 大语言模型的解码策略与关键优化总结
大语言模型的解码策略与关键优化总结

本文系统性地阐述了大型语言模型(Large Language Models, LLMs)中的解码策略技术原理及其实践应用。通过深入分析各类解码算法的工作机制、性能特征和优化方法,为研究者和工程师提供了全面的技术参考。主要涵盖贪婪解码、束搜索、采样技术等核心解码方法,以及温度参数、惩罚机制等关键优化手段。
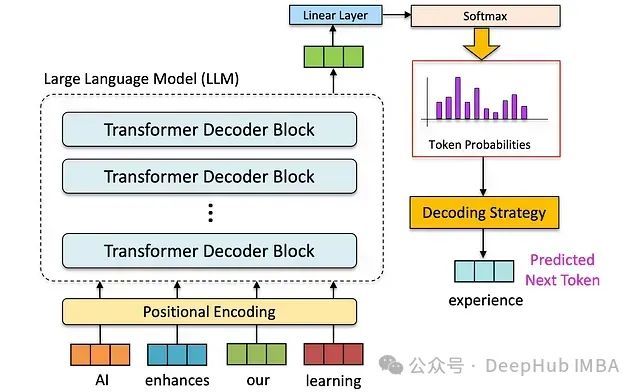
大型语言模型的技术基础
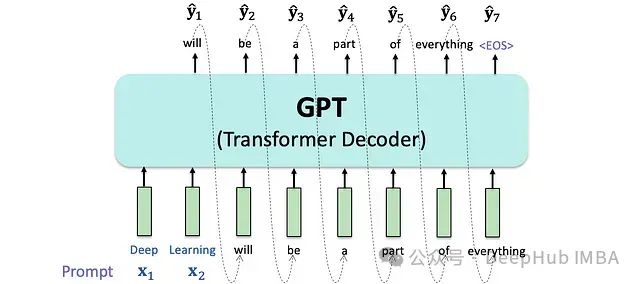
大型语言模型是当代自然语言处理技术的核心支柱,其基础架构建立在自回归语言建模的理论基础之上。模型通过序列条件概率建模,实现对下一个可能token的精确预测。
大型语言模型的自回归特性体现为基于已知序列进行逐token概率预测的过程。在每个时间步,模型基于已生成序列计算下一个token的条件概率分布。
从形式化角度,该过程可表述为条件概率的连乘形式:
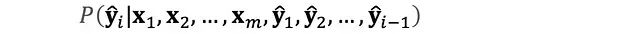
此自回归机制确保了模型能够保持上下文的语义连贯性,并在此基础上构建完整的输出序列。
解码策略是将模型输出的概率分布转化为具体文本序列的关键技术环节。不同解码策略的选择直接影响生成文本的多个质量维度,包括语义连贯性、表达多样性和逻辑准确性。以下将详细分析各类主流解码策略的技术特点。
贪婪解码策略分析
贪婪解码采用确定性方法,在每个时间步选择概率最高的候选token。
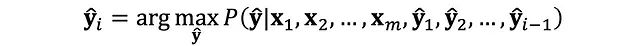

技术特性分析:
计算效率:实现简单,计算开销小,适用于对响应时间要求较高的场景
局限性:容易陷入局部最优解,生成文本存在重复性问题
实例:
输入序列:"My favorite color is" 贪婪解码输出:"My favorite color is blue blue blue blue is blue and blue is my favorite color blue"
束搜索技术原理
束搜索通过并行维护多个候选序列来优化解码过程。其中束宽度参数k决定了并行探索路径的数量,直接影响输出质量与计算资源的平衡。
束搜索实现机制
初始化阶段:从概率最高的初始token序列开始
