 边缘AI新突破:MemryX AI加速卡与RK3588打造高效多路物体检测方案
边缘AI新突破:MemryX AI加速卡与RK3588打造高效多路物体检测方案

信息革命的浪潮正快速推进!随着科技日新月异的发展,人工智能(AI) 的应用已悄然融入人们的日常生活,无论是 Google 的搜索引擎、Facebook 的推荐系统,还是电商平台的销售排行,AI 技术正潜移默化地改变着我们的生活方式。这些科技成果的普及,使得低成本、高效能的解决方案成为当下的关键需求。
同时,视觉相关的AI应用正以惊人的速度改变着我们的世界。无论是在汽车、工业还是医疗领域,其独特价值都得到了充分展现。展望未来,随着视觉AI技术的不断进步,更多创新应用将逐步落地,深刻影响并重塑我们的日常生活和工作方式。以下是视觉AI在各领域的典型应用:
◆ 智能监控:通过实时目标检测、行为分析和入侵预警,为智慧城市的安全管理提供有力支持。
◆ 智慧零售:借助顾客行为分析和智能货架管理,优化购物体验,同时提升销售效率和运营效益。
◆ 医疗影像分析:辅助医生进行精准诊断,例如肿瘤检测与分析,从而提高医疗效率和诊断准确性。
◆ 工业质检:利用视觉AI快速识别产品缺陷,确保生产质量的稳定性,并显著提升生产效率。
◆ 自动驾驶:车载AI通过视觉处理技术分析道路环境、行人及障碍物,实时做出决策,大幅提升驾驶的安全性与可靠性。
边缘计算(Edge Computing)将成为推动该技术发展的关键因素。随着神经处理单元(Neural Processing Unit, NPU)的问世,计算性能实现了指数级提升,使机器学习和人工智能应用得以广泛应用于移动设备、传感器等多种硬件中,从而让智能计算更加贴近人们的日常生活。为此,MemryX 推出了 MX3 AI 芯片,该芯片能够提供每瓦高达 5 TOPS 的算力性能,并支持浮点数(Brain Floating Point)运算,以确保用户模块的计算精度。每颗芯片内置 10.5 MB 的静态随机存取存储器(SRAM),用于模块访问,不会占用主系统资源。此外,最多可串联 16 颗芯片以进一步扩展性能。

