 AI演进的核心哲学:使用通用方法,然后Scale Up!
AI演进的核心哲学:使用通用方法,然后Scale Up!

作者:算力魔方创始人/英特尔创新大使刘力
一,AI演进的核心哲学:通用方法 + 计算能力
Richard S. Sutton在《The Bitter Lesson》一文中提到,“回顾AI研究历史,得到一个AI发展的重要历史教训:利用计算能力的通用方法最终是最有效的,而且优势明显”。核心原因是摩尔定律,即单位计算成本持续指数级下降。大多数 AI 研究假设可用计算资源是固定的,所以依赖人类知识来提高性能,但长期来看,计算能力的大幅提升才是推进AI演进的关键。
《The Bitter Lesson》原文链接:
http://www.incompleteideas.net/IncIdeas/BitterLesson.html
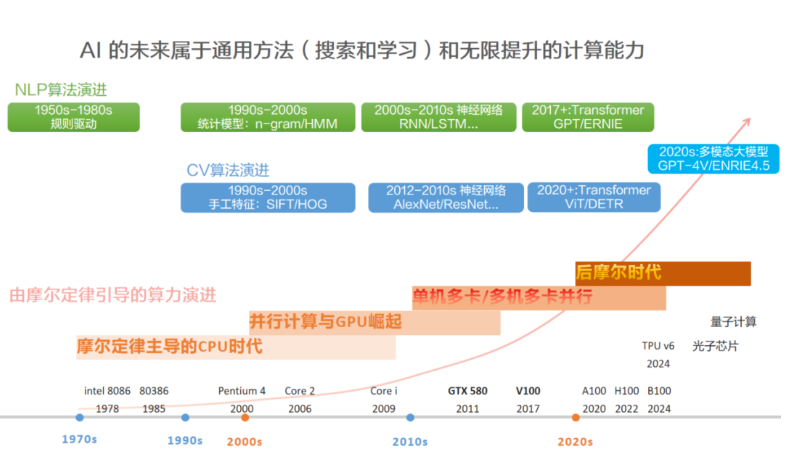
把不同时期的AI代表算法和典型计算硬件放到一起,可以看出,依赖人类知识的算法(比如手工设计规则)在某段时期内效果暂时领先,但随着计算能力的发展,会被 “更通用的方法 + 更强的计算” 碾压。计算机视觉和自然语言处理的算法演进,都符合这个规律。
