空间。常用于大规模科学计算、工程计算、金融分析等对高精度有严格要求的算法领域。
FP32
单精度浮点数,占据32位空间。相较于双精度浮点数,其存储空间较小,精度也略低,一般应用于科学计算、图形渲染、深度学习训练和推理等。在大多数通用计算任务和科学计算中,FP32被广泛使用。它在性能与精度之间提供了较好的平衡,适合需要较高精度的计算任务。
FP16
半精度浮点数,仅占用16位空间。存储空间大幅减小,精度进一步降低,通常在模型训练过程中用于参数和梯度的计算,应用于深度学习推理、图形渲染、某些嵌入式系统等,特别是在需要减少内存和计算资源消耗时。
TF32
一种由NVIDIA引入的用于深度学习计算的格式,是使用 Tensor Core 的中间计算格式,它在内部使用FP32进行计算,但在存储和通信时使用FP16。
INT8
是8位整数运算,通常用于量化后的深度学习模型推理。INT8的表示范围进一步缩小,但其计算速度非常快,且能显著降低能耗和内存占用,广泛应用于需要高效能效比的应用场景,如边缘计算、车辆和移动设备上的AI推理。
在人工智能模型训练和推理中,根据模型的复杂度和性能要求,选择合适的算力精度。例如,如果您的模型对精度要求不高,那么可以使用半精度(FP16)或单精度(FP32)浮点计算,以加快计算速度;如果精度要求非常高,那么可能需要使用双精度(FP64)浮点计算。
-
人工智能
+关注
关注
1809文章
49151浏览量
250608 -
算力
+关注
关注
2文章
1220浏览量
15722
发布评论请先 登录
【算能RADXA微服务器试用体验】+ GPT语音与视觉交互:2,图像识别
迅为RK3576开发板适用于ARM PC、边缘计算、个人移动互联网设备及其他多媒体产品
Optimum Intel / NNCF在重量压缩中选择FP16模型的原因?
迅为iTOP-RK3576开发板/核心板6TOPS超强算力NPU适用于ARM PC、边缘计算、个人移动互联网设备及其他多媒体产品
将Whisper大型v3 fp32模型转换为较低精度后,推理时间增加,怎么解决?
实例!详解FPGA如何实现FP16格式点积级联运算
详解天线系统解决方案中的FP16格式点积级联运算
推断FP32模型格式的速度比CPU上的FP16模型格式快是为什么?
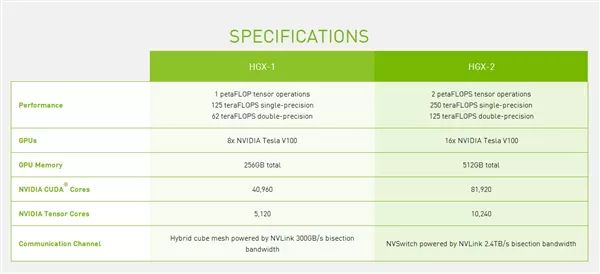
NVIDIA宣布推出新一代计算平台“HGX-2”
NVIDIA TensorRT的数据格式定义
摩尔线程多功能GPU产品迭代创新实现的又一次跨越
英伟达h800和h100的区别
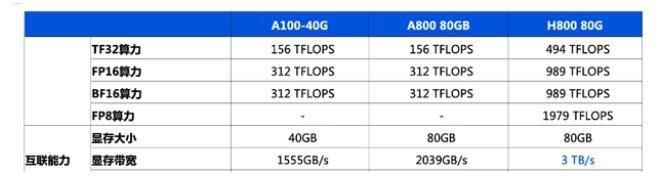
FP8在大模型训练中的应用

英伟达A100和H100比较






 工商网监
工商网监
评论