 科大讯飞深度解析DeepSeek-V3/R1推理系统成本
科大讯飞深度解析DeepSeek-V3/R1推理系统成本

本篇分析来自科大讯飞技术团队,深度解析了DeepSeek-V3 / R1 推理系统成本,旨在助力开发者实现高性价比的MoE集群部署方案。感谢讯飞研究院副院长&AI工程院常务副院长龙明康、AI工程院AI云平台研发部总监李珍松、讯飞星辰MaaS团队的研究对本文的贡献。
一、分析团队背景简介
分析团队来自科大讯飞星辰MaaS团队,从语音小模型时代到认知大模型时代,积累了丰富的大规模AI推理服务集群优化及运营经验,也支撑了国内首个全国产万卡算力训推集群的上线。
二、分析目的
在MaaS赛道中,大家受益于DeepSeek-V3/R1开源的壮举,但也面临着成本方面的压力
由于DeepSeek未开源推理服务器的整体集群方案以及公开运营的更多细节,大部分MaaS产商的性能/成本优化可能远不及DeepSeek当前优化的水平,我们希望通过更细节的过程分析,使得性能/成本综合优化方向更加清晰,结合DeepSeek开源的高性能库,更快实现高性价比的MoE集群部署方案
本文力求从应用视角计算估算相关数据,方便大家参考,由于存在大量估算,难免存在错误,请大家指正
DeepSeek原文链接,本文中的“原文”特指该链接内容
三、影响成本的关键因素
快速理解DeepSeek MoE推理逻辑架构
我们将DeepSeek MoE系统工程架构类比成医院就医问诊流程架构,方便大家理解。
MoE
依靠“专家”机制激活参数更小,更便宜
Prefill与Decode分离,计算更高效
KVCache缓存降低重复上下文计算
从单机到几十机,负载均衡调度复杂性上升,既要降低用户响应时间,又要提升系统吞吐率,实现低成本,还要保障系统的可靠性(大专家EP并行工程关键难点)
医院
不用花钱看更贵的“全科医生”,看个别“专科医生”
问诊和医技流程分离,流程更高效
历史电子病历、检查报告,减少重复检查
从全科室到多专科室,预约导诊分流复杂度上升,既要缩短病人看病时间,也要提升各科室的问诊效率,实现医院的效益,还要保障关键流程有效运转
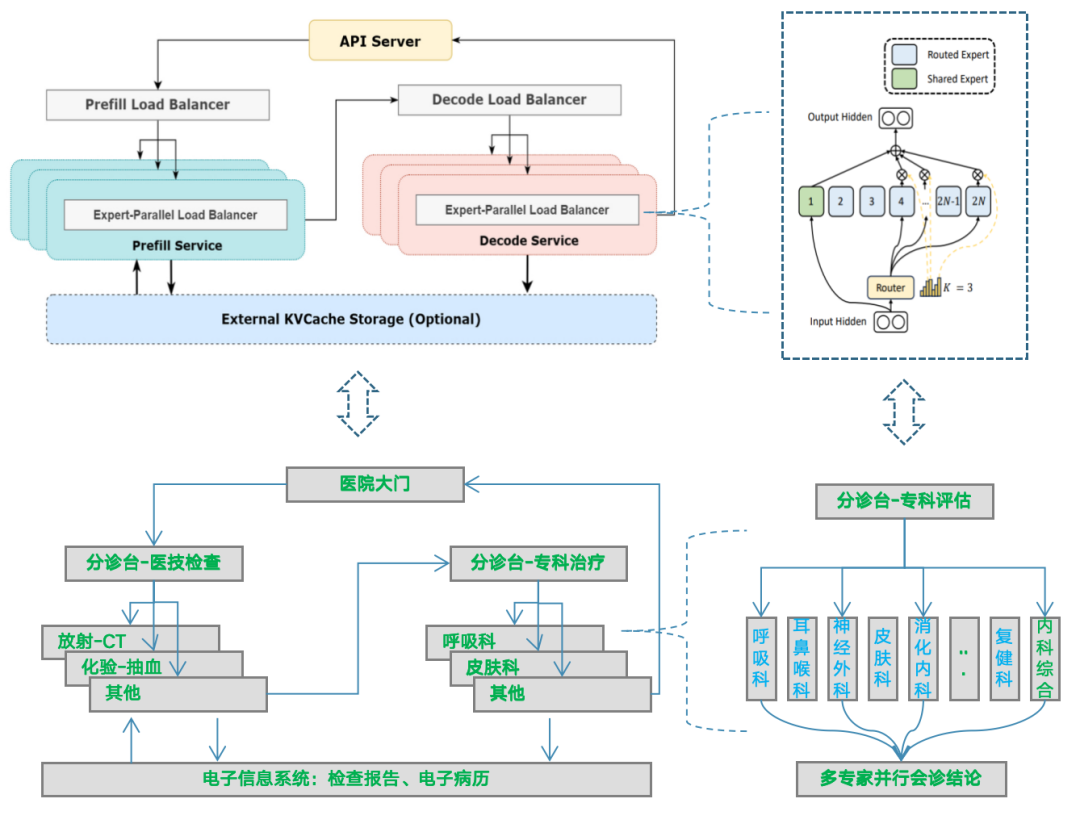
MoE推理集群部署架构概览
备注:图片来自知乎
关键概念描述
应用侧
APP:DeepSeek Web/APP端的C端用户请求
API:DeepSeek API侧的B端用户请求
DAU:日均活跃用户
total_usage:日均总使用次数
max_con:日峰值并发用户请求数
TTFT:首token响应时间
TPOT:平均每token输出的时延,从原文中得知约为50ms(平均输出速率为 20~22 tps)
系统侧
API:指为API开放所搭建的平台服务器集群,由于具有较好的边际成本递减效应,故不纳入成本关键因素分析
Prefill 与 Decode:分别对应原文中PD分离架构中的两个集群
N:M:由于我们并不清楚P与D的单元化集群配比是不是1:1,所以先假设是N:M,基于原文得知4*N+18*M=278
