 后摩智能5篇论文入选国际顶会
后摩智能5篇论文入选国际顶会

2025年伊始,后摩智能在三大国际顶会(AAAI、ICLR、DAC)中斩获佳绩,共有5篇论文被收录,覆盖大语言模型(LLM)推理优化、模型量化、硬件加速等前沿方向。
AAAI作为人工智能领域的综合性顶级会议,聚焦AI基础理论与应用创新;ICLR作为深度学习领域的权威会议,专注于表示学习、神经网络架构和优化方法等基础技术;DAC则是电子设计自动化(EDA)领域最重要的国际学术会议之一,涵盖半导体设计、计算机体系结构、硬件加速、芯片设计自动化、低功耗计算、可重构计算以及AI在芯片设计中的应用等方向。以下为后摩智能本年度入选论文概述:
01【AAAI-2025】Pushing the Limits of BFP on Narrow Precision LLM Inference
?论文链接:https://arxiv.org/abs/2502.00026
大语言模型(LLMs)在计算和内存方面的巨大需求阻碍了它们的部署。块浮点(BFP)已被证明在加速线性运算(LLM 工作负载的核心)方面非常有效。然而,随着序列长度的增长,非线性运算(如注意力机制)由于其二次计算复杂度,逐渐成为性能瓶颈。这些非线性运算主要依赖低效的浮点格式,导致软件优化困难和硬件开销较高。
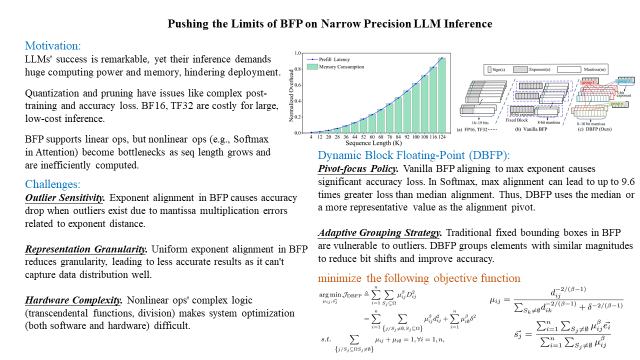
在本论文中,我们深入研究了BFP在非线性运算中的局限性和潜力。基于研究结果,我们提出了一种软硬件协同设计框架(DB-Attn),其中包括:
DBFP:一种先进的 BFP 变体,采用枢轴聚焦策略(pivot-focus strategy)以适应不同数据分布,并采用自适应分组策略(adaptive grouping strategy)以实现灵活的指数共享,从而克服非线性运算的挑战。
DH-LUT:一种创新的查找表(LUT)算法,专门用于基于 DBFP 格式加速非线性运算。
基于DBFP的硬件引擎:我们实现了一个RTL级的DBFP 计算引擎,支持FPGA和ASIC部署。
实验结果表明,DB-Attn在LLaMA的Softmax运算上实现了 74%的GPU加速,并在与SOTA设计相比,计算开销降低10 倍,同时保持了可忽略的精度损失。
02【ICLR-2025】OSTQuant: Refining Large Language Model Quantization with Orthogonal and Scaling Transformations for Better Distribution Fitting
?论文链接:https://arxiv.org/abs/2501.13987
后训练量化(Post-Training Quantization, PTQ)已成为广泛采用的技术,用于压缩和加速大语言模型(LLMs)。LLM量化的主要挑战在于,数据分布的不均衡性和重尾特性会扩大量化范围,从而减少大多数值的比特精度。近年来,一些方法尝试通过线性变换来消异常值并平衡通道间差异,但这些方法仍然具有启发性,往往忽略了对整个量化空间内数据分布的优化。