图1 MemryX AI芯片规格示意图
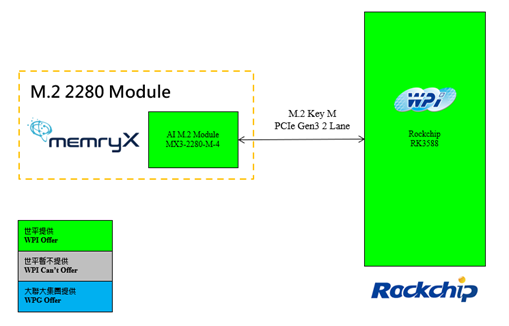
2024年,MemryX 重磅推出外挂式 MemryX MX3 AI 推理加速卡,采用 PCIe Gen3 M.2 M-Key 接口,具备高达 20 TOPS 的卓越计算性能,为各类工业电脑带来即插即用的便捷体验。该解决方案以“平台升级,迎接AI智能时代”为设计理念助力企业与开发者轻松迈向人工智能领域。本方案特别结合了 Orange Pi 5 Plus (Rockchip RK3588) 与 MemryX AI 加速卡,构建出一套高性价比的智能解决方案。凭借 MemryX 提供的丰富软件资源及对主流深度学习框架 (如 TensorFlow、PyTorch、ONNX) 的支持,即便是新手也能快速上手,轻松部署 AI 模型,实现智能应用开发。
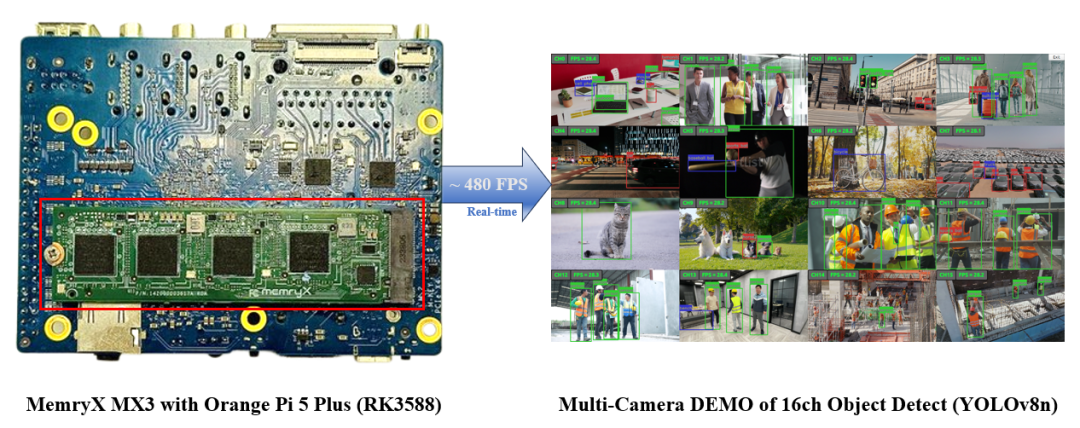
图2 基于 MemryX AI 加速卡结合 Rockchip RK3588 多路物体检测解决方案优势示意图
凭借 MemryX 的强大运算能力,能够轻松实现多路(Multi-Streamer) 的物体检测(Object Detection)应用。只需要使用普通的USB摄像头或通过网络来源串联,即可适用于市面上常见的停车场管理系统、智慧停车柱、智慧交通监控、商场人流检测、居家无死角意外检测等应用。现在就加入我们,体验人工智能的无限魅力!让 AI 助力您的创新,开创属于您的智能应用时代!
搭配 MemryX 所构建的开发环境 Developer Hub,开发者能够简单且快速地上手将 TensorFlow Lite、ONNX、Pytorch、Keras 等热门深度学习框架的模块转换为 MemryX MX3+ 芯片所需的 DFP 框架。并通过原厂丰富的示例应用与公共工具,即可一步步实现 AI 应用。
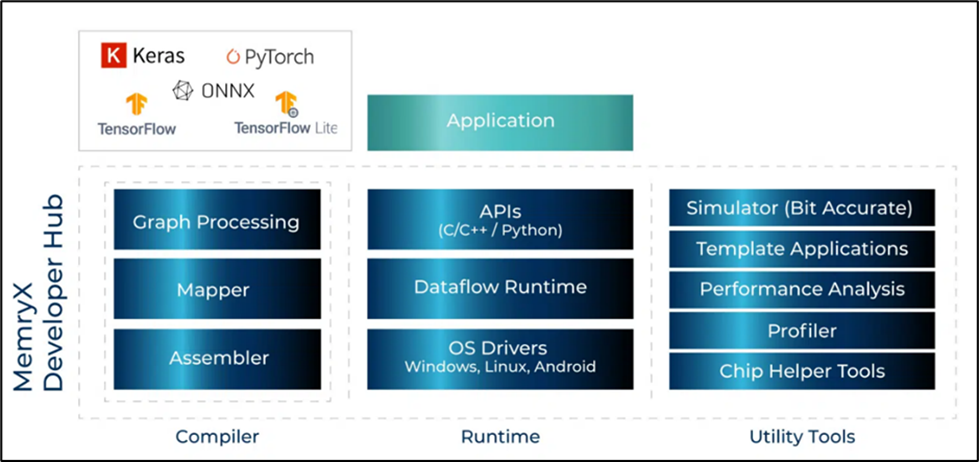
图4 MemryX 开发环境示意图
