 构建大规模Simulink模型的标准化最佳实践
构建大规模Simulink模型的标准化最佳实践

| 作者 Brad Hieb 和 Erick Saldana Sanvicente,MathWorks
(本文采用了机器翻译)
随着系统规模和复杂性的增长,工程团队面临着一系列在小规模上不存在的全新挑战。
规模的大幅扩大几乎总是需要方法的转变,不仅是范围上的,而且是种类上的。此原则也适用于使用基于模型的设计处理 Simulink 模型时。如果不遵循最佳实践,从简单的概念验证模型过渡到具有数十万个块的大规模模型时,一系列问题开始出现,包括模型架构、数据管理、接口、文件管理和仿真性能不佳的问题。这些大型模型的构成要素可能很小,通常由不同的个人、团队甚至部门开发。当有标准化并且遵循最佳实践时,这些模型可以顺利扩大规模。
本文介绍了一组最佳实践,用于解决在 Simulink 中处理大型复杂模型时经常遇到的挑战。由于这个主题本身相当广泛,这里的目标不是提供详细的规定性指导,而是介绍每种最佳实践的基础知识以及可供探索的其他资源的链接,以便更深入地了解如何应用它。
使用模型引用进行模型组件化
当我们与客户合作时,经常会看到大型模型缺乏有意义的组件化。团队从一个简单的模型开始测试想法;随着时间的推移,新的元素或特性被添加,所有的工作都在一个单一的、整体的模型文件
中完成,而这个模型文件很快就会变得难以处理。在 Simulink 中,有几种方法可以组件化大型模型,最佳方法将取决于所考虑的具体用例。例如,如果一个团队只是想直观地组织一组块或组件,他们可能会选择模型内虚拟子系统。对于想要创建广泛使用且不经常更改的实用程序的其他团队来说,链接子系统(或库)是一个更好的选择。如果目标是开发或仿真一个组件作为独立模型,那么模型参考是最好的方法。
对于大规模模型来说,模型引用也是组件化的关键。原因之一是 Simulink 中的模型引用使团队能够将组件作为独立模型并行开发。每个组件都具有完整的功能且可仿真,并保存在自己的 SLX 文件中,因此每个团队都可以独立工作而不会干扰其他团队的工作 - 当整个设计都捕获在一个文件中时,这几乎是不可能做到的。同样重要的是,这些独立的参考模型可以放置在更大的模型内,以便于集成(图 1)。该架构可以使用参考模型的缓存实例和增量构建来减少构建时间。它还允许使用加速器和快速加速器模式,下面关于性能的部分将详细介绍。