迭代拓展:为每个候选序列计算并附加top-k个最可能的后续token
评分筛选:基于累积概率为新序列评分,保留得分最高的k个序列
终止判断:直至达到最大序列长度或生成结束标志
以生成"the cat sat on the mat"为例(k=2)进行技术分析:
初始候选序列:"the"和"a",基于每个候选计算下一步最可能的两个token
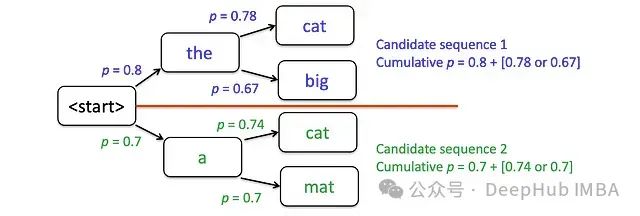
每轮迭代后保留两个最优得分序列(例如保留"the cat"和"a cat",舍弃"the big"和"a mat")
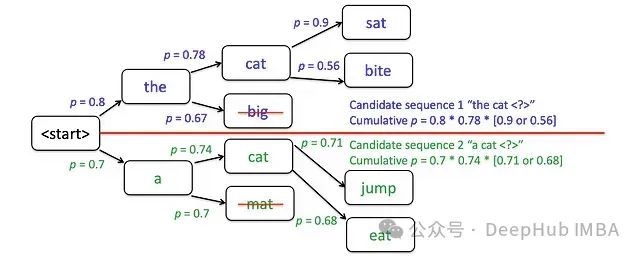
迭代过程中的概率优化选择:"the cat"作为首选序列,"a cat"作为次优序列。顶部候选项的累积概率更高时,将作为后续迭代的基准序列。
技术特性分析:
优势:在探索与利用间实现平衡,相比贪婪解码产生更多样化且连贯的文本
局限:计算成本随束宽k增加而显著上升,且仍可能出现重复性问题
束搜索输出示例(k=3):
输入:"My favorite color is" 输出序列1:"My favorite color is blue because blue is a great color" 输出序列2:"My favorite color is blue, and I love blue clothes" 输出序列3:"My favorite color is blue, blue is just the best"
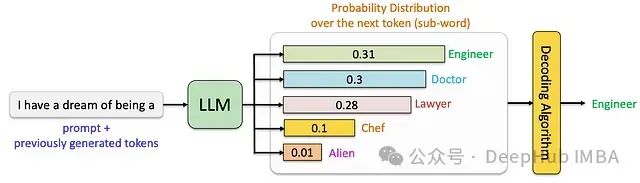
基于采样的解码技术
随机采样基础原理
自然语言具有内在的多样性分布特征,这与传统确定性解码方法产生的单一输出形成鲜明对比。基于采样的解码技术通过概率分布采样来实现更贴近人类表达特征的文本生成。
随机采样是最基础的采样类解码方法,其核心机制是直接从模型输出的概率分布中进行随机选择。

这种简单的随机采样存在明显的技术缺陷:在概率分布的长尾区域(即大量低概率token的聚集区域),模型的预测质量普遍较低。这种现象会导致生成的文本出现语法错误或语义不连贯的问题。
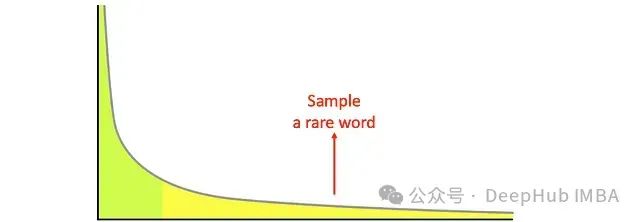
Top-k采样技术实现
为了克服纯随机采样的局限性,Top-k采样通过限定采样空间来优化生成质量。在每个时间步t,系统仅从概率最高的k个token中进行随机采样。