在本文中,我们引入了一种新的量化评估指标——量化空间利用率(QSUR, Quantization Space Utilization Rate),该指标通过衡量数据在量化空间中的利用情况,有效评估数据的量化能力。同时,我们通过数学推导分析了各种变换的影响及其局限性,为优化量化方法提供了理论指导,并提出了基于正交和缩放变换的量化方法(OSTQuant)。
OSTQuant 采用 可学习的等效变换,包括正交变换和缩放变换,以优化权重和激活值在整个量化空间中的分布。此外,我们提出了KL-Top损失函数,该方法在优化过程中减少噪声,同时在 PTQ 限制的校准数据下保留更多语义信息。
实验结果表明,OSTQuant在各种 LLM 和基准测试上均优于现有方法。在W4-only 量化设置下,它保留了99.5%的浮点精度。在更具挑战性的W4A4KV4量化配置中,OSTQuant在 LLaMA-3-8B 模型上的性能差距相比SOTA方法减少了32%。
03【ICLR-2025】MambaQuant:Quantizing the Mamba Family with Variance Aligned Rotation Methods
?论文链接:https://arxiv.org/abs/2501.13484
Mamba是一种高效的序列模型,其性能可与Transformer相媲美,并在各种任务中展现出作为基础架构的巨大潜力。量化(Quantization)通常用于神经网络,以减少模型大小并降低计算延迟。然而,对于Mamba进行量化的研究仍然较少,而现有的量化方法——尽管在CNN和Transformer模型上表现良好——在Mamba模型上的效果却不理想(例如,即使在W8A8 设置下,Quarot 在Vim-T?上的准确率仍下降了 21%)。
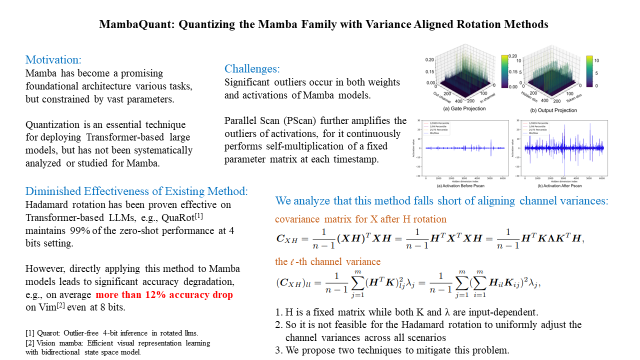
我们率先对这一问题进行了深入研究,并识别出了几个关键挑战。首先,在门控投影(gate projections)、输出投影(output projections)和矩阵乘法(matrix multiplications)中存在显著的异常值(outliers)。其次,Mamba 独特的并行扫描(Parallel Scan, PScan)进一步放大了这些异常值,导致数据分布不均衡且具有重尾特性(heavy-tailed distributions)。第三,即便应用 Hadamard 变换,不同通道中的权重和激活值的方差仍然不一致。
为了解决这些问题,我们提出了MambaQuant,一个后训练量化(PTQ)框架,其中包括:
KLT 增强旋转(Karhunen-Loeve Transformation, KLT-Enhanced Rotation):将 Hadamard 变换与 KLT 结合,使得旋转矩阵能够适应不同通道分布。
平滑融合旋转(Smooth-Fused Rotation):均衡通道方差,并可将额外参数合并到模型权重中。
实验表明,MambaQuant 能够在Mamba视觉和语言任务中将权重和激活量化至8-bit,且准确率损失低于1%。据我们所知,MambaQuant是首个专门针对 Mamba家族的全面PTQ方案,为其未来的应用和优化奠定了基础。
04【DAC-2025】BBAL: A Bidirectional Block Floating Point-Based Quantisation Accelerator for Large Language Models
大语言模型(LLMs)由于其包含数十亿参数,在部署于边缘设备时面临内存容量和计算资源的巨大挑战。块浮点(BFP)量化通过将高开销的浮点运算转换为低比特的定点运算,从而减少内存和计算开销。然而,BFP需要将所有数据对齐到最大指数(max exponent),这会导致小值和中等值的丢失,从而引入量化误差,导致LLMs 的精度下降。
为了解决这一问题,我们提出了一种双向块浮点(BBFP, Bidirectional Block Floating-Point)数据格式,该格式降低了选择最大指数作为共享指数的概率,从而减少量化误差。利用 BBFP 的特性,我们进一步提出了一种基于双向块浮点的量化加速器(BBAL),它主要包括一个基于BBFP 的处理单元(PE)阵列,并配备我们提出的高效非线性计算单元。

实验结果表明,与基于异常值感知(outlier-aware)的加速器相比,BBAL在相似计算效率下,精度提升22%;同时,与传统BFP量化加速器相比,BBAL在相似精度下计算效率提升 40%。
05【DAC-2025】NVR: Vector Runahead on NPUs for Sparse Memory Access
深度神经网络(DNNs)越来越多地利用稀疏性来减少模型参数规模的扩展。然而,通过稀疏性和剪枝来减少实际运行时间仍然面临挑战,因为不规则的内存访问模式会导致频繁的缓存未命中(cache misses)。在本文中,我们提出了一种专门针对NPU(神经处理单元)设计的预取机制——NPU向量超前执行(NVR, NPU Vector Runahead),用于解决稀疏DNN任务中的缓存未命中问题。与那些通过高开销优化内存访问模式但可移植性较差的方法不同,NVR 采用超前执行(runahead execution),并针对NPU 架构的特点进行适配。

NVR 提供了一种通用的微架构级解决方案,能够无需编译器或算法支持地优化稀疏DNN任务。它以分离、推测性(speculative)、轻量级的硬件子线程的形式运行,并行于 NPU,且额外的硬件开销低于5%。
实验结果表明,NVR 将L2缓存未命中率降低了90%(相比最先进的通用处理器预取机制),并在稀疏任务上使NPU计算速度提升4倍(与无预取 NPU 相比)。此外,我们还研究了在NPU 中结合小型缓存(16KB)与NVR预取的优势。我们的评估表明,增加这一小型缓存的性能提升效果比等量扩展L2缓存高5倍。
这5篇论文聚焦于大语言模型的优化、量化和硬件加速等关键技术,从算法创新到硬件适配,系统性地展现了后摩智能在AI软硬件协同领域的深厚积累。研究成果从计算效率、能效优化和部署灵活性等多个维度,突破了大模型高效部署的技术瓶颈,为边缘计算场景下的大模型压缩与加速提供了创新性解决方案。期待这些工作能够为大模型在端边侧的高效部署提供新范式,推动通用智能向更普惠、更可持续的方向演进。
接下来,我们将对5篇论文展开深度解析,详细探讨每篇论文的技术细节、创新点等,敬请关注。
-
芯片
+关注
关注
460文章
52616浏览量
442663 -
计算机
+关注
关注
19文章
7679浏览量
90987 -
AI
+关注
关注
88文章
35476浏览量
281261 -
后摩智能
+关注
关注
0文章
38浏览量
1395
原文标题:后摩前沿 | AAAI+ICLR+DAC,后摩智能5篇论文入选国际顶会
文章出处:【微信号:后摩智能,微信公众号:后摩智能】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
存算一体技术加持!后摩智能 160TOPS 端边大模型AI芯片正式发布








 工商网监
工商网监
评论