 单节点Elasticsearch+Filebeat+Kibana安装指南
单节点Elasticsearch+Filebeat+Kibana安装指南

1、准备环境
声明需要jdk17依赖,自行安装配置
| ip | cpu | 内存 | 服务 | 环境 |
| 192.168.25.149 | 2 | 2G | elasticsearch+kibana | centos7+jdk17 |
| 192.168.25.148 | 2 | 2G | filebeat | centos7+jdk17 |
#第一部分在192.168.25.149安装es
2、配置yum源
# 配置 Elastic 官方仓库 sudorpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch sudotee/etc/yum.repos.d/elastic.repo <
3、安装 配置Elasticsearch
sudoyum install -y elasticsearch # 配置 Elasticsearch sudovim /etc/elasticsearch/elasticsearch.yml # 集群名称 cluster.name: elk-cluster # 节点名称 node.name: node-1 # 数据和日志存储路径 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch # 网络设置 network.host: 192.168.25.149 http.port: 9200 # 发现设置 discovery.type: single-node # 配置内存 #因为我的服务器只有 2GB 内存,建议修改 JVM 堆大小: sudovim /etc/elasticsearch/jvm.options -Xms512m -Xmx512m
4、启动
# 启动服务 sudosystemctl daemon-reload sudosystemctlenableelasticsearch sudosystemctl start elasticsearch #关闭防火墙 systemctl stop firewalld # 验证服务 curl http://192.168.25.149:9200 #正确结果 [root@localhost elasticsearch]# curl http://192.168.25.149:9200 { "name":"node-1", "cluster_name":"ELK-cluster", "cluster_uuid":"CAS4Rr6NSTmwMW5lK5rJpQ", "version": { "number":"7.17.28", "build_flavor":"default", "build_type":"rpm", "build_hash":"139cb5a961d8de68b8e02c45cc47f5289a3623af", "build_date":"2025-02-20T0931.349013687Z", "build_snapshot":false, "lucene_version":"8.11.3", "minimum_wire_compatibility_version":"6.8.0", "minimum_index_compatibility_version":"6.0.0-beta1" }, "tagline":"You