计算机视觉:在CPU时代,手工特征(SIFT/HOG) + SVM的方法暂时领先。到了GPU时代,基于更通用的方法(CNN) + 更强的计算(GTX-580)的AlexNet在2012年,以15.3%的Top-5 错误率碾压了所有基于人类手工提取特征的方法。在多卡并行时代,Transformer摈弃了CNN注入的人类知识(认为相邻像素关联性强),使用自身的自注意力能力自行捕捉全局依赖,使得通用目标识别水平更上一层楼,碾压CNN。
自然语言处理:在CPU时代,最初使用n-gram方法学习单词分布,以此通过前一个字符来预测后一个字符(单词分布决定字符关联就是人类知识)。n-gram的记忆能力有限,能生成一定长度的语句,但在几十个词规模的生成能力就不行了。到了GPU时代,更通用的方法RNN,可以逐个阅读单词的同时更新思维状态,具备了短期记忆能力;LSTM在RNN基础上增加了长期记忆能力,能在百词内较好的生成内容,但在几百词的生成规模上,就会逐渐偏离主题。在多卡并行时代,Transformer摈弃了RNN注入的人类知识(时序依赖关系是关键,当前状态依赖历史状态),使用自身的自注意力能力自行捕捉长程依赖,其生成能力在多个领域能超过人类水平,碾压RNN。
AI 的未来属于通用方法(搜索和学习)+ 无限提升的计算能力,而不是人类对具体问题的 “聪明解法”。越通用的人工智能,方法应该越简单,建模时应该越少人类知识的假设才对。我们应该让 AI 自己通过计算和数据去发现规律,而不是教它 “我们认为正确”的东西。
二,Transformer: 更加通用的神经网络架构