total_in/kvcache_rate/total_out/throughput_p/throughput_d:分别映射到原文中的总token与单机吞吐数据
运营侧
SR_Cost:原文中提到的服务器平均占用率,由原文可知SR_Cost=226.75/278≈82%
SR_Use:指服务器集群利用率,通常可以基于服务水位采样监控值曲线求面积,反算后得到利用率
SR_Available:指服务高峰期容量超限时,可用容量水位占实际用户请求水位的比例
四、关键数据项分析过程
服务器集群利用率估算
原文中提到的服务器占用率,我们首先要将这个概念转化为服务峰值容量、服务集群利用率这两个概念。
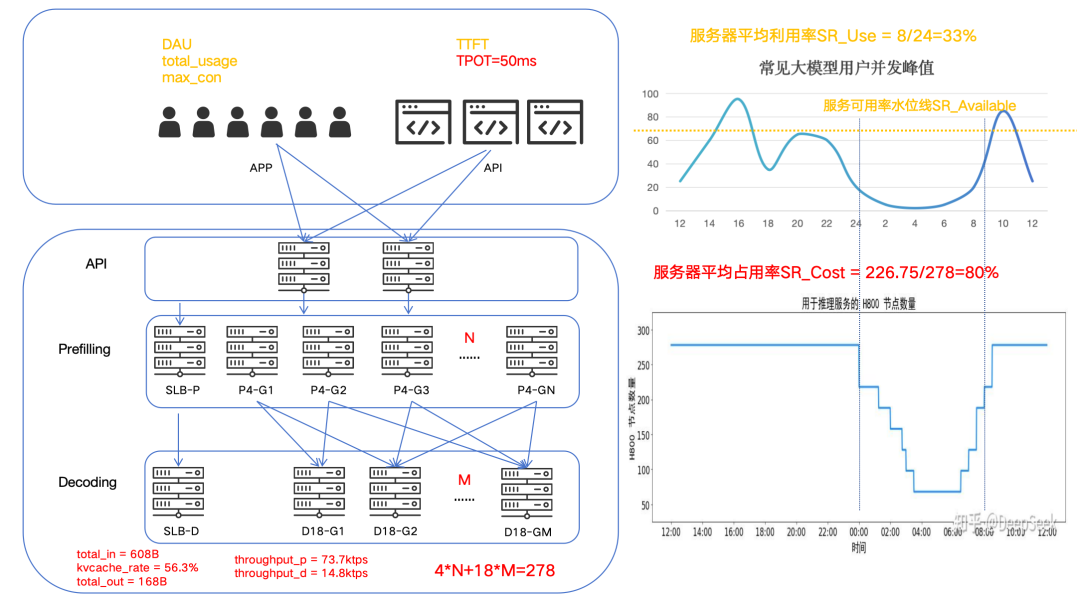
DeepSeek-V3 和 R1 推理服务占用节点总和,峰值占用为 278 个节点,平均占用 226.75 个节点(每个节点为 8 个 H800 GPU)
传统互联网应用中通常会用并发用户请求数或者QPS每秒请求任务数来量化系统的容量水位,由于AI类计算任务(如语音识别、语音合成、大模型交互)单次请求的计算时长并不固定,因此通常使用并发用户请求数来衡量系统容量水位。使用这种方式统计并实现相应的负载调度能更好的保障SLA中的关键SLO(如成功率、TTFT、TPOT等)。
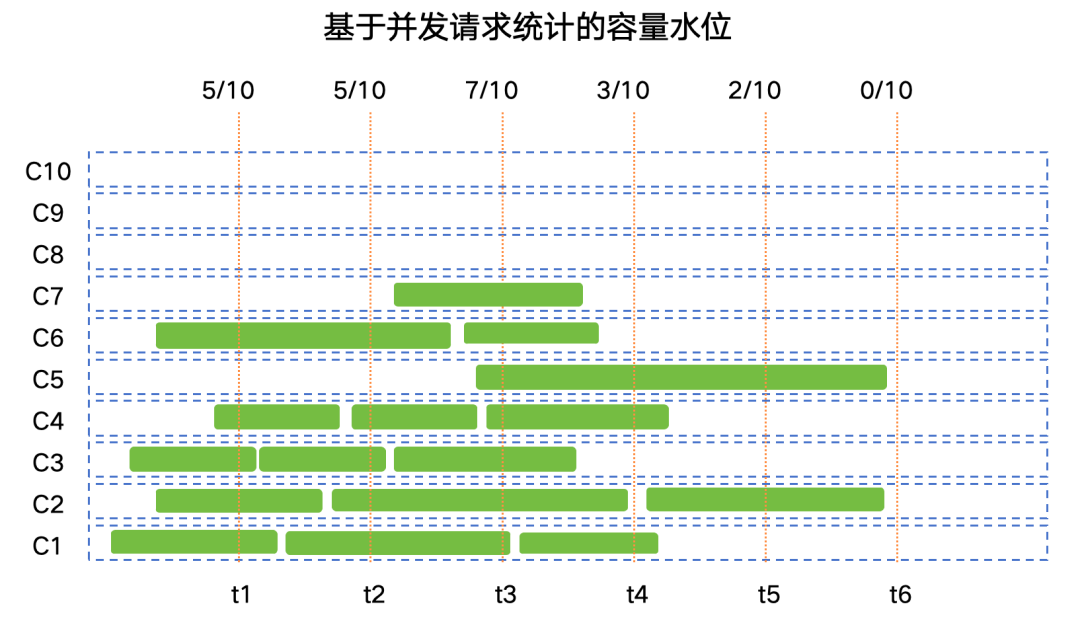
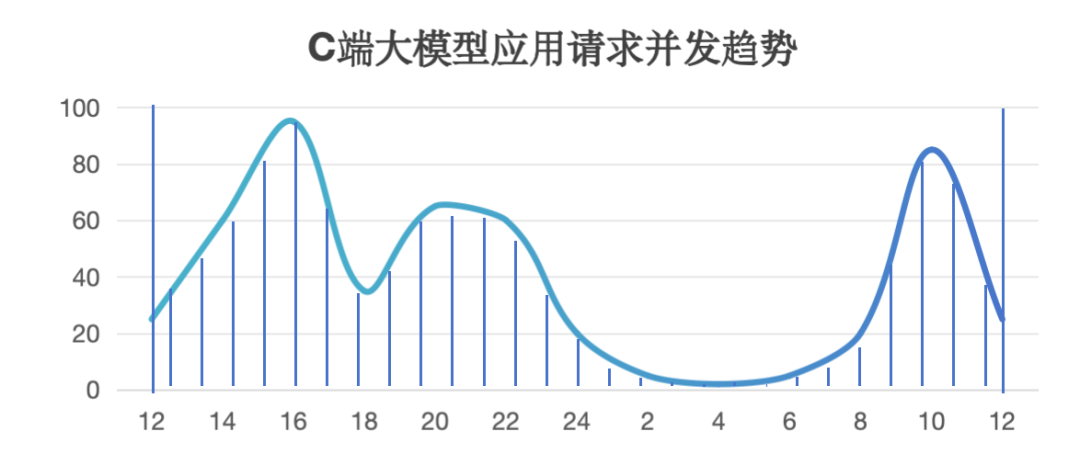
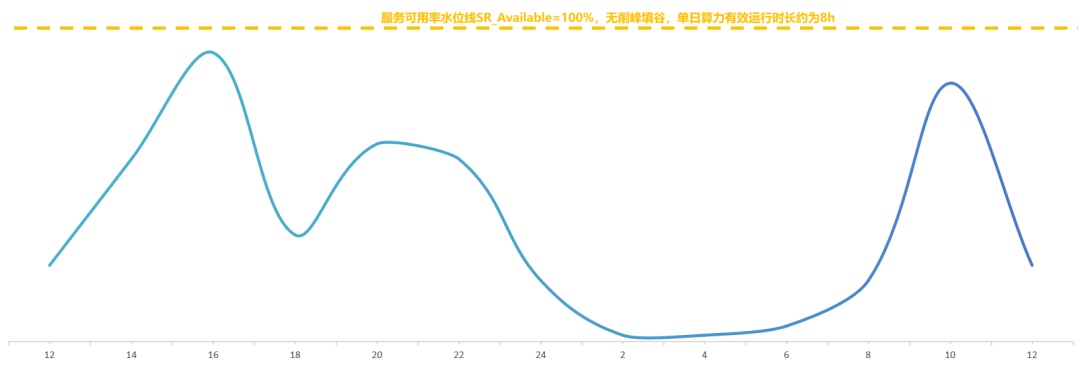
通常AI计算是一个分布式集群,所以需要采样集群中所有节点的实时容量水位情况,max_con就是系统的并发峰值,也就是服务峰值容量(不考虑少量的容量冗余)。有了这个容量图,就可以计算服务集群利用率。我们以讯飞星辰MaaS平台上工作日24小时区间内常见的C端大模型应用请求并发趋势为例(纵轴为并发容量%比例),通过计算采样阴影部分的面积求和后与整体面积的比例估算后,得到服务集群利用率SR_Use ≈ 33%,即整个集群如果按照并发峰值水位一直计算,有效计算时间SR_Use_Time = 8小时。
我们将这个趋势图与原文中的服务器占用图进行对比,在波谷阶段基本是一致的。根据原文信息可以测算出服务器平均占用率SR_Cost≈82%,这个值并不是我们提到的集群利用率,结合集群利用率估算后,可能会使得单机吞吐峰值大幅上涨。我们希望结合高峰期系统拒绝请求及恢复的时间点,估算出服务可用率的水位线SR_Available的值。
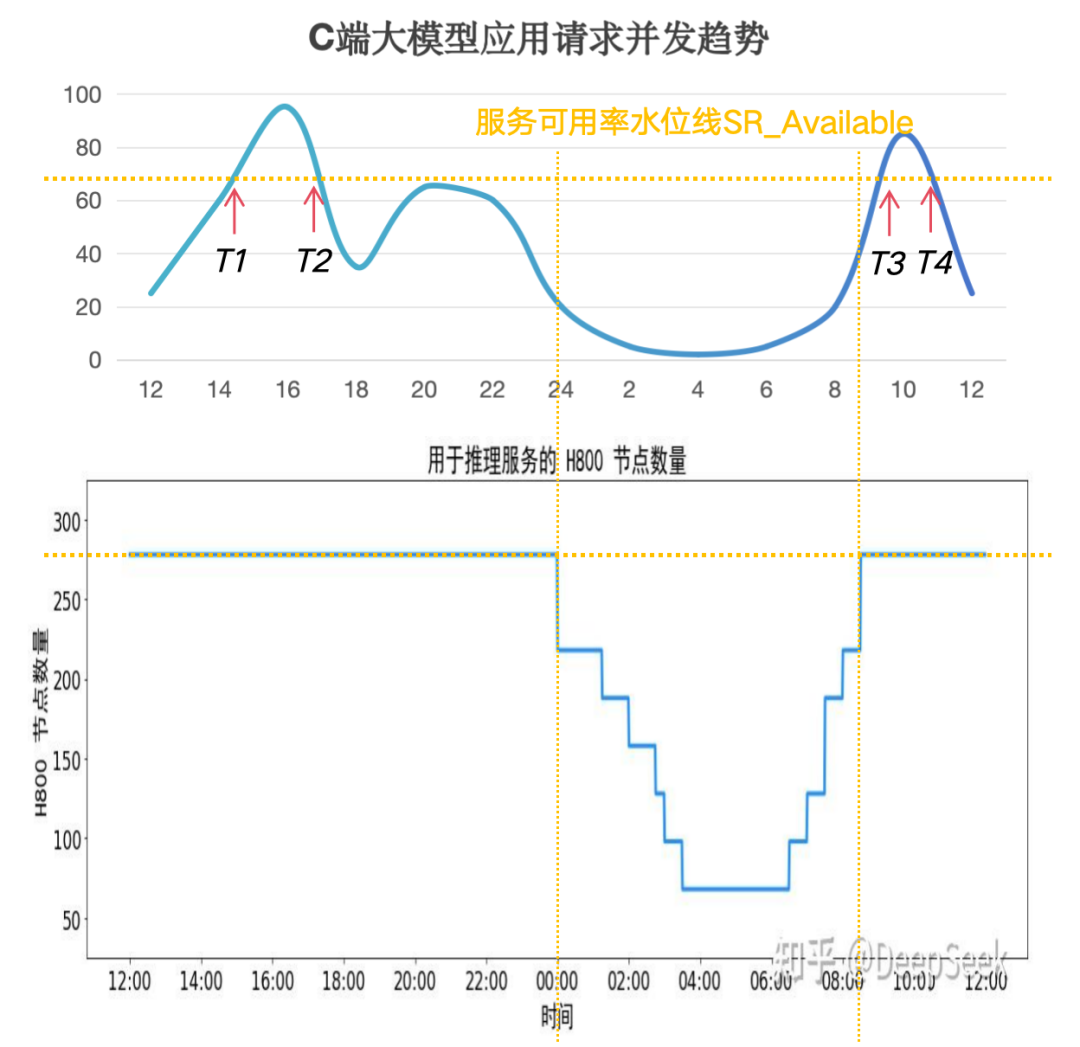
备注:图片来自知乎 我们分别对DeepSeek API和网页进行了V3/R1采样测试,时间在工作日3月13日~14日,得到如下数据:
对V3 API/网页进行全天24h采样测试,全天测试成功率100%,表明V3请求峰值未超过集群容量
对R1 API/网页进行全天24h采样测试,全天测试存在3个时间段成功率下滑、且对应时间段的请求TTFT显著增长,分别为13:36~17:22,21:02~23:02,09:26~11:34,表明在该时间段内请求峰值超过集群容量