Know, for Search" }
#第二部分在192.168.25.149安装kibana
1、# 安装 配置Kibana
sudoyum install -y kibana # 配置 Kibana sudovim /etc/kibana/kibana.yml server.port: 5601 server.host:"192.168.25.149" elasticsearch.hosts: ["http://192.168.25.149:9200"] i18n.locale:"zh-CN"#中文
2、启动
# 启动 Kibana sudosystemctlenablekibana sudosystemctl start kibana
#第三部分在192.168.25.148 安装filebeat
1、配置yum源
# 配置 Elastic 官方仓库 sudorpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch sudotee/etc/yum.repos.d/elastic.repo <
2、安装配置filebeat
#声明 我在本地启动了一个java服务,收集日志文件,你们可以把路径配置其它服务的日志,
比如服务器本身/var/log/message 等等
# 配置 Filebeat sudovim /etc/filebeat/filebeat.yml filebeat.inputs: # 配置输入源,用于收集日志数据 -type:log enabled:true paths: - /usr/loca/project/wcc/logs/info.log #日志来源 tags: ["info"] # 为info日志添加标签 fields: logtype: info # 定义日志类型为info fields_under_root:true# 将字段添加到根级别 -type:log enabled:true paths: - /usr/loca/project/wcc/logs/error.log #日志来源 tags: ["error"] # 为error日志添加标签 fields: logtype: error # 定义日志类型为error fields_under_root:true output.elasticsearch: # 配置输出到Elasticsearch hosts: ["192.168.25.149:9200"] # 指定Elasticsearch主机和端口 indices: - index:"wcc-info-%{+yyyy.MM.dd}" when.equals: logtype:"info"# 当日志类型为info时,使用指定的索引模式 - index:"wcc-error-%{+yyyy.MM.dd}" when.equals: logtype:"error"# 当日志类型为error时,使用指定的索引模式 setup.template.name:"wcc"# 设置模板名称为wcc setup.template.pattern:"wcc-*"# 设置模板匹配模式为wcc-* setup.ilm.enabled:false# 禁用索引生命周期管理
3、启动
sudosystemctlenablefilebeat sudosystemctl start filebeat
#第四部分 配置 Kibana 索引模式
1、打开浏览器访问 Kibana:http://192.168.25.149:5601
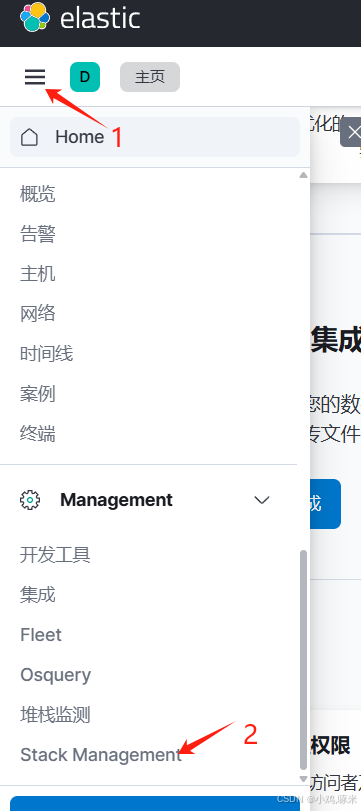
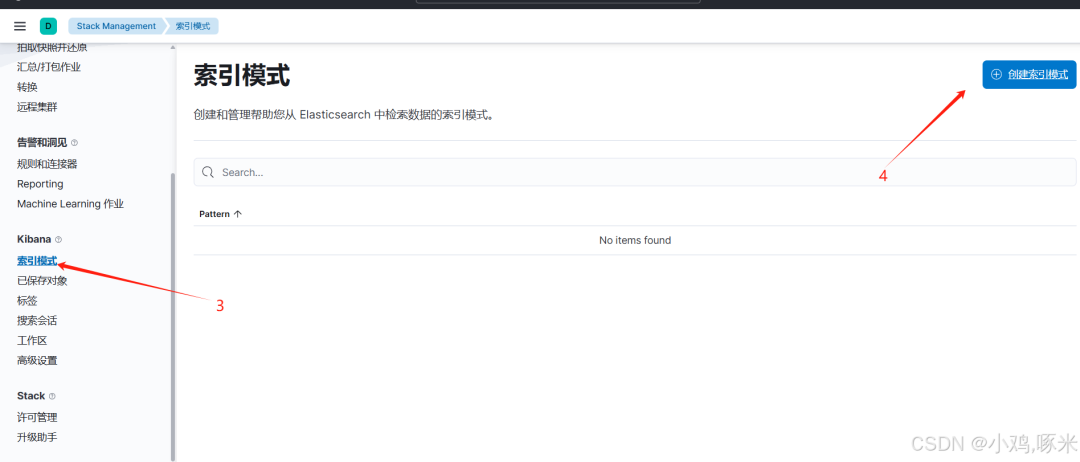
2、进入 "Stack Management" -> "Index Patterns"
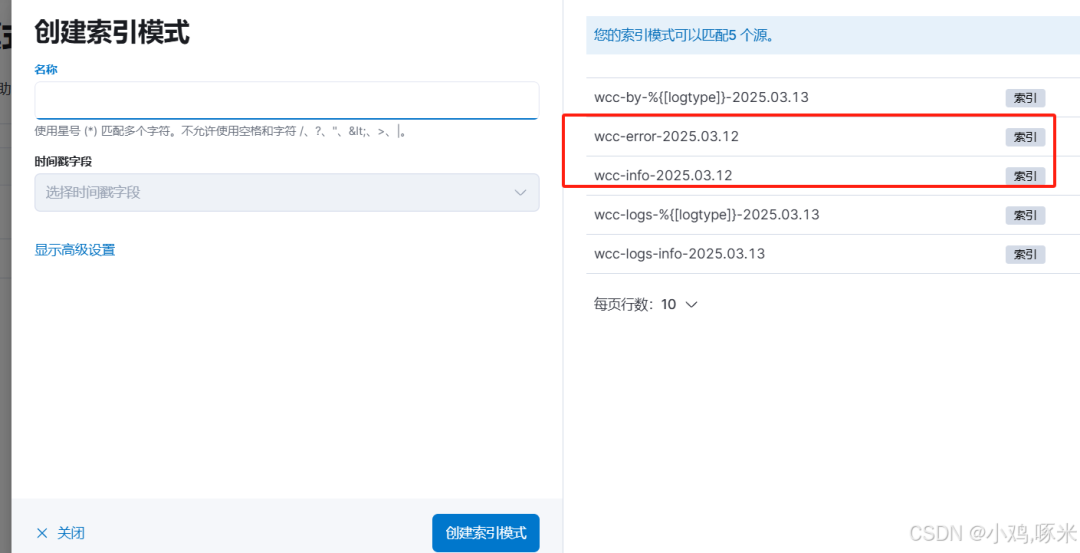
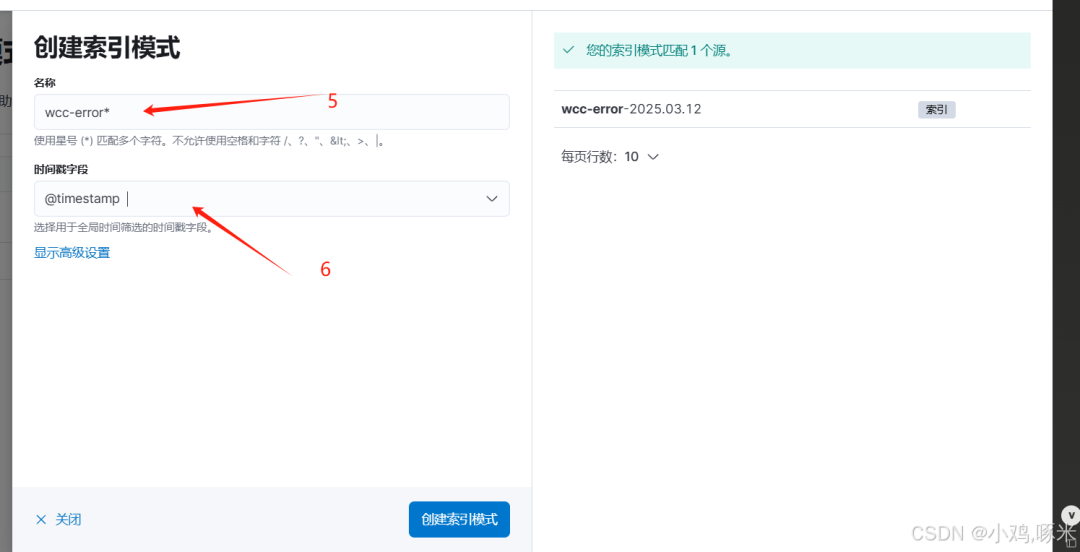
3、创建索引模式wcc-*
4、选择时间字段@timestamp
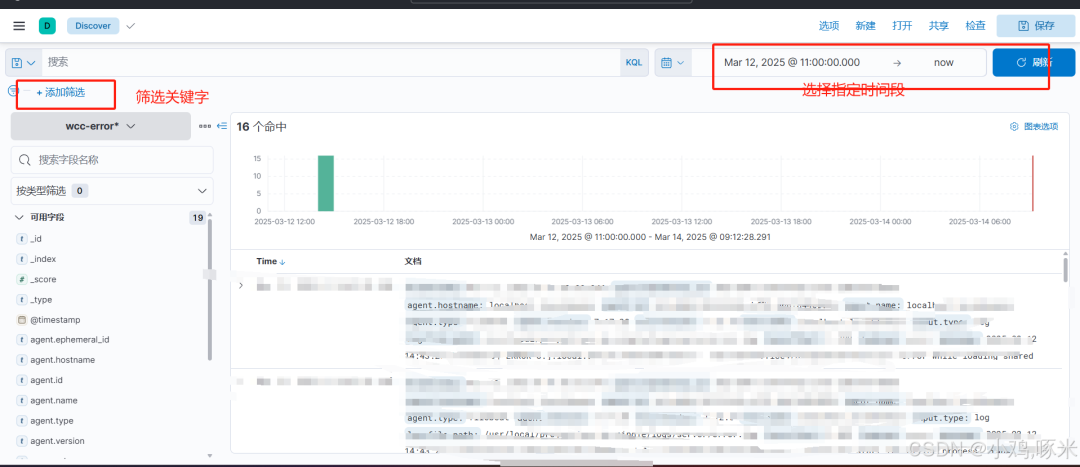
看到我们索引创建完成
日志分析仪表板
DISCOVER
这样就是一整套的安装与配置,还需要结合实际的工作情况来使用
添加仪表盘,可视化图可自行搜素学习
如果你觉得对你有帮助就点个赞
链接:https://blog.csdn.net/m0_52454621/article/details/146248197?spm=1001.2014.3001.5502
-
服务器
+关注
关注
13文章
9826浏览量
88224 -
内存
+关注
关注
8文章
3128浏览量
75364 -
集群
+关注
关注
0文章
113浏览量
17461
原文标题:零基础搞定EFK!单节点Elasticsearch+Filebeat+Kibana手把手安装指南,有手就行!
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
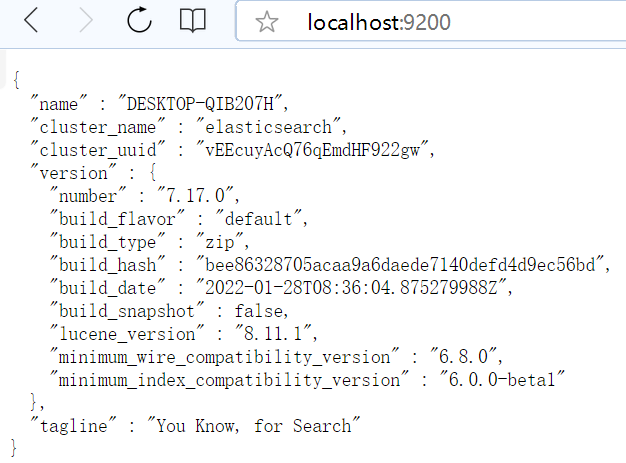
Linux安装elasticsearch-head
linux安装配置ElasticSearch之源码安装
在linux上安装部署ElasticSearch的详细操作
通过使用Metricbeat收集系统数据及Nginx服务数据
图解ElasticSearch的底层工作原理
Kubernetes如何在各个服务器上搜集日志后传输给Logstash
ElasticSearch是什么?应用场景是什么?
Elasticsearch保姆级入门
Elasticsearch 再次开源

构建高效搜索解决方案,Elasticsearch & Kibana 的完美结合





 工商网监
工商网监
评论