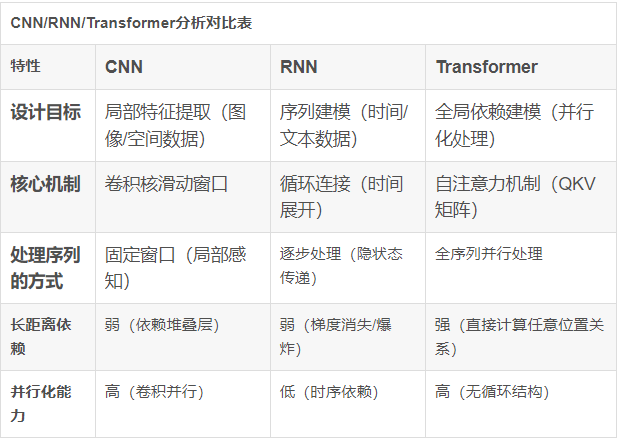
《Attention is All You Need》在2017年首次提出了一种全新的神经网络架构Transformer架构,它完全基于注意力机制,从全局角度“观察和学习”数据的重要特征,相比循环神经网络(RNN)和卷积神经网络(CNN),注入的人类先验知识更少,方法更通用:
CNN注入了相邻像素关联性强的人类知识,导致CNN无法处理不具备该假设的信息,例如:自然语言。
RNN假设了“时序依赖关系”是关键,当前状态依赖历史状态(通过隐藏状态传递信息),导致RNN无法处理不具备该假设的信息,例如:图像。
Transformer使用自身的自注意力能力自行捕捉数据中的关系,即通过自注意力能力从全局角度“观察和学习”数据的重要特征。只要信息能从全局角度被观察和学习,那么该信息就能被Transformer处理。文本、图像、声音等信息,都满足该要求,所以,都能统一到Transformer架构上进行处理。各种模态信息在进入Transformer前,只需要把信息Token化,即切成一个个小块就行。
《Attention is All You Need》原文链接:
https://arxiv.org/pdf/1706.03762
CNN/RNN/Transformer分析对比表
在多机多卡算力时代,Transformer是比CNN和RNN更加通用的神经网络架构。