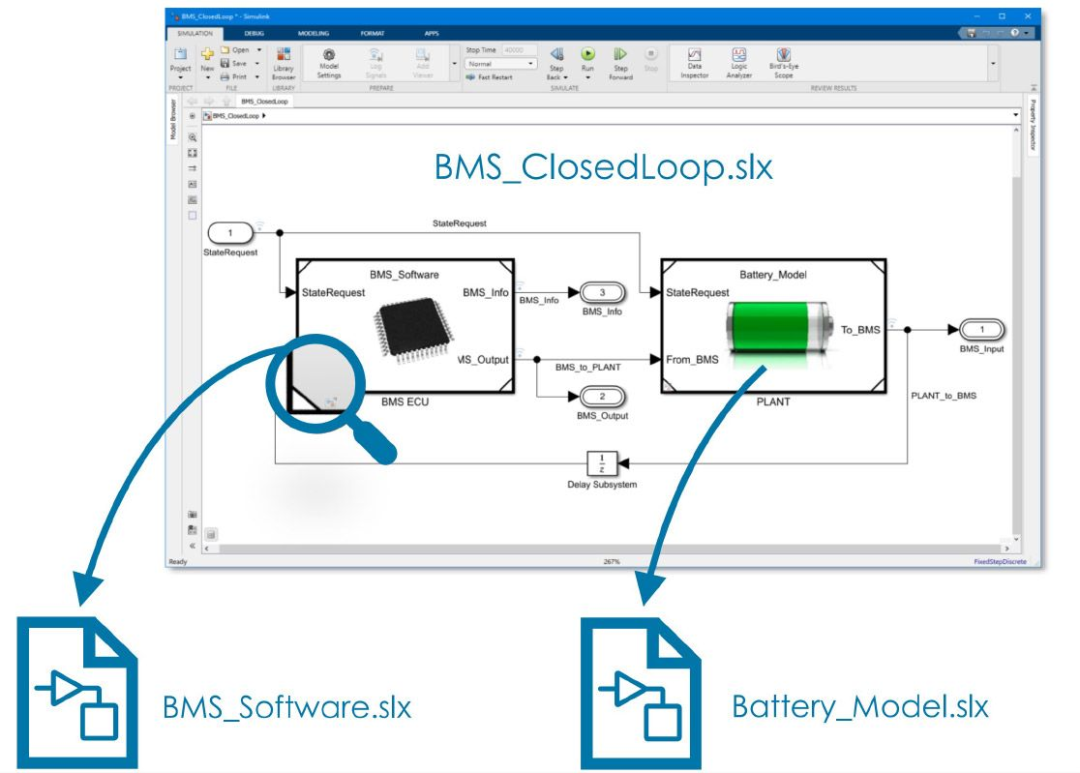
图 1. 模型 BMS_Software 和 Battery_Model 可以独立开发,然后放置(或引用)在 BMS_ClosedLoop 模型。
使用模型引用进行模型组件化
让我们重新考虑一下导致组件化问题的相同场景:一个团队从一个简单的模型开始作为早期的概念证明,然后随着时间的推移不断对其进行完善。对于一个简单的模型,许多工程师会将变量、参数和其他数据存储在基础工作区。这种方法适用于非正式工作流程、快速参数调整、快速原型设计、单一开发人员工程或需要参数普遍可见性的用例。然而,随着模型范围和复杂性的增加,依赖基础工作区进行数据管理会带来一些缺点。例如,由于每次工程师关闭会话时基础工作区都会被清除,因此必须手动保存为 MATLAB 代码 (.m) 或 MATLAB 文件 (.mat)。
数据字典比基础工作区更适合管理涉及大型模型、分布式开发或范围数据的工程数据。出现这种情况的原因有几个(见图2)。第一是数据持久化。数据以特定的文件格式保存在数据字典 (.sldd) 文件中,使团队能够独立于模型和基础工作区定义、管理和更新数据。其次,团队可以将数据分成多个字典,以进一步改善数据组织。第三,数据字典在变更跟踪工作流中运行良好,团队可以查看进行了哪些更改、何时进行更改以及由谁进行更改,甚至可以在需要时恢复到早期版本。
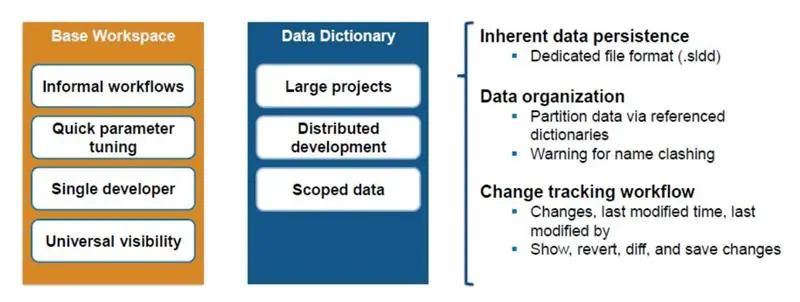
图 2. 处理大型模型时数据字典的优势。
这里需要注意的是,使用基础工作区和数据字典之间的选择并不是全有或全无的。这两种方法可以共存,因此团队可以随着时间的推移逐渐从基础工作区迁移到一个或多个数据字典。
简化与总线的接口
在组件化、分层模型中连接子系统时,最初可能看起来最直接的方法是针对从一个组件传递到另一个组件的每个元素使用单独的信号线。当然,这适用于简单的界面,但这种方法很快就会导致模型变得比必要的更复杂、更混乱、更难管理。