▼ 编译器(Compiler)
神经编译器提供多种功能,如多模型整合(Multi-Model)、模型剪枝(Model Cropping)、多路流输入单一应用(Multiple Input Streams)、单路流输入多个应用(Shared Input Stream)、混合精度权重(Mixed-Precision Weights)、模块资源使用情况显示(Resources Utilization)。通过简单的命令行指令,能够帮助开发者。快速转换模块将 Pytorch、Keras、Tensorflow、Tensorflow Lite、ONNX 等模型转换为 MemryX DFP 模组格式。
▼ 运行时(Runtime)
提供优化的用户体验,利用 Benchmark 搭配模型库能够帮助开发者快速评估其硬件性能与准确度,并且提供多种开源示例 DEMO (MemryX_Example) 与简洁有力的 API 能够帮助开发者快速实现与部署AI应用。
加速器 API(Python,C/C++)
▼ 公用工具(Utility Tools)
模拟器 (Simulator):为 MemryX 提供一套软件,以解决手头没有 MX3 芯片的开发者进行性能评估的问题。
可视化工具(Viewer):为 MemryX 提供的 GUI 界面,包含上述编译器、模拟器、加速器。
检查器(DFP Inspect):为 MemryX 提供的一套检查 DFP 文件的工具。
如下图所示,展示了更多实际的应用,如物体检测、语义分割、车辆识别、深度估算、肢体识别、虚拟画笔、人脸识别、车牌识别、表情检测、围栏警示等。都可以通过你的想象力与创造力,开发出更具潜力的杀手级应用!这里还提供了实际应用数据,大多数应用都能轻松达到每秒 30 帧以上的推理速度!并主打浮点数运算 (BF16),确保模型的准确性!潜力无限!
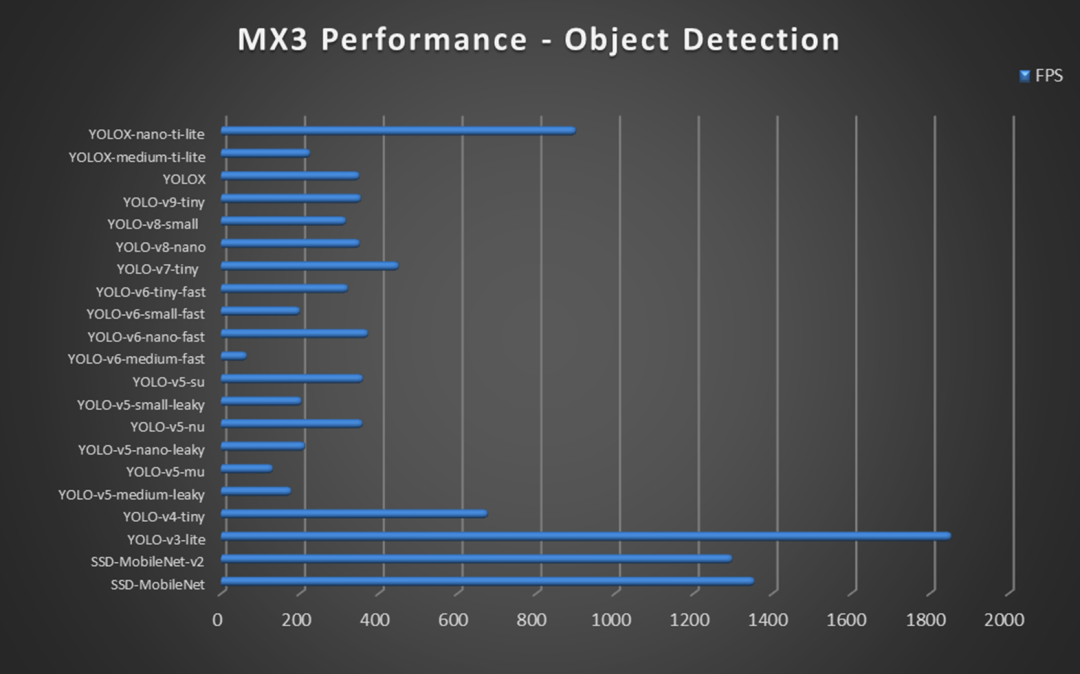
图6 MemryX M3+ 芯片性能数据表
?场景应用图
?展示板照片