三,Decode-Only: 更加通用的大语言模型架构
《Attention is All You Need》提出了Transformer架构后,大语言模型的技术探索出现三个方向:仅使用左边红色框部分的Encoder-Only,仅使用右边绿色框的Decoder-Only和全部都使用的Encoder-Decoder。???????
《Attention is All You Need》原文链接:
https://arxiv.org/pdf/1706.03762
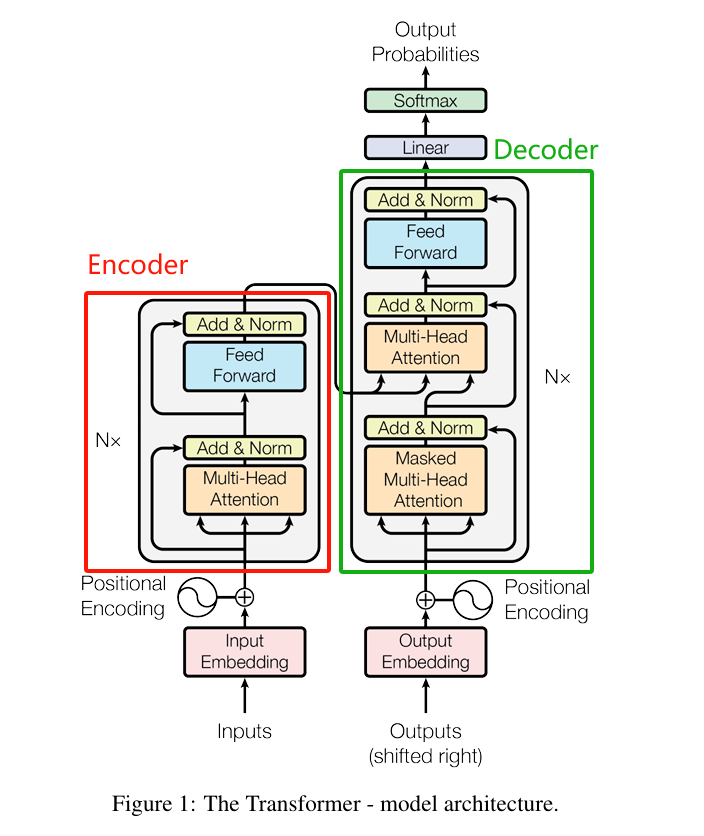
Encoder-Only:仅使用左边红色框中的编码器部分构建大语言模型,这个方向一开始主要有Google、Baidu等参与,代表模型有BERT、ERNIE等。Encoder-Only模型是掩码语言模型(Masked Language Model),使用双向注意力机制,即训练模型时,提供预测字符的双向上下文,这有点儿类似完形填空,从一句话中随机挖掉一个字(例如:白_依山尽),然后预测被挖掉字。由于模型能获得预测字符之前(过去)和之后(未来)的上下文,所以能高效学习上下文语义,体现出强大的文本语义理解能力,常用于情感分析、阅读理解和文本分类等任务。但也正是由于模型在预测时同时受过去和未来双向的上下文限制,导致在生成文本时表现质量不高和多样性低,不太符合用户的预期。随着 AI 应用向文本创作、对话系统、代码生成等方向扩展,Encoder-only 架构难以满足AIGC应用的生成需求,所以,在2021年后,这个方向就停止演进了。