由此可见,V3/R1存在集群隔离情况,且V3容量正常,推测V3使用量相比而言不高
在测试过程中,顺便统计了低峰期首token的响应时间均值TTFT≈9秒
以上测试时间是在原文发出之后,选择的工作日时间测试,流量特征相对吻合
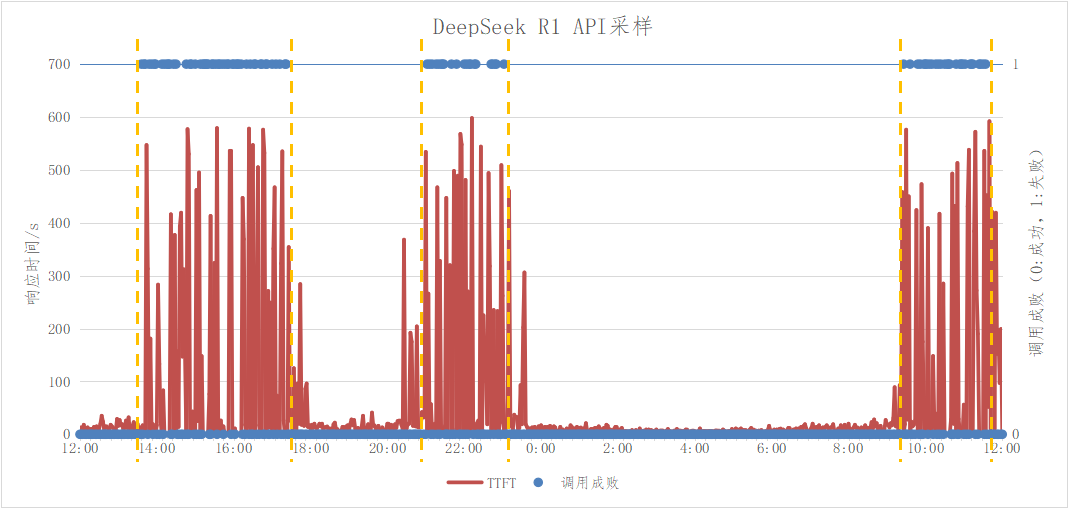
将R1成功率下滑时间段与C端并发趋势图进行对比,可以看到除了晚上的峰值时间不完全一样,其他两个峰值基本吻合,由此可以大概估算出R1集群服务可用率水位线SR_Available≈60%。
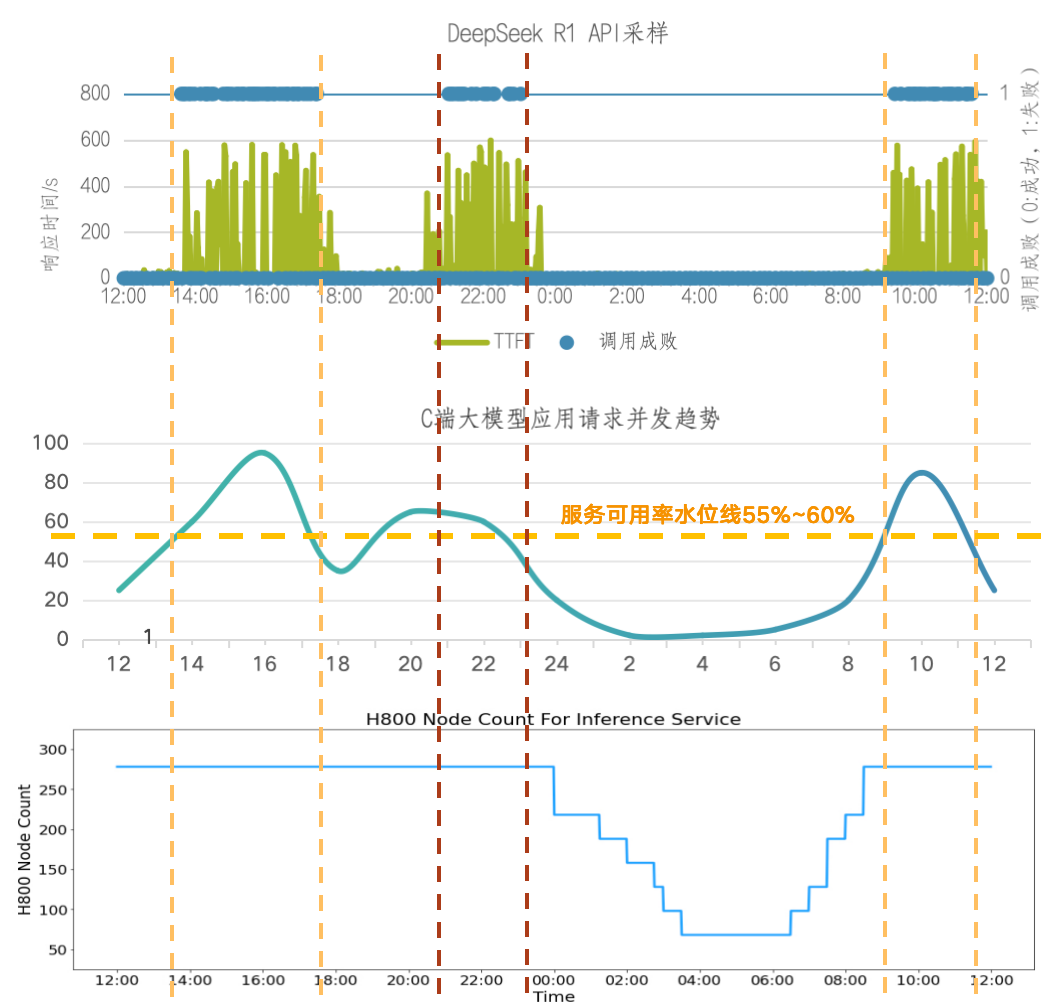
从夜间H800节点图可以看出最小集群时预留了60~70个节点,约2~3个部署单元。假设该集群中存在大量API24小时跑特定数据处理任务,那API对高利用率的贡献应该局限在这70个节点内。小结一下,DeepSeek公开的利用率相关的几个数据整体合理,从集群整体层面提高利用率的可能性方法如下:
削峰,牺牲一定的SLA成功率,节省了峰值时需要额外增加但低谷时利用率偏低的服务器,预计削峰的可用率水位在60%以上。MaaS产商可以根据SLA做分级API产品
填谷,将实时任务与离线任务形成一体化集群,使用潮汐调度技术实现集群的利用率提升,降低实时任务服务器低谷期的占用摊销18%,需要足够的离线业务体量。MaaS产商可以发力离线产品的业务体量
服务器集群部署单元PD配比估算验证
原文中提到每个Prefill部署单元4个节点,Decode部署单元18个节点,总集群278个节点,我们需要计算出Prefill和Decode部署单元的配比,以便后续进一步分析吞吐数据。估算步骤如下:
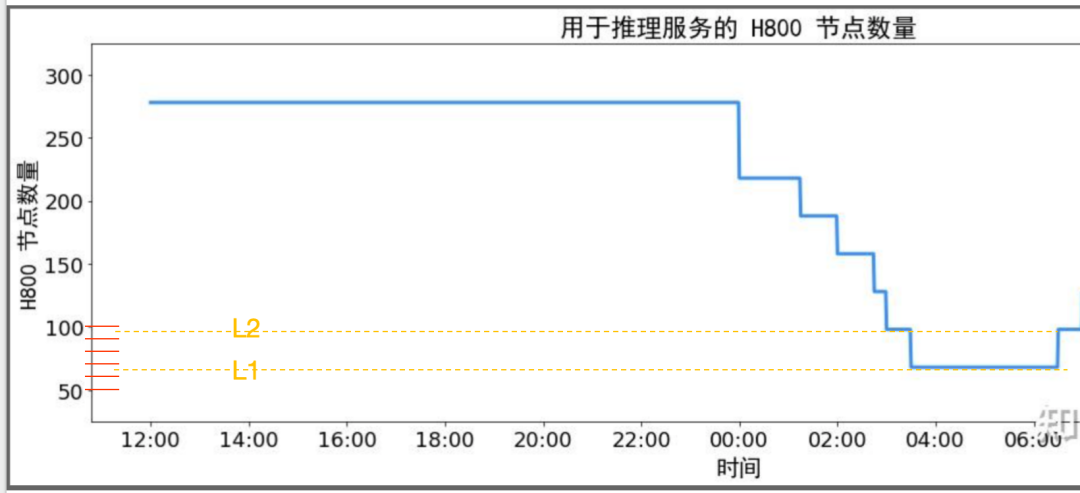
首先4*N+18*M=278,(N,M)=(65,1),=(56,3),=(47,5),=(38,7),=(29,9),=(20,11),=(11,13),=(2,15)
通过低谷期的节点数可以看出,L1水位约4*X1+18*Y1 在 60~70 (只能是偶数),L2扩容小于2个Decode单元36台,即4*X2+18*(Y1+1)在 90~100(只能是偶数)
我们估计N=29,M=9,N:M ≈ 3.2。在L1水位时,X1=7,Y1=2,X1:Y1 ≈ 3.5,节点数为64。在L2水位时,X2= 10,Y1+1=3, X2:(Y1+1)≈ 3.3,节点数为40+54=94。整体与低谷水位图吻合
Y1=2,意味着最低谷期时保留了一个V3部署单元,一个R1部署单元
备注:图片来自知乎文章《DeepSeek-V3 / R1 推理系统概览》 我们从原文中的吞吐的视角来计算一下这两个值,基本吻合:
输入608B*(1-56.3%)≈ 266B = 32.2k *24*3600*4*N,N≈23.9,考虑到机器占用率SR_Cost 82%,N≈23.9/82%≈29.15
输出168B=14.8k*24*3600*18*M,M≈7.3,M≈23.9/82%≈8.9