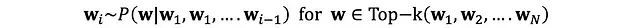
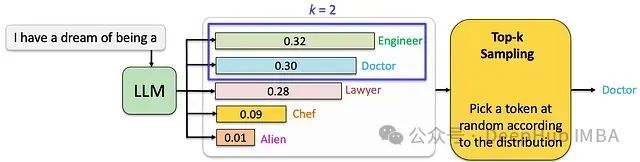
技术特性分析:
优化效果:通过引入受控随机性,在保持文本多样性的同时提升生成质量
参数敏感性:k值的选择对生成效果有显著影响,需要根据具体应用场景进行优化调整
计算效率:相比束搜索,具有较好的效率和资源利用率
核采样技术
核采样(Nucleus Sampling,又称Top-p采样)是一种动态调整采样空间的高级解码技术。其核心思想是仅从累积概率达到阈值p的最小token集合中进行采样,从而实现采样空间的自适应调整。
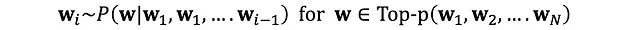

核采样技术优势
动态采样空间:根据概率分布特征自适应调整候选token数量
平衡性能:在文本流畅性和创造性之间达到较好的平衡
自适应特性:能够根据不同语境自动调整生成策略
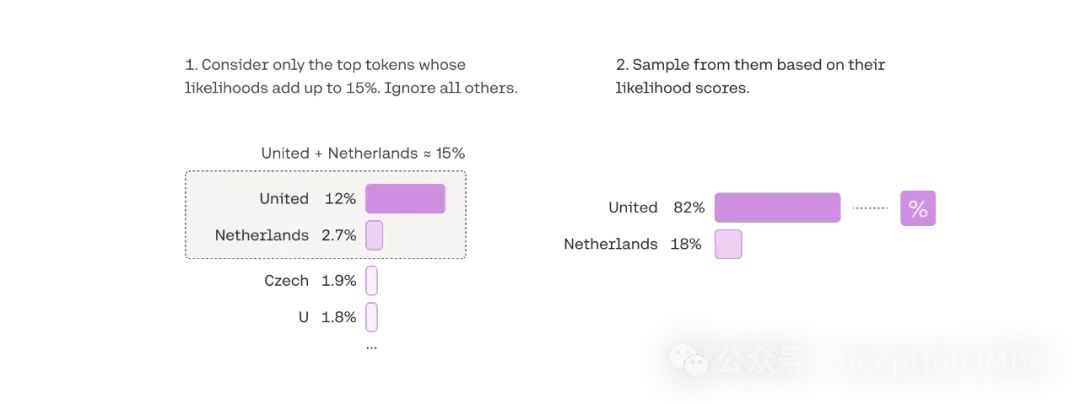
参数配置分析
核采样的效果高度依赖于阈值p的选择:
p = 0.9:采样空间收窄,生成文本倾向于保守,适合需要高准确性的场景
p = 0.5:采样空间适中,在创造性和准确性之间取得平衡
p = 1.0:等同于完全随机采样,适用于需要最大创造性的场景
技术局限性:核采样在计算资源需求上可能高于Top-k采样,且参数调优需要较多经验积累。
温度参数原理
温度参数(T)是一个核心的概率分布调节机制,通过调整logits的分布来影响token的选择概率。其数学表达式为:
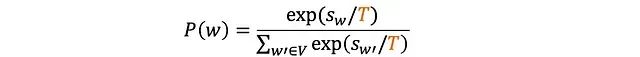
温度参数
T = 1.0:保持原始概率分布特征
T > 1.0:增加分布的熵,提升采样多样性
0 < T < 1.0:降低分布的熵,增强确定性
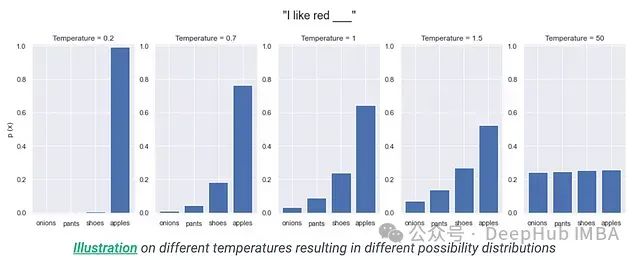
温度参数可与各类解码策略结合使用,通过调节概率分布的"陡峭程度"来实现对生成文本特征的精细控制。需要注意的是这是一种预处理机制,而非独立的解码算法。
ChatGPT解码策略实践分析
ChatGPT的解码机制集成了多种先进技术,通过参数组合实现灵活的文本生成控制。
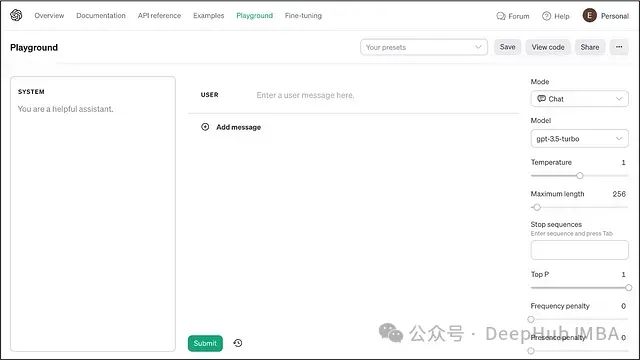