在 Simulink 中,总线可以通过用一条线表示一组信号(或元素)来简化界面并减少混乱,就像几根电线捆绑在一起一样。通过一个简单的例子很容易看出它的价值。考虑一个用于识别电池系统中异常情况的故障检测组件。该组件有 11 种不同的输入,包括最大和最小电池电压、最大和最小电池温度、接触器状态、电池组电压和电流以及电流限制。虽然创建具有 11 个独立输入端口的组件是可能的,但将输入分成逻辑组并为每个组使用一个总线更为清晰。例如,由于电池电压和电池温度信号均来自同一组件且彼此相关,因此将它们分组为单个四元件总线是有意义的(图 3)。显然,这是一个相对简单的例子,但它说明了如何使用总线来简化组件接口,而且更广泛地说,简化复杂模型。
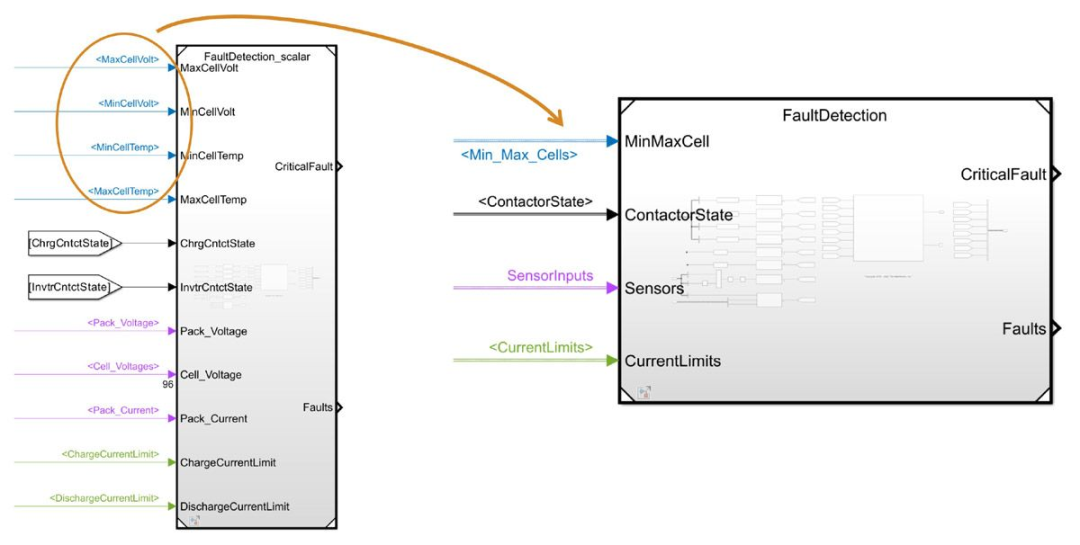
图 3. 故障检测组件已更新,使用总线而不是单独的信号作为输入。
利用工程改善文件管理
遵循迄今为止概述的最佳实践的一个副作用是必须管理的文件数量增加。当整个设计都采用单一模型时,团队需要管理的文件集相对较小,但当积极采用组件化和数据字典时,文件集就会迅速增长。如果没有文件管理策略,文件的激增就会带来问题。
在 Simulink 中工作时,团队可以使用工程来帮助自动化文件管理活动,这样他们就有更多时间花在建模、仿真和其他高价值活动上。例如,在设置工程时,团队将指定工程路径中的文件夹。当工程打开时,这些文件夹会被添加到搜索路径中(当工程关闭时,这些文件夹会被删除),以确保工程的所有用户都可以访问其中的文件。团队还可以指定用于自动设置项目环境的启动文件,以及通过撤销设置步骤(例如)来清理环境的关闭文件。此外,可以配置工程以在启动时打开常用文件并为常用任务创建快捷方式。
工程还可以帮助团队避免常见的错误。例如,在复杂的模型层次结构中,两个同名的模型文件存在于不同的目录中是很常见的。当使用工程时,工程师将看到以下警告:检测到影子文件。此外,当工程关闭时,系统会提示工程师保存任何未保存的更改,以帮助避免工作丢失。
最后,工程有助于简化源代码控制,其中刷新、提交、推送、拉取、获取等常见操作以及其他常见操作可直接从用户界面访问(图 4)。
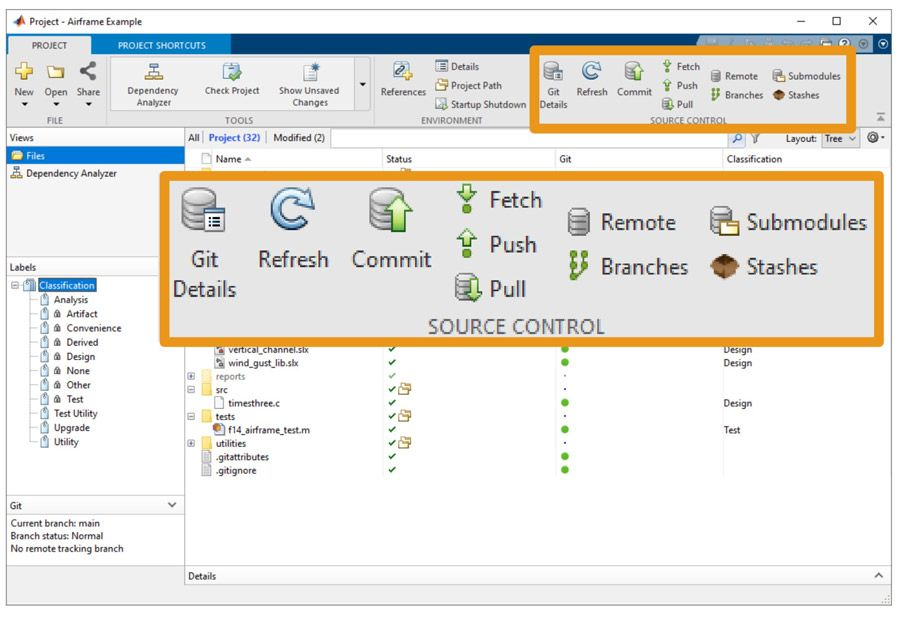
图 4. 源代码控制操作可直接从工程选项卡的源代码控制部分找到。
优化仿真性能
到目前为止我们所介绍的最佳实践主要集中于大型模型的结构及其相关的数据和文件。在与实施了这些最佳实践的客户的对话中,我们经常被问及如何提高仿真性能:“现在我们有了更好的方法来构建大型模型,我们如何才能让它们仿真得更快呢?”