基于这样的配比,我们需要验证Prefill/Decode集群的处理能力是否一致。我们依旧以简化后的并发请求模式来计算相关值。在并发量一定的请求下,如果想保持Prefill/Decode两个阶段不积压,需要在平均单位时间内,两阶段完成的计算请求数一样,如果再简化一下,就是每秒处理请求数QPS一样。通过计算,两阶段的QPS十分接近,符合预期。
假设平均每个请求的输入长度为Avg_In = 608X tokens,非缓存计算的输入长度为Avg_In_P = 266X tokens,平均输出长度为Avg_Out = 168X tokens
Prefill阶段的QPS_P = 73.7k *(1 - 56.3%)*4*29 tps /Avg_In_P ≈ 14045/X
Decode阶段的QPS_D = 14.8k*18*9 tps/Avg_Out ≈ 14271/X
小结一下,考虑到V3和R1的输入/输出平均长度不一样,PD的配比也会不一样,但总的来说,公布的数据峰谷图、吞吐、集群配比上能高度吻合,公开数据合理。其中Prefill部署单元29个共116个节点,Decode部署单元9个共162个节点。
单机吞吐峰值与理论值估算验证
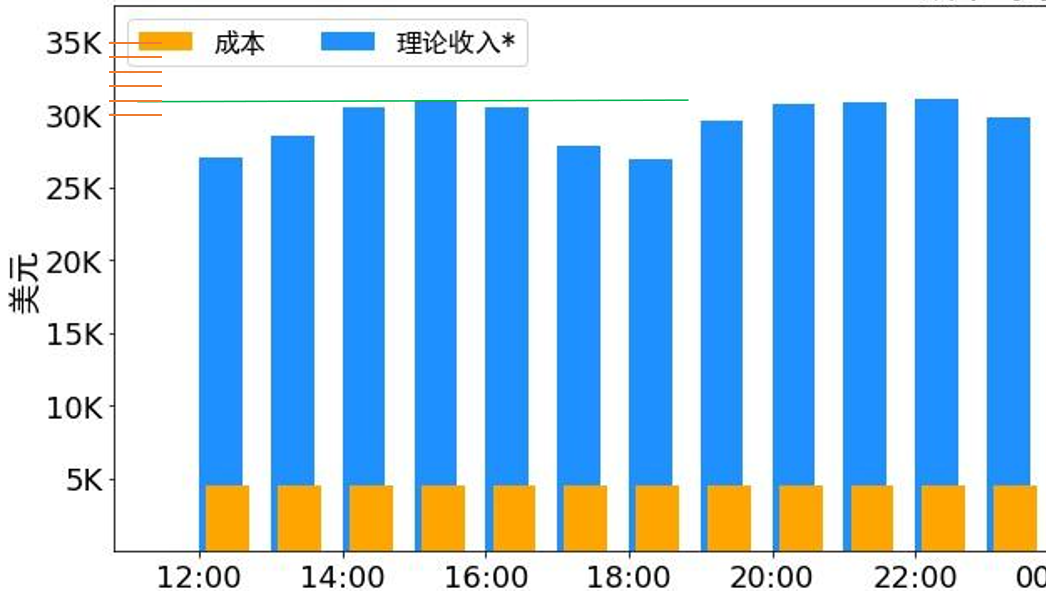
前面估算集群利用率,是为了将单机吞吐的平均值按照利用率换算为单机吞吐的峰值,这样能更好的对比与理论值的差异,为工程优化提供参考。考虑到原文中集群存在削峰的情况,我们直接选取峰值阶段1小时的吞吐数据来估算单机吞吐峰值。我们以峰值区间15:00~16:00为例:
该时间段服务器节点278,其中Prefill节点116个,Decode节点 162个,从下图可以估算出该小时内理论收入为$31k
DeepSeek R1 的定价:$0.14 / 百万输入 tokens (缓存命中),$0.55 / 百万输入 tokens (缓存未命中),$2.19 / 百万输出 tokens 输入 token 总数为 608B,其中 342B tokens(56.3%)命中 KVCache 硬盘缓存。输出 token 总数为 168B 平均每台 H800 的吞吐量为:对于 Prefill 任务,输入吞吐约 73.7k tokens/s(含缓存命中);对于 Decode 任务,输出吞吐约 14.8k tokens/s
假设该峰值区间的总输出token为X 百万,按输入/输出平均比例估计,则实际计算的总输入token数为1.583X,命中Cache 的总输入token数为2.036X, 结合该时段理论收入$31k与各部分单价,可得X=9.265B,累计总输入token为33.531B(其中14.67B 未命中Cache)
该区间时间为3600秒,与Prefill的总节点数116计算,得到单节点平均输入吞吐约为35.13k tokens/s(未含缓存命中),与Decode的总节点数162计算,得到单节点平均输出吞吐约为15.89k token/s,与公布的数据增长了8%,整体在合理的增长范围