Decoder-Only: 仅使用右边绿色框中的解码器部分构建大语言模型,这个方向主要由OpenAI主导,代表模型是GPT系列模型。Decoder-Only模型是自回归语言模型(Autoregressive Language Modeling),使用因果注意力机制,即训练模型时,不能看见右侧(未来)的上下文,只能使用左侧(过去)的上下文预测下一个字符(Token),这有点儿类似故事续写,给出前面的字(例如:白_),然后预测下一个字。由于模型只能获得预测字符之前(过去)的上下文,训练起来更难,需要更大的数据集和更强的算力。2020年发布的GPT-3证明了 Decoder-Only 架构在大规模数据上能够更好地学习语言的统计规律和模式,不仅在生成文本时表现出更高的质量和多样性,还显著增强了语言理解的能力,使得模型能够更好地理解用户的意图和需求,并据此生成更加符合用户期望的文本。由此,在2021年后,Google、Baidu、Meta等厂家都转向了Decoder-Only架构。
Encoder-Decoder:同时使用编码器和解码器部分构建大语言模型,这个方向主要由Google、ZhipuAI在探索,代表模型有T5、GLM等。该构架虽然能兼顾Encoder-Only和Decoder-Only架构的优势,但相对Decoder-Only架构,训练成本高2~5倍、推理成本高2~3倍,所以,仅用于一些需要严格双向理解的细分领域(如多模态生成任务),其发展被 Decoder-only 大大超越。
JINGFENG YANG等在《Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond》,
https://arxiv.org/pdf/2304.13712
展现出了大语言模型架构的演进全景图。上述演进趋势可以从下图中看出:
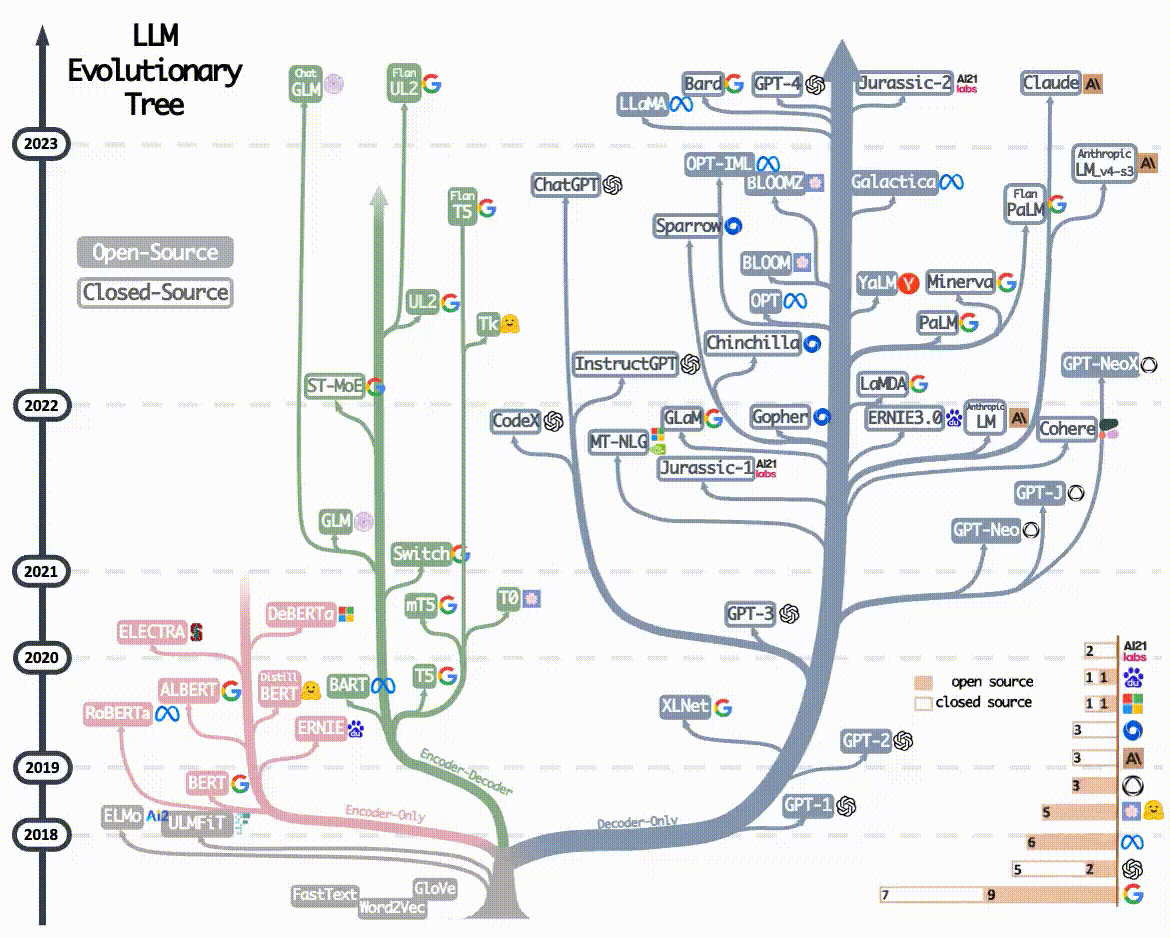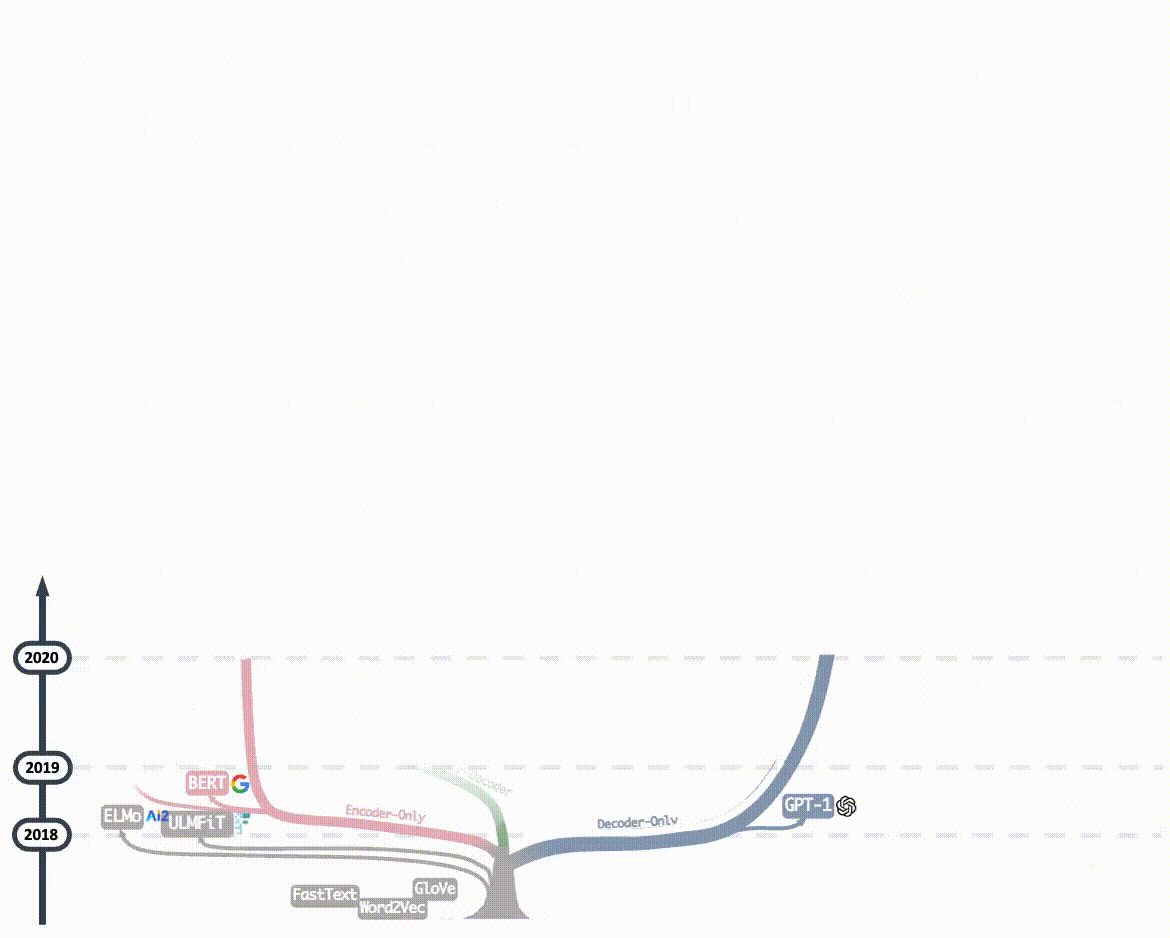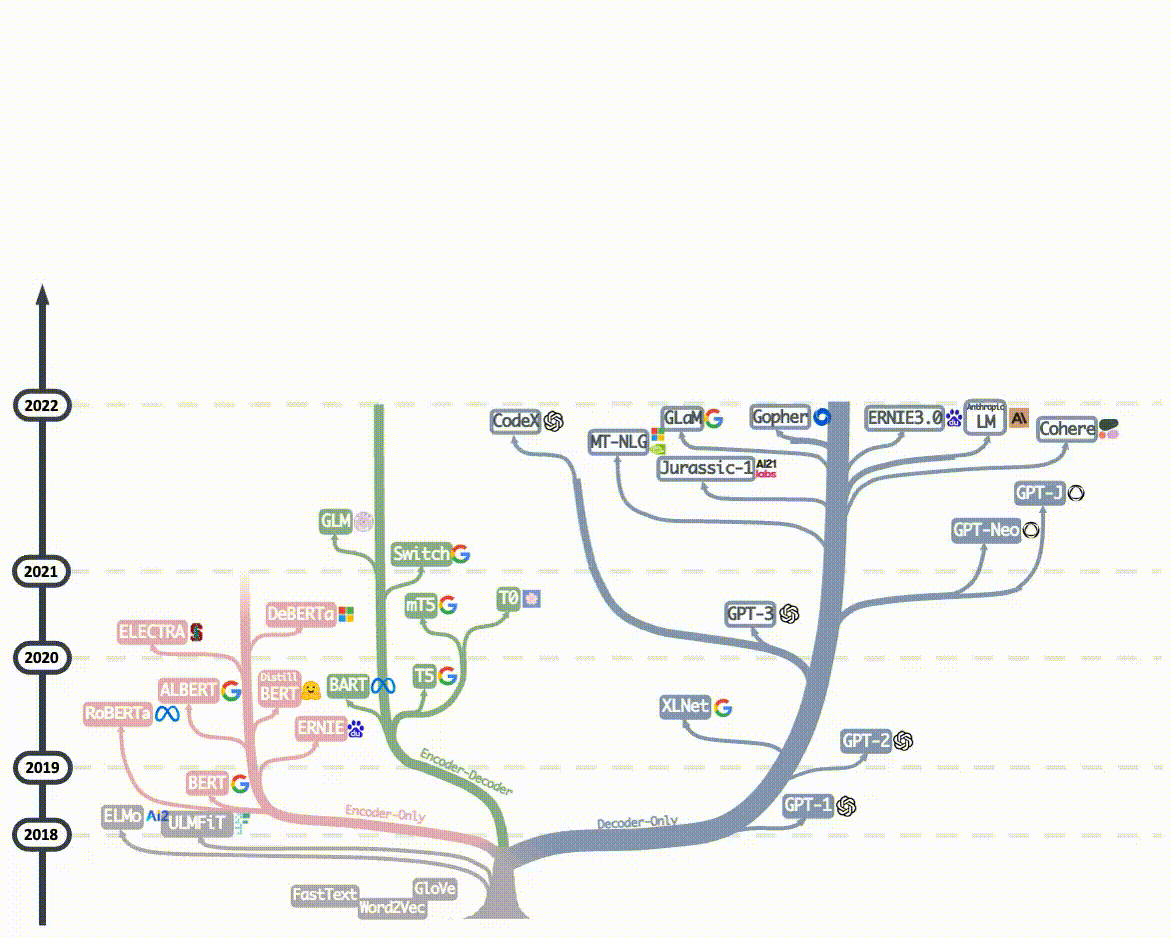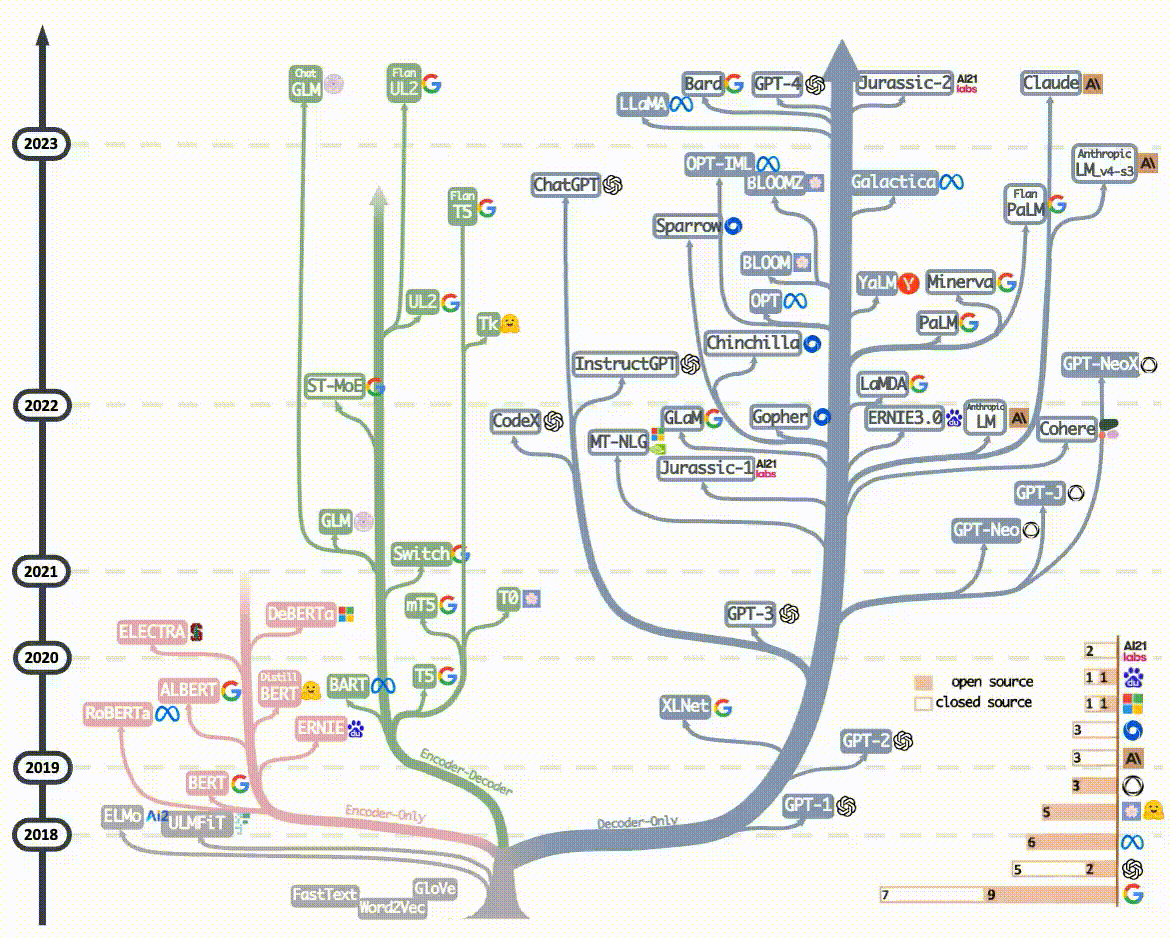
2023年后的主流大语言模型(如GPT-4、ERNIE4.0、Llama3...)均采用Decoder-Only架构,核心原因正是 Decoder-Only架构比其它两个架构更简单、更通用,在计算能力飞速发展的大趋势下, Decoder-Only架构拥有更大的Scale up的潜力 -- 即保持核心架构不变的情况下,通过增加训练数据,扩大模型参数规模和提升计算能力,可以进一步提升模型能力。