有多种工具可用于提高仿真性能。作为第一步,我们建议性能顾问,它运行一系列检查来识别可能减慢仿真速度的配置设置。接下来,对于任何包含初始化 MATLAB 代码的模型(例如,在回调中),运行 MATLAB 探查器来确定 MATLAB 花费时间最多的地方是个不错的主意。Simulink 探查器评估模型执行时间并识别可能导致仿真性能不佳的问题。最后,对于使用可变步长求解器的团队,我们建议运行求解器探查工具来分析求解器行为,以识别潜在问题(例如求解器重置或极小的时间步长),并提供解决这些问题的建议。有关每种工具的指南,包括如何使用以及何时使用,请参阅排除故障并提高仿真性能指南(见表)。
已将大型模型组件化的团队可以使用加速器模式或快速加速器模式加速仿真,此种模式用生成的代码替换 Simulink 仿真中通常使用的解释代码。在模型初始化期间, Simulink 会检查缓存中是否存在已生成代码的组件。这种增量构建过程极大地减少了具有许多组件的大型模型的初始化时间,因为只有自上次仿真以来发生变化的组件才需要重建(并添加到缓存中)。
减少初始化时间的另一种方法是使用快速重启。当团队执行多次仿真运行而没有对模型进行任何结构性更改时,快速重启可以通过执行仿真而无需编译模型并每次终止仿真来加快该过程。相反,在第一次仿真时,模型被编译和初始化,然后在每次后续仿真中捕获模型操作点的快照(图 5)。
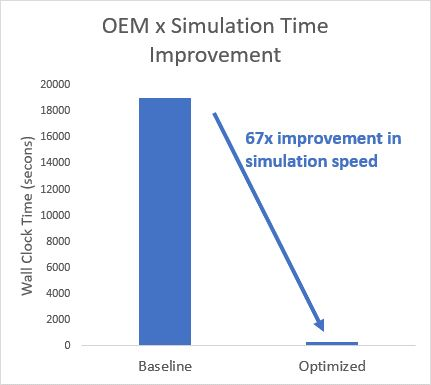
图 5. 优化模型以实现更快的仿真。
总之,当工程团队应对扩展 Simulink 模型的复杂性时,遵循最佳实践变得至关重要。本文概述了模型组件化、数据管理和性能优化的基本策略,强调了结构化方法对模型开发的重要性。通过利用性能顾问、MATLAB 探查器和求解器探查工具等工具,团队可以增强仿真性能并提高生产力。这些实践确保大型模型仍然可管理、高效且适应性强。随着基于模型的设计领域不断发展,这些指南将帮助团队构建强大的模型,以满足日益复杂的工程挑战的需求。为了进一步探索,我们鼓励读者参与本文重点介绍的额外资源和培训机会。
本文的内容基于我们在 MathWorks 北美汽车会议上发表的演讲,题为“从组件到复杂系统构建大型模型的最佳实践”(请可以点击“阅读原文”观看此英语演讲)。
正如我们一开始所说的,这是一个庞大的话题,无法在一篇文章或一次演讲中详尽地涵盖。欢迎您报名我们 2025 年 5 月在上海和北京召开的 MATLAB EXPO 中国用户大会,关注我们的建模、仿真、测试和实现分会场与汽车专场分会场演讲,或者来现场与我们的专家进行面对面的交流。
-
matlab
+关注
关注
189文章
3004浏览量
234540 -
Simulink
+关注
关注
22文章
544浏览量
64221 -
模型
+关注
关注
1文章
3531浏览量
50570
原文标题:构建大规模 Simulink 模型的标准化最佳实践
文章出处:【微信号:MATLAB,微信公众号:MATLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践
【大规模语言模型:从理论到实践】- 每日进步一点点
EPON标准化进展
大规模特征构建实践总结
EPON技术的标准化与测试
NVIDIA联合构建大规模模拟和训练 AI 模型
部署Linux的最佳实践探索
使用Ansible构建虚拟机部署Linux的最佳实践
大规模语言模型的基本概念、发展历程和构建流程






 工商网监
工商网监
评论