考虑R1/V3集群为隔离部署,且V3请求峰值未超过集群容量,故高峰期间实际单机吞吐峰值还会略高于上述吞吐值
社区关于原文中公开的单机吞吐的理论值的分析,已经做的比较深入和全面了,其中zarbot与Han Shen的分析比较有代表性,此处引用了Han Shen其中一篇分析 https://zhuanlan.zhihu.com/p/29540042383。
H800 (BF16 kvcache)最佳离线吞吐为单卡2844 tokens/s,由two-mircobatch overlapping的 DP288-EP288 - bmla64 方案得到
H800 (FP8 kvcache)最佳离线吞吐为单卡3121 tokens/s,由two-mircobatch overlapping的 DP288-EP288- bmla128 方案,或者DP48-EP48- bmla128 方案得到
H800 (FP8 kvcache)最佳线上吞吐(满足20 tokens/s 左右用户延迟)为2909 tokens/s, 由single-batch compute-communication overlapping的DP24-EP24- bmla128 方案得到。
H800 (BF16 kvcache)最佳线上吞吐(满足20 tokens/s 左右用户延迟)为2844 tokens/s,由two-mircobatch overlapping的DP288-EP288- bmla64 方案得到
在8卡H800上,单机吞吐的理论值在22.75k tokens/s以上。本节中计算值15.89k token/s在理论值的70%,故数据在合理区间。小结一下,在服务容量高峰时段,经过估算,单节点平均输入吞吐约为35.13k token/s,单节点平均输出吞吐约为15.89k token/s,较官方公布平均吞吐约增长8%,公开数据合理,大家关注的输出吞吐部分,在理论值22.75k tokens/s范围内。
用户请求行为粗略估算
本节我们将用一些相对粗略的公开数据,大致估算一下用户的平均输入/输出。由于缺乏的数据输入项过多,预估与实际值会存在很大的误差,请侧重参考输入/输出等用户行为因素如何影响集群的配比。用户规模,在原文发出来的一周,我们咨询了相关C端运营,通过拟合各类数据,预估对应时间段在2400W左右。通过DeepSeek网页端提问,大概也得到了2000~3000W日活的范围,所以我们以DAU=24M为准。假设该用户数也包含了API侧toB toC的日活用户,整体而言DeepSeek自有流量的日活占绝大头。
平均输出,相比输入的长度受用户使用次数和连续会话轮次影响,模型的输出平均值一般比较稳定。我们参考星辰MaaS上 V3和R1的输出均值,分别为300和1000 tokens。分布比例,结合上文中提到V3在容量上比R1空闲大,我们认为用户使用V3的总次数低于R1,假设V3占比为r:
V3的每日总使用次数为168B*r/300=560M*r
R1的每日总使用次数为168B*(1-r)/1000=168M*(1-r)