?方案方块图
?核心技术优势
◆ 采用浮点数 BF16 进行计算,确保模块准确度:
模块设计以 BF16(Brain Floating Point 16)为基础进行运算,相较于传统的浮点数格式,BF16 能够在大幅减少内存使用量的同时,仍然提供接近 FP32 的计算准确度。这使其特别适合用于人工智能和深度学习模型的推理与训练场景,确保结果的精确性。
◆ 不占用系统内存:
模块运行时采用了独立内存的架构,无需占用主系统的 RAM 资源,有效降低对系统整体性能的影响。这种设计特性确保模块在高效运行的同时,仍然能为其他应用程序预留足够的系统资源。
◆ 高度可扩展性:
支持连接多达 16 个模块,通过模块化设计实现高扩展性。这使得系统能够根据需求灵活扩展计算能力,以应对不同场景的计算需求,例如需要更高性能的数据中心或边缘计算。
◆ 最佳数据流优化,最大限度减少数据移动:
模块内部针对数据流进行了高度优化设计,通过智能路由和缓存机制,能够最大程度地减少数据在运行过程中的移动频率,从而提升处理性能并降低延迟。此外,这样的设计也有助于降低能耗,进一步增强系统的运行效率。
◆ 高性价比与低功耗解决方案:
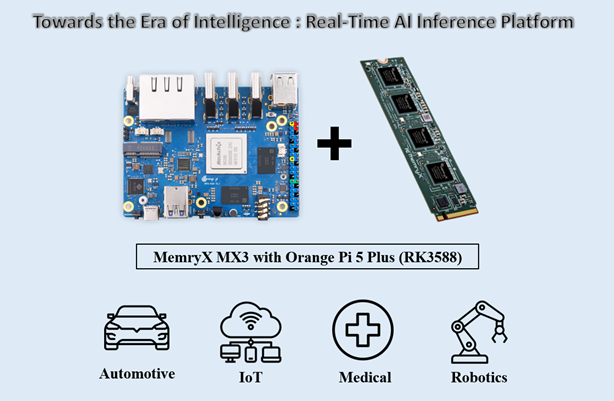
将主平台 Orange Pi 5 Plus 搭配 MemryX MX+ 的 AI 芯片,即可无痛升级为更高阶的 AI 平台,每秒能够运行约 480 帧(YOLOv8)的物体检测;且 MX3+ 拥有 5 TOPS/W 的性能表现,整套多路物体检测解决方案仅耗电约 14 W。
◆ 多路应用的新概念:
相较于近年来兴起的边缘计算,将其概念套用到区域性场景或许是一个新颖且能够大幅降低成本的解决方案。利用轻松易得的摄像头,再搭配一台智能工业主机,即可实现许多应用,并且能够对前端的摄像头进行任意更换与配置。
?方案规格
◆ 主平台开发板采用 RockChip RK3588 平台为基础,搭载四颗 Cortex-A76 处理器与四颗 Cortex-A55 处理器,并提供高性能图像处理器 Arm Mali-G610 与神经运算处理器 NPU 等强大核心架构。
◆ I/O Board 开发板提供强大的周边配置,如 Gigabit Ethernet 千兆以太网、USB Type A/C 3.0 通用串行总线接口、HDMI 高清多媒体接口、M.2 E-Key 传输接口、M.2 M-Key 传输接口,并能够通过扩展的 40 pin 针脚来模拟常用的 UART、I2C、SPI、CAN 等信号。
◆ MemryX MX3+ 芯片提供强大的 AI 运算能力(20 TOPS),以 PCIe Gen3 M.2 2280 M-Key 接口为主,其 M.2 加速卡搭载四颗 MX3+ 芯片,每颗芯片能够提供 5 TOPS/W 的性能,并内置 10.5 MB 的静态随机存取存储器用于存取模块。支持 Linux 与 Windows 两大操作系统,并提供丰富的软件资源供开发者使用,能够直接移植 Tensorflow、ONNX、Pytorch、Keras 等热门的深度学习框架。
本文作者 大大通博主:ATU 伊布小编 (一部)
了解MPU技术整合、深度学习、电脑视觉技术与人工智能(AI)的发展等更多相关内容!
登录大大通网站,向作者提问,下载方案技术文档,了解更多资讯!
-
Rockchip
+关注
关注
0文章
80浏览量
19141 -
NPU
+关注
关注
2文章
333浏览量
19807
发布评论请先 登录
如何用AI实现电池寿命的精准预测?飞凌RK3588+融合算法给你答案

RK3576 vs RK3588:为何越来越多的开发者转向RK3576?
轻松上手边缘AI:MemryX MX3+结合Orange Pi 5 Plus的C/C++实战指南


边缘AI运算革新 DeepX DX-M1 AI加速卡结合Rockchip RK3588多路物体检测解决方案

6TOPS算力NPU加持!RK3588如何重塑8K显示的边缘计算新边界
RK3588核心板在边缘AI计算中的颠覆性优势与场景落地
《RK3588核心板:AIoT边缘计算的革命性引擎,能否解锁智能物联新范式?》
有奖直播 | @4/8 轻松部署,强大扩展边缘运算 AI 新世代






 工商网监
工商网监
评论