核心参数配置
温度调节机制
- 低温度配置(T≈0.2):用于需要确定性强的场景
高温度配置(T≈0.8):适用于创意生成任务
核采样实现
动态调整采样空间
自适应平衡生成质量
惩罚机制
- 频率惩罚:抑制词语重复使用
存在惩罚:促进词汇多样性
技术优化策略
参数协同调优
- 场景适应性配置
实时性能监控
总结
解码策略在利用 LLM 的力量来生成高质量、连贯和多样化的文本方面发挥着关键作用。从贪婪解码的简单性到 核采样的复杂性,各种解码算法在连贯性和多样性之间提供了微妙的平衡。每种算法都有其优点和缺点,理解它们的细微差别对于优化 LLM 在各种应用中的性能至关重要。
贪婪解码:一种直接的方法,它在每个步骤选择最可能的词,通常导致连贯但多样性较差的文本。
束搜索:贪婪解码的扩展,它考虑了多个可能的序列,从而产生更多样化和连贯的文本。
Top-k:此参数控制模型生成的输出的多样性。Top-K 的值为 5 意味着仅考虑最可能的 5 个词,这可以提高生成的文本的流畅性并减少重复。
Top-p (Nucleus 采样):此参数控制模型生成的输出的多样性。值为 0.8 意味着仅考虑最可能的词的 top 80%,这可以提高生成的文本的流畅性并减少重复。
温度:此超参数控制 LLM 输出的随机性。较低的温度(例如 0.7)有利于更确定和较少多样化的输出,而较高的温度(例如 1.05)可能导致更多样化的输出,但也可能引入更多错误。
频率惩罚:这种技术通过对生成文本中频繁使用的词施加惩罚来阻止重复,从而减少冗余并鼓励使用更广泛的词。它有助于防止模型生成重复文本或陷入循环。
重复惩罚:一个参数,用于控制生成文本中重复的可能性,确保更多样化和引人入胜的响应。
理解和选择适当的解码算法对于优化 LLM 在各种应用中的性能至关重要。随着该领域的研究不断发展,可能会出现新的解码技术,从而进一步增强 LLM 在生成类人文本方面的能力。通过利用高级解码算法,像 ChatGPT 这样的平台可以产生连贯、引人入胜和多样化的响应,使与 AI 的交互更加自然和有效。
作者:LM Po
本文来源:DeepHub IMBA
-
语言模型
+关注
关注
0文章
563浏览量
10839 -
解码技术
+关注
关注
0文章
8浏览量
10360 -
LLM
+关注
关注
1文章
328浏览量
890
发布评论请先 登录





 工商网监
工商网监
评论