 利用英特尔OpenVINO在本地运行Qwen2.5-VL系列模型
利用英特尔OpenVINO在本地运行Qwen2.5-VL系列模型

作者:
介绍
近期阿里通义实验室在 Hugging Face 和 ModelScope 上开源了 Qwen2.5-VL 的 Base 和 Instruct 模型,包含 3B、7B 和 72B 在内的 3 个模型尺寸。其中,Qwen2.5-VL-7B-Instruct 在多个任务中超越了 GPT-4o-mini,而 Qwen2.5-VL-3B 作为端侧 AI 的潜力股,甚至超越了之前版本 的Qwen2-VL 7B 模型。Qwen2.5-VL 增强了模型对时间和空间尺度的感知能力,在空间维度上,Qwen2.5-VL 不仅能够动态地将不同尺寸的图像转换为不同长度的 token,使用图像的实际尺寸来表示检测框和点等坐标,这也使得Qwen2.5-VL模型可以直接作为一个视觉 Agent,推理并动态地使用工具,具备了使用电脑和使用手机的能力。
本文将分享如何利用英特尔 OpenVINO 工具套件在本地加速Qwen2.5-VL系列模型的推理任务。
内容列表
环境准备
模型下载和转换
加载模型
准备模型输入
运行图像理解任务
1环境准备
该示例基于Jupyter Notebook编写,因此我们需要准备好相对应的Python环境。基础环境可以参考以下链接安装,并根据自己的操作系统进行选择具体步骤。
https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-getting-started
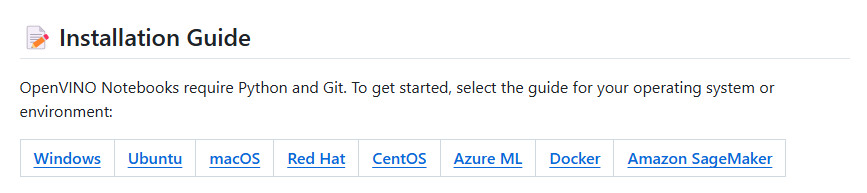
图:基础环境安装导航页面
此外本示例将依赖qwen-vl-utils以及optimum-intel组件,其中安装optimum-intel过程中将自动安装OpenVINOruntime, NNCF及Transformers等相关依赖库。
2模型下载和转换
这一步中,我们需要完成将Qwen2.5-VL .safetensor格式模型转化为OpenVINO IR格式,并对其进行INT4权重量化,实现对模型体积的压缩。为了达到这一目的,optimum-intel提供了命令行工具:optimum-cli,基于该工具,我们只需一行命令便可实现上述步骤:
optimum-cli export openvino --model Qwen/Qwen2.5-VL-3B-Instruct Qwen2.5-VL-3B-Instruct/INT4 --weight-format int4
其中“—model”参数后的“Qwen/Qwen2.5-VL-3B-Instruct”为模型在HuggingFace上的model id,这里我们也提前下载原始模型,并将model id替换为原始模型的本地路径,针对国内开发者,推荐使用ModelScope魔搭社区作为原始模型的下载渠道,具体加载方式可以参考ModelScope官方指南:https://www.modelscope.cn/docs/models/download
3加载模型
接下来需要完成对模型推理任务的初始化,并将模型载入到指定硬件的内存中,同样的,我们可以利用optimum-intel封装好的OpenVINO视觉多模态任务对象 OVModelForVisualCausalLM 对象完成该操作。
from optimum.intel.openvino import OVModelForVisualCausalLM model = OVModelForVisualCausalLM.from_pretrained(model_dir, device.value)
如示例代码所示,通过OVModelForVisualCausalLM的from_pretrained函数接口,可以很方便地根据用户提供的模型路径,将模型载入到指定的硬件平台,完成视觉多模态任务的初始化。
4准备模型输入
第四步需要根据Qwen2.5-VL模型要求的prompt template准备模型的输入数据。数据格式如下:
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": f"file://{example_image_path}",
},
{"type": "text", "text": question},
],
}
]
其中:
“role“字段用于指定对话角色,包括system, user以及assistant三种类型;
"content"字段表示对话角色输出的内容,其中”type”为内容类别,包含image,video,text三种类型,支持多张image输入。
接下来可以通过Qwen官方提供的方法将用户输入的text和image编码为模型的输入tensor。
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) image_inputs, video_inputs = process_vision_info(messages) inputs = processor( text=[text], images=image_inputs, videos=video_inputs, padding=True, return_tensors="pt", )
5运行图像理解任务
最后一步需要调用模型对象的generation函数,进行答案生成,这里可以通过添加TextStreamer迭代器的方式,在命令行中流式输出文本内容。
from transformers import TextStreamer generated_ids = model.generate(**inputs, max_new_tokens=100, streamer=TextStreamer(processor.tokenizer, skip_prompt=True, skip_special_tokens=True))
6总结
Qwen2.5-VL 系列模型的发布带来了更精准的视觉定位,文字理解以及Agent智能体能力。OpenVINO 则可以以更低的资源占用,高效地在本地运行Qwen2.5-VL视觉多模态模型,激发AIPC异构处理器的潜能。相信构建面向桌面操作系统的本地智能体应用已不再遥远。
-
英特尔
+关注
关注
61文章
10205浏览量
175024 -
模型
+关注
关注
1文章
3531浏览量
50565 -
OpenVINO
+关注
关注
0文章
115浏览量
512
原文标题:开发者实战|如何利用OpenVINO? 在本地运行Qwen2.5-VL系列模型
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Intel OpenVINO? Day0 实现阿里通义 Qwen3 快速部署
基于C#和OpenVINO?在英特尔独立显卡上部署PP-TinyPose模型
英特尔CPU部署Qwen 1.8B模型的过程
请问OpenVINO?工具套件英特尔?Distribution是否与Windows? 10物联网企业版兼容?
为什么Caffe模型可以直接与OpenVINO?工具套件推断引擎API一起使用,而无法转换为中间表示 (IR)?
为什么无法检测到OpenVINO?工具套件中的英特尔?集成图形处理单元?
使用英特尔? NPU 插件C++运行应用程序时出现错误:“std::Runtime_error at memory location”怎么解决?
介绍英特尔?分布式OpenVINO?工具包
安装OpenVINO工具套件英特尔Distribution时出现错误的原因?
英特尔推出了OpenVINO
已有超过500款AI模型在英特尔酷睿Ultra处理器上得以优化运行
使用PyTorch在英特尔独立显卡上训练模型





 工商网监
工商网监
评论