平均次数,V3的平均用户使用次数为560M*r/24M=23.33*r,R1为168M*(1-r)/24M=7*(1-r)。平均轮次,轮次越大,平均输入因叠加历史输出会越长,假设V3的平均轮次为n,R1的平均轮次为m,平均轮次一定是小于等于平均次数,即n ≤ 23.33*r;m ≤ 7*(1-r)。平均输入,平均输入通常与用户平均使用上下文轮次有关,除此之外,由几个部分组成。
用户的直接输入,一般20 tokens左右,在平均输出中的成分为20*(n+1)/2=10n+10
上轮输出,R1的思维链约占输出的50%,不会作为下一轮的输入,V3不存在该截断,故V3为300*(n-1)/2=150n-150,R1为1000*50%*(m-1)/2=250m-250
联网搜索,联网搜索按照星辰MaaS统计,通常请求触发联网比例在15~25%之间,此处取20%。每次搜索网页全文按照5K tokens保守估计,均摊到每次的平均输入取整为1000 tokens,这部分tokens不会作为上下文历史累加

在粗估数据下,V3 token占比在35%时,用户行为相对符合直觉,V3的平均输入在2000 tokens左右,R1的平均输入在1800左右,日均总请求次数total_usage=560M*r+168M*(1-r)=3.05亿次。
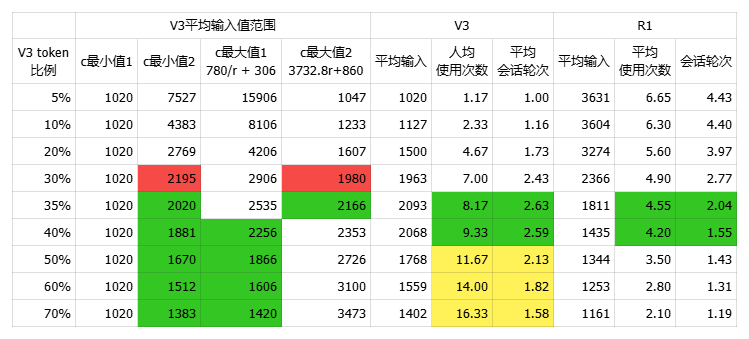
结合上一节中高峰期时段的数据,来粗略估算计算节点的分布情况,可得知下表V3的PD配比为20:3,共135个节点,R1的为9:6,共143个节点。整体来说Decode阶段的计算单元R1比V3多符合预期,Prefill阶段V3占用过多计算单元略显意外,按照利用率估算过程中的值来看,V3的峰值是未触发容量上限的,这可能与我们的平均输出预估以及DAU的误差有关,但也可能是为了在高峰期将预期使用R1的用户请求引导到性价比更高的V3。
可得X=9.265B,累计总输入token为33.531B(其中14.67B 未命中Cache)
该区间时间为3600秒,与Prefill的总节点数116计算,得到单节点平均输入吞吐约为35.13k tokens/s(未含缓存命中),与Decode的总节点数162计算,得到单节点平均输出吞吐约为15.89k token/s

小结一下,经过粗略的估算,当V3的输出流量占比在35%时,V3平均输入为2000 tokens,输出300tokens,R1平均输入为1800 tokens,输出为1000 tokens,V3计算单元的PD配比为20:3,R1为9:6。
集群高并发高吞吐策略分析
大专家EP并行计算的特点是需要高并发的请求量,来激活集群各个维度的性能上限,获得高吞吐率。首先分析原文中集群的并发情况。Decode阶段并发:
结合H800的单机token吞吐、平均输出速率可以知悉Decode节点单机并发≈14.8k/21* ≈ 705
按官方公开信息1个Decode部署单元为18个节点,故Decode最小部署单元并发≈705*18 = 12.69k
根据上文分析Decode节点总数为162,则集群整体并发数max_con≈705*162=114.21k