四???????,总结
大语言模型的演进过程,再次证明了Richard S. Sutton在《The Bitter Lesson》
http://www.incompleteideas.net/IncIdeas/BitterLesson.html
提到的AI能力演进的哲学思想:使用通用方法,然后借助计算能力Scale Up。
如果你有更好的文章,欢迎投稿!
稿件接收邮箱:nami.liu@pasuntech.com
更多精彩内容请关注“算力魔方?”!
审核编辑 黄宇
-
AI
+关注
关注
88文章
35476浏览量
281262 -
语言模型
+关注
关注
0文章
563浏览量
10836
发布评论请先 登录
一文详解基于以太网的GPU Scale-UP网络

Scale out成高性能计算更优解,通用互联技术大有可为

Unix哲学归纳
AI的核心是什么?
深度学习推理和计算-通用AI核心
AGI:走向通用人工智能的【生命学&哲学&科学】第一篇——生命、意识、五行、易经、量子 精选资料分享
TB-96AI是什么?TB-96AI核心板有哪些核心功能
CDMA2000核心网演进组网策略探讨

IBM推出专为AI打造的全新Storage Scale System 6000
人工智能初创企业Scale AI融资10亿美元
奇异摩尔分享计算芯片Scale Up片间互联新途径






 工商网监
工商网监
评论