Prefill阶段并发:
根据上节中的粗略估算的数据,R1平均输入长度为1800 tokens,R1的TTFT=9s
R1单机并发=73.7k/1.8k * 9=368.5
R1Prefill最小部署单元并发=368.5*4 =1474
通常在推理计算过程中,在高并发、高并行计算获得高吞吐的同时,也需要权衡延迟因素TTFT、TPOT,其关系如下:
并发提升初期,单机吞吐值、TTFT随着并行度提升呈现非线性增长趋势;
当并发超过一定阈值后,并行度提升带来的计算量达到服务器计算瓶颈,吞吐不再随之提升,但TTFT因并行排队、通信延迟等因素而持续增加;
上述趋势可以从zarbot的分析中得到论证:单机Prefill吞吐在DP8并行策略下达到33741,在DP4并行策略下仅为28693,提高并行度一定程度可以提升单机吞吐。MaaS厂商如果期望得到更低的TTFT,可能需要以更低的单机吞吐为代价,来获得用户体验的平衡。
文章链接 在TP=4,DP=8的部署方式下,H800单机Prefill TPS=33741.0;TPS(overlap)=52240.1 在TP=8,DP=4的部署方式下,H800单机Prefill TPS=28693.1;TPS(overlap)=41057.0
小结一下,原文中最小部署单元可支撑12.69k路并发,整个集群支撑114.21k路并发,要达到超低成本,需要有规模化的用户请求才能支撑,MaaS厂商需要权衡好冷启动阶段的成本问题。若要达成更小的TTFT达到更优的用户体验,MaaS厂商需要考虑吞吐和首响平衡带来的Prefill阶段额外成本开销。
低成本组合方案估算
最后,我们结合上述性能分析的各类影响因素,梳理了几种典型场景下的成本方案,供参考。方案1,假设MaaS产商在白日不削峰、夜间无填谷的情况下,集群单日成本利润率约为112%。

方案2,通过训推一体、弹性调度等技术实现夜间波谷期资源回收填谷后,可有效降低服务成本,集群单日成本利润率约为183.37%。
以夜间缩容区间00:00~08:00为例,55%水位线以下填谷收益约为(278-226.75)/278= 18.4%;55%水位线以上填谷收益为1/3;全天降本收益55%*18.4%+45%*1/3=25%

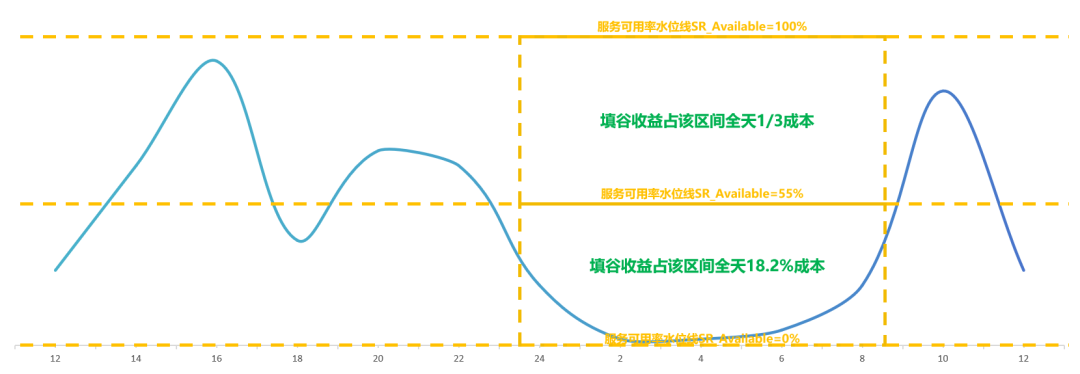
方案3,在方案2的基础上再进一步,可以在日间波峰期间将训练资源弹性扩容以应对流量峰值,进一步降低服务成本,单日成本利润率约为234.16%。

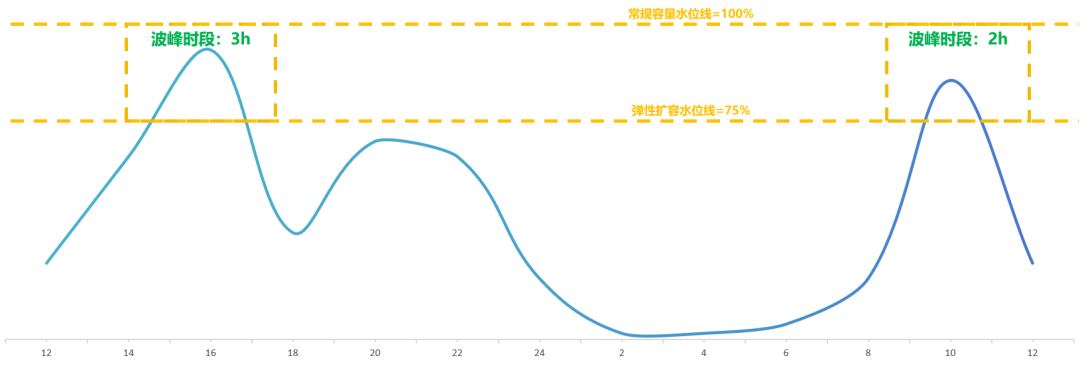
五、MoE大模型成本优化方向总结
综合上述分析,我们可以看到除了极致的推理性能及吞吐优化外,大模型成本与算力资源有效利用率、首响用户体验等体系化的综合策略也息息相关。基于以上成本数据分析,MaaS产商的成本优化方向主要集中在以下几点:
大专家EP并行方案优化,优化指标在H800上需要达到,Prefill单机达35.13k tokens/s(未含缓存命中),Decode单机吞吐达15.89k token/s,其他卡型可以参考性价比换算
集群潮汐调度,基于夜间波谷期算力潮汐调度,对MaaS业务低峰期资源回收填谷,有效降低推理算力成本25%。基于日间波峰期算力的弹性调度扩容,将75%水位线以上容量的增量资源成本由全天24h降低至5h,在夜间基础上再降本11.4%
离线计算产品设计,通过离线产品补充峰谷期的计算空闲,提升集群利用率
差异化SLA产品,面向不同SLO及用户体验需求提供差异化MaaS服务,通过适当增加首token响应TTFT、降低平均每token输出的时延TPOT、适当放弃峰值期间成功率,确保集群高利用率
规模化推广,MoE超低成本依赖规模化用户请求支持,冷启动成本较高,选择合适的部署方案应对用户需求
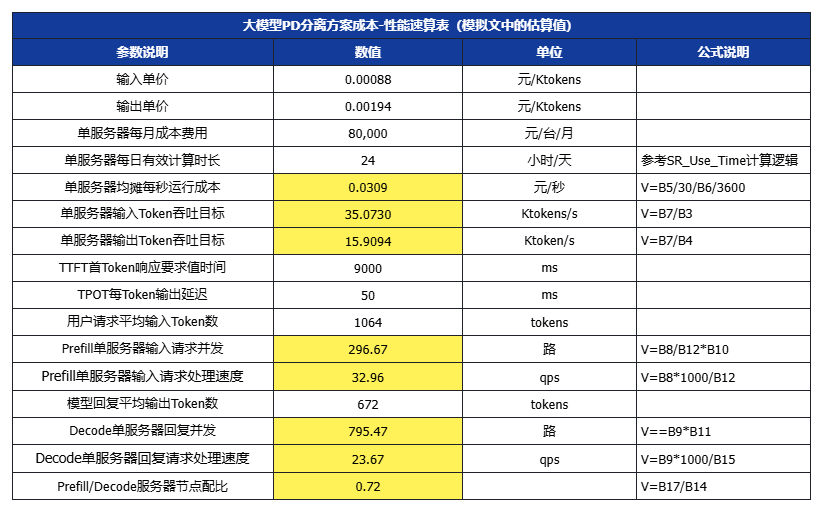
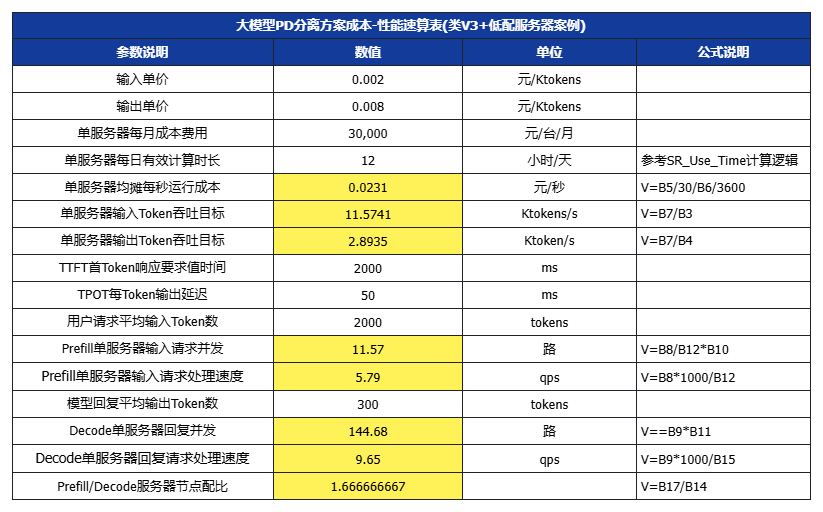
六、大模型成本-性能对照速算表
为了方便技术团队设置技术优化目标及运营团队设计产品价格,我们进一步提供了一个速算表,可以根据目标价格,结合不同的SLA/SLO、用户场景输入/输出长度,以及服务器选型成本、集群利用率运营水平,来设置优化目标。(白色数值项可代入,黄色为公式计算)
假设平均每个请求的输入长度为Avg_In = 608X tokens,非缓存计算的输入长度为Avg_In_P = 266X tokens,平均输出长度为Avg_Out = 168X tokens
设X=3
七、结语及展望
DeepSeek-V3/R1自开源后迅速轰动全球,以其领先的算法架构创新以及极致的系统性工程优化,赢得了全球从业者及用户的尊重,这也让无数研究员、工程师热血澎湃!我们也看到在NVIDIA GTC 2025上,黄教主发布了性能超强的新一代Blackwell芯片。在条件受限以及硬件存在差距的情况下,我们唯有继续从系统性角度进行极致的工程创新,方能补齐硬件上的短板,以极致的性价比迎接AI大模型应用的指数级增长!
-
开源
+关注
关注
3文章
3754浏览量
43968 -
科大讯飞
+关注
关注
19文章
842浏览量
62555 -
大模型
+关注
关注
2文章
3191浏览量
4146 -
DeepSeek
+关注
关注
2文章
804浏览量
1823
原文标题:万字长文深度解析DeepSeek-V3 / R1 推理系统成本
文章出处:【微信号:讯飞开放平台,微信公众号:讯飞开放平台】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
了解DeepSeek-V3 和 DeepSeek-R1两个大模型的不同定位和应用选择
【「DeepSeek 核心技术揭秘」阅读体验】书籍介绍+第一章读后心得
AMD将DeepSeek-V3模型集成至Instinct MI300X GPU
云天励飞上线DeepSeek R1系列模型

昆仑芯率先完成Deepseek训练推理全版本适配

扣子平台支持DeepSeek R1与V3模型
讯飞开放平台支持DeepSeek
Deepseek R1大模型离线部署教程






 工商网监
工